Warum automatisierte Videos?
Was hat es mit den Videos auf sich?
Und warum enthalten sie fast dieselben Inhalte wie das gedruckte Material?
Sie haben wahrscheinlich bereits bemerkt, dass die Vorträge und Videos für
diesen Kurs anders strukturiert sind als in von Ihnen abgeschlossenen MOOCS.
Dieses Video soll erklären, warum wir diese Änderung vorgenommen haben und
sie unserer Meinung nach die Macht von R und Data Science zeigt.
Wir erstellen viele sehr große offene Onlinekurse im Johns Hopkins Data Science Lab
und haben in den letzten 5 Jahren über 30 Kurse auf mehreren Plattformen entwickelt.
Unser Ziel dabei ist,
dem größtmöglichen Publikum die besten und aktuellsten Informationen bereitzustellen.
Aber die Onlineverwaltung von so viel Material bringt erhebliche Herausforderungen mit sich.
R-Pakete veralten,
neue Workflows werden entwickelt und überall finden sich Fehler.
Wir erstellen diese Kurse wie viele andere Unis.
In Form von Vortragsfolien.
Dann zeichnen wir Videos dieser Vorträge auf.
Einerseits war das toll,
weil Sie unsere Stimmen, inklusive
Gähnen usw., gehört haben.
Andererseits war die Aktualisierung von
Inhalten schwierig und zeitaufwändig,
da wir ein Aufnahmestudio buchen,
eine spezielle Ausrüstung aufbauen,
uns bei einem Vortrag aufnehmen,
die Vorträge bearbeiten und sie in ein System hochladen mussten.
Das Ergebnis: Viele Vorträge waren veraltet und enthielten
Fehler oder nicht die aktuellen <br /> besten Versionen von Workflows und Pipelines.
Das war eine Weile ein Problem,
aber da die Anzahl der angebotenen Kurse stetig zunimmt,
stellt die Aktualisierung zunehmend eine Herausforderung dar.
Komplette Websites wurden eingerichtet, um Probleme mit den Kursen zu überwachen.
Wir haben uns also überlegt, wie wir diese Herausforderung bewältigen können.
Während die Aufzeichnung und Bearbeitung von Videos
extrem zeitaufwändig ist,
gibt es einen anderen Inhaltstyp, den wir viel häufiger bearbeiten
aktualisieren und pflegen können:
die guten alten Textdokumente.
Wir sind nicht die einzigen, denen das aufgefallen ist.
Vordenker*innen wie Lorena Barba
sind der Meinung, dass Videos für unsere Art von Kursen nicht notwendig sind.
Bei der Entwicklung des neuen Prozesses zur Erstellung und Pflege von Kursen
wollten wir einen
Classmate komplett aus Textdokumenten erstellen.
Wir teilten einen sehr großen offenen Online-Kurs in seine Basiselemente auf.
Tutorials lassen sich einfach in Textformaten wie Markdown oder R Markdown erstellen.
Folien können problemlos gepflegt und geteilt werden,
wenn wir sie z. B. mit Google Slides erstellen.
Für Quiz und andere Prüfungen ist eine Markup-Sprache verwendbar.
Schließlich Videos.
Diese waren der Knackpunkt.
Wie erstellen wir Videos aus Textdokumenten?
Wie der Zufall so will,
löste die Data Science/ Artifical Intelligence Community
einen großen Teil dieses Problems durch Verbesserung der Sprachsynthese.
Jetzt können wir ein Videoskript schreiben und mit Amazon Polly Stimmen synthetisieren.
Um von der neuen Technologie zu profitieren,
erstellten wir 2 neue R-Pakete, Ari und Detector.
Ari verwendet ein Skript und einen Satz Google-Folien und wendet
das Skript mit Amazon Polly auf die Folien an.
Es generiert auch die Untertitel-Datei,
sodass Videos z. B. für Hörgeschädigte zugänglich sind.
Detector automatisiert verschiedene Schritte von der Video-Erstellung mit Ari
bis zum Upload in YouTube, sodass schnell Bearbeitungen an Skripts/Folien möglich sind.
Wir erstellen die Videos, wir laden sie hoch und wir
pflegen sie, um sie aktuell zu halten.
Wenn wir Textdateien ändern oder Folien bearbeiten,
können wir das Video in wenigen Minuten neu erstellen.
Der Wechsel zu diesem neuen Prozess ist auch deshalb so spannend,
weil wir zeigen können, welche Möglichkeiten die Programmierung von Sprachen bietet.
Das ist die Hauptsprache, die Sie im Programm lernen. Wir hoffen, Sie können
nach den Kursen coole Dinge wie dieses System entwickeln.
Warum haben wir diesen Ansatz gewählt, statt jeden Lektionsteil separat zu erstellen?
Erstens vereinfacht er die Pflege und Aktualisierung der Kurse.
Wenn in einer Lektion ein Problem gemeldet oder ein Fehler gefunden wird,
müssen wir nur das Skript oder die
Google-Folien ändern und die Kurse neu erstellen.
Daher können wir die Kursinhalte
effizienter pflegen und aktualisieren.
Zweitens sind Anweisungen zugänglicher.
Da Videos Transkripts und Transkripts Begleitkommentare haben,
ist der Inhalt auch für Personen mit Beeinträchtigungen zugänglich.
Für alle anderen besteht die Möglichkeit, den Inhalt zu lesen,
ihn anzuhören oder anzusehen.
Drittens ist ein tolles Feature der Sprachsynthese, dass
die Videos aufgrund der Optimierung der Synthese-Software immer besser werden.
Das bedeutet, dass wir die Stimme in unterschiedliche Stimmen ändern können.
Schließlich können wir die Kurse schnell und automatisch
dank maschinellem Lernen in verschiedene Sprachen übersetzen.
Dies zeigt die unglaubliche Macht
von Data Science/künstlicher Intelligenz, die Welt besser zu machen.
Wenn die Roboterstimme Sie nervt, können wir das nachvollziehen.
Wir wissen, dass die Technologie noch nicht perfekt ist.
Daher spiegelt das schriftliche Vortragsmaterial
so gut wie möglich die Videovorträge wider.
Sie können wählen, wie Sie unsere Kurse durchführen.
Wir hoffen, dass wir Ihnen durch diese Änderung
schnellstmöglich die besten Inhalte bereitstellen können.
Danke, dass Sie Teil dieser neuen Phase der Kursentwicklung sind.
Was ist Data Science?
Hallo und willkommen bei The Data Scientist’s Toolbox,
dem ersten Kurs der Data Science- Spezialisierungsreihe.
Wir behandeln die Data Science- Grundlagen und
stellen Tools vor, die wir verwenden.
Die 1. Frage, die Sie sich stellen, ist wahrscheinlich:
Was ist Data Science?
Das ist eine gute Frage.
Es gibt verschiedene Antworten,
aber im Kern nutzt Data Science Daten zur Beantwortung von Fragen.
Das ist eine weitgefasste Definition, weil es ein weitgefasster Bereich ist.
Data Science kann Statistik, Informatik,
Mathematik, Datenbereinigung/-formatierung sowie Datenvisualisierung umfassen.
Ein The Economist-Spezialbericht fasst diese Kombination aus Fähigkeiten gut zusammen.
Er besagt, dass ein Data Scientist i. A. als jemand
definiert ist, der über die Fähigkeiten eines Softwareprogrammierers,
Statistikers und Erzählers/ Künstlers verfügt, um
wichtige Inhalte aus großen Datenmengen zu extrahieren.
Am Ende dieser Kurse
fühlen Sie sich hoffentlich dazu in der Lage.
Einer der Gründe für den Aufstieg von Data Science in den letzten Jahren
ist die große Menge an Daten, die aktuell verfügbar ist und generiert wird.
Es werden nicht nur massive Mengen an Daten aus
vielen verschiedenen Bereichen erfasst,
sondern gleichzeitig wird die Datenverarbeitung auch immer günstiger.
Dies sorgt für ein Szenario, in dem wir Daten und Analysetools anreichern,
wobei mehr Computerarbeitsspeicher,
bessere Prozessoren, zusätzliche Software und nun
mehr Data Scientists zum
Nutzen dieser Daten/Tools und Beantworten von Fragen erforderlich sind.
Hier eine Anekdote, die das
exponentielle Wachstum der aktuellen Datengenerierung beschreibt.
Im dritten Jahrhundert v. Chr.
galt die Bibliothek von Alexandria als Zentrum des menschlichen Wissens.
Heute steht das 320-Fache an
Informationen zur Verfügung.
Und das ist auch noch nicht das Ende.
In einem späteren Vortrag sprechen wir ausführlicher über Big Data.
Wir wollten das aber hier erwähnen,
weil es so wichtig für den Aufstieg von Data Science ist.
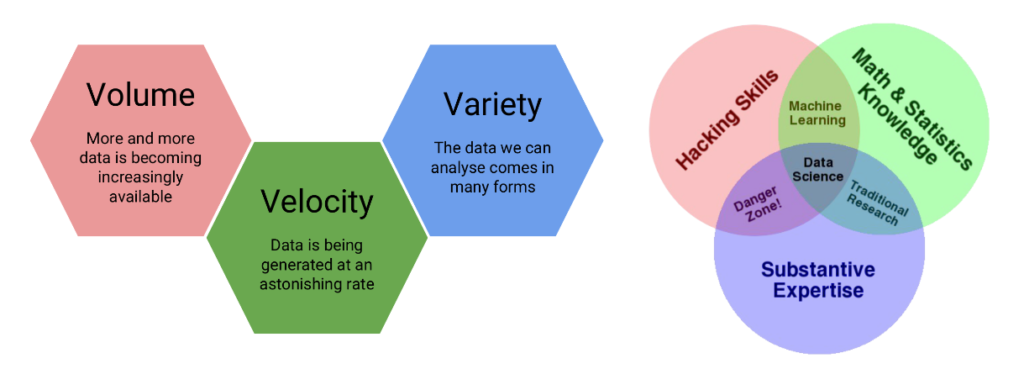
Big Data haben einige Merkmale.
Das erste Merkmal ist der Umfang.
Wie der Name schon sagt,
beinhalten Big Data große Datensätze.
Diese großen Datensätze werden mehr und mehr Routine.
Angenommen, Sie haben eine Frage zu Onlinevideos.
In YouTube werden jede Minute ca. 300 Stunden Videomaterial hochgeladen.
Sie könnten definitiv viele Daten analysieren.
Aber das wäre evtl. auch ein Problem.
Das führt uns zum 2. Merkmal von Big Data: Geschwindigkeit.
Daten werden schneller als je zuvor generiert und erfasst.
In unserem YouTube-Beispiel
stehen Ihnen minütlich neue Daten zur Verfügung.
Noch ein anderes Beispiel:
Angenommen, Sie haben eine Frage zu Transportzeiten.
Die meisten LKW stellen GPS-Daten in Echtzeit bereit.
Sie könnten in Echtzeit die Wege der
LKW analysieren, mit den entsprechenden Tools und Fähigkeiten.
Das dritte Merkmal von Big Data ist Vielfalt.
In den bisher genannten Beispielen
sind verschiedene Daten- typen verfügbar.
Im YouTube-Beispiel
könnten Sie Video- oder Audiomaterial analysieren,
ein sehr unstrukturierter Datensatz,
oder mit einer Datenbank mit Videolängen,
Views oder Kommentaren arbeiten, einem deutlich strukturierten Datensatz für die Analyse.
Wir haben Data Science definiert und die Datentypen behandelt,
aber Sie sollten auch wissen, was genau ein Data Scientist ist.
Hier die einfachste Definition:
Ein Data Scientist verwendet Daten, um Fragen zu beantworten.
Noch wichtiger für Sie:
Welche Fähigkeiten braucht ein Data Scientist?
Dieses anschauliche Venn-Diagramm
zeigt Data Science als Schnittmenge aus
drei Bereichen:
substantielle Expertise, Hacking-Fähigkeiten
und Mathematik/Statistik. Hier eine genauere Erklärung.
Wir wissen, dass Data Science Fragen beantwortet.
Zunächst ist genug Expertise in dem Bereich nötig, zu dem wir eine Frage stellen möchten,
um Fragen zu formulieren und zu wissen, welche Typen von
Daten sich zum Beantworten eignen.
Wenn wir unsere Frage und die entsprechenden Daten haben,
wissen wir welche Typen von Daten sich für Data Science eignen.
Oft müssen sie einer umfassenden Reinigung und Formatierung unterzogen werden.
Dies erfordert in vielen Fällen Computerprogrammierung/Hacking.
Wenn wir unsere Daten haben,
müssen wir sie analysieren.
Dazu ist häufig Mathematik und Statistik nötig.
In dieser Spezialisierung wird es
um jeden dieser 3 Bereiche gehen.
Aber hauptsächlich um Mathematik/ Statistik und Hacking.
Bei Letzterem liegt der Fokus auf 2 Komponenten:
Programmierung oder zumindest
Programmierung mit R, sodass Sie auf Daten zugreifen,
mit ihnen experimentieren, sie analysieren und plotten können.
Zudem erfahren Sie,
wie Sie Antworten auf Programmierfragen erhalten.
Ein Grund für den großen Bedarf an Data Scientists ist,
dass die meisten Antworten noch nicht vorhanden sind.
Ein Data Scientist muss wissen,wie er Antworten auf neue Probleme findet.
Der Bedarf
an Personen mit Data Science-Fähigkeiten ist enorm.
Machine-Learning Engineers, Data Scientists und Big Data Engineers
gehörten 2017 laut LinkedIn zu den gefragtesten Mitarbeitern.
Der Bedarf übersteigt das Angebot bei weitem.
LinkedIn: „Data Scientists-Positionen haben seit 2012 über 650 Prozent zugenommen.
Aktuell verfügen jedoch nur 35.000 Personen in den USA über entsprechende Kenntnisse.
Hunderte Unternehmen haben Stellen ausgeschrieben.
Auch in unerwarteten Sektoren wie Einzelhandel und Finanzen.
Das Angebot an Kandidaten kann nicht mit dem Bedarf mithalten.“
Dies ist ein guter Zeitpunkt, in Data Science einzusteigen.
Es stehen nicht nur mehr und mehr Daten
und Tools für die Erfassung,
Speicherung und Analyse bereit,
sondern der Bedarf an Data Scientists wird
auch in vielen verschiedenen Sektoren als wichtig erkannt,
nicht nur in Wirtschaft und Wissenschaft.
Glassdoor erstellte 2017 eine Rangliste der 50 besten Jobs in den USA.
Data Scientist ist Nummer 1,
basierend auf Zufriedenheit, Gehalt und Bedarf.
Die Vielfalt der Sektoren, in denen Data Science eingesetzt wird,
wird anhand folgender Beispiele von Data Scientists veranschaulicht.
Ein Ort, an dem der Data Science-Bedarf evtl. nicht sofort sichtbar ist: Sport.
Daryl Morey ist General Manager des Basketball-Teams Houston Rockets.
Obwohl er wenig Erfahrung mit Basketball hat,
wurde er aufgrund seines Bachelor-Abschlusses
in Informatik und seines MBA vom MIT eingestellt.
Er wurde wegen seiner Fähigkeit ausgewählt, Daten zu sammeln und zu analysieren
und dies für fundierte Einstellungsentscheidungen zu nutzen.
Vielleicht haben Sie auch schon von Hilary Mason gehört.
Sie ist Mitbegründerin von FastForward Labs,
einem Unternehmen für maschinelles Lernen, das kürzlich von Cloudera übernommen wurde.
Cloudera ist ein Data Science-Unternehmen
und Hilary Data Scientist in Residence bei Accel.
Sie nutzt Daten, um Fragen zum Web Mining zu beantworten und
Social Media- Interaktionen zu verstehen.
Nate Silver ist einer
der bekanntesten Data Scientists oder Statistiker weltweit.
Er ist Gründer und Editor in Chief
bei FiveThirtyEight,
einer Website, die statistische Analysen –
harte Fakten – nutzt, um spannende Geschichten zu Wahlen,
Politik, Sport, Wissenschaft, Wirtschaft und Lifestyle zu erzählen.
Große Mengen an komplett kostenlosen
öffentlichen Daten dienen als Basis für Vorhersagen zu vielen Themen.
Vor allem werden Vorhersagen zu den Wahlen in den USA erstellt,
mit beeindruckender Erfolgsbilanz.
Ein gutes Beispiel für Data Science in Aktion stammt
aus 2009. Forscher bei Google analysierten
50 Millionen häufig gesuchte Begriffe über
5 Jahre und verglichen sie mit CDC-Daten zu Grippewellen.
Ziel war es, herauszufinden, ob Suchanfragen mit Grippewellen zusammenfallen.
Einer der Vorteile von Data Science und
Big Data ist die Identifizierung von Korrelationen.
In diesem Fall identifizierten sie 45 Wörter mit
einer starken Korrelation mit den CDC-Daten zur Grippewelle.
Mit diesen Daten konnten Grippewellen ausschließlich
basierend auf gängigen Google-Suchen vorhergesagt werden.
Ohne diese massiven Datenmengen
hätten diese 45 Wörter nicht vorhergesagt werden können.
Nach dieser Einführung in Data Science
fehlt nur noch eine Zusammenfassung
der Kursinhalte.
Zunächst geht es um die Grundlagen von R.
R ist die Haupt-Programmiersprache in diesem Kurs.
Sie müssen wissen, was R ist,
wie es funktioniert und installiert wird.
Dann wechseln wir zu RStudio, einer grafischen Schnittstelle zu R,
die Ihnen die Arbeit erleichtern wird.
Anschließend sprechen wir über die Versionskontrolle,
warum sie wichtig ist
und wie Sie sie in Ihre Arbeit integrieren.
Wenn Sie mit diesen Grundlagen vertraut sind,
können Sie diese Tools zum Beantworten Ihrer Data Science-Fragen anwenden.
Wir freuen uns auf Sie. Los geht’s.
Was sind Daten?
Da wir einige Zeit damit verbracht haben, darüber zu diskutieren, was Datenwissenschaft ist,
sollten wir einige Zeit damit verbringen, uns anzusehen, was genau Daten sind.
Schauen wir uns zunächst an, was einige vertrauenswürdige Quellen als Daten betrachten.
Zunächst schauen wir uns
das Cambridge English Dictionary an, das besagt, dass Daten Informationen sind,
insbesondere Fakten oder Zahlen, die gesammelt werden, um
untersucht und berücksichtigt und zur Entscheidungsfindung verwendet zu werden.
Zweitens schauen wir uns die Definition von Wikipedia an, bei der es sich um
eine Reihe von Werten qualitativer oder quantitativer Variablen handelt.
Dies sind leicht unterschiedliche Definitionen und
sie beziehen sich auf unterschiedliche Komponenten dessen, was Daten sind.
Beide stimmen darin überein, dass Daten Werte oder Zahlen oder Fakten sind.
Die Cambridge-Definition konzentriert sich jedoch auf die Aktionen, die Daten umgeben.
Daten werden gesammelt, untersucht und vor allem als Grundlage
für Entscheidungen verwendet.
Wir haben uns schon einmal auf diesen Aspekt konzentriert.
Wir haben darüber gesprochen, dass der wichtigste Teil der Datenwissenschaft
die Frage ist und dass wir lediglich Daten verwenden, um die Frage zu beantworten.
Die Cambridge-Definition konzentriert sich darauf.
Die Wikipedia-Definition konzentriert sich mehr darauf, was Daten beinhalten.
Und obwohl es sich um eine ziemlich kurze Definition handelt,
nehmen wir uns eine Sekunde Zeit, um dies zu analysieren und uns auf jede Komponente einzeln zu konzentrieren.
Das erste, worauf Sie sich konzentrieren sollten, ist eine Reihe von Werten.
Um Daten zu erhalten, benötigen Sie eine Reihe von Elementen, anhand derer Sie messen können.
In der Statistik wird diese Gruppe von Elementen häufig als Population bezeichnet.
Das Set als Ganzes ist das, worüber Sie etwas herausfinden möchten.
Das nächste, worauf Sie sich konzentrieren sollten, sind Variablen.
Variablen sind Maße oder Eigenschaften eines Artikels.
Schließlich haben wir sowohl qualitative als auch quantitative Variablen.
Qualitative Variablen sind, wenig überraschend, Informationen über Eigenschaften.
Sie sind Dinge wie Herkunftsland,
Geschlecht oder Behandlungsgruppe.
Sie werden normalerweise mit Worten beschrieben,
nicht mit Zahlen, und sie sind nicht unbedingt geordnet.
Quantitative Variablen
sind dagegen Informationen über Mengen.
Quantitative Messungen werden normalerweise durch
Zahlen beschrieben und auf einer kontinuierlichen geordneten Skala gemessen. Das
sind Dinge wie Größe,
Gewicht und Blutdruck.
Unter Berücksichtigung dieser gesamten Definition haben wir also
entweder qualitative oder quantitative Messungen an einer Reihe von Elementen, aus denen Daten bestehen.
Keine schlechte Definition.
Als wir die Definitionen durchgingen, waren
unsere Beispiele für Daten,
Herkunftsland, Geschlecht
, Größe und Gewicht ziemlich einfache Beispiele.
Sie können sie sich leicht in einer gut aussehenden Tabelle wie dieser vorstellen,
mit Personen an einer Seite der Tabelle in Zeilen
und den Messungen für diese Variablen entlang der Spalten.
Leider werden Ihnen Daten selten auf diese Weise präsentiert.
Die Datensätze, denen wir häufig begegnen, sind viel chaotischer.
Es ist unsere Aufgabe, die Informationen, die wir benötigen, zusammengefügt
in etwas Übersichtliches wie die Tabelle hier, zu extrahieren,
sie angemessen zu analysieren und oft unsere Ergebnisse zu visualisieren.
Dies sind nur einige der Datenquellen, auf die Sie stoßen könnten.
Und wir werden uns kurz ansehen, wie einige dieser Datensätze oft aussehen
oder wie sie interpretiert werden können.
Eines haben sie jedoch gemeinsam: die Unordnung der Daten.
Sie müssen arbeiten, um die Informationen zu extrahieren, die Sie zur Beantwortung Ihrer Frage benötigen.
Eine Art von Daten, mit der ich regelmäßig arbeite, ist die Sequenzierung von Daten.
Diese Daten werden in der Regel zuerst im Fast-Queue-Format gefunden.
Das von Sequenziermaschinen erzeugte Rohdateiformat.
Diese Dateien sind oft Hunderte von Millionen Zeilen lang,
und es ist unsere Aufgabe, sie in ein verständliches und interpretierbares Format zu analysieren und daraus
etwas über das Genom dieser Person zu schließen.
In diesem Fall wurden diese Daten in Expressionsdaten interpretiert
und ein Diagramm erstellt, das als Vulkandiagramm bezeichnet wird.
Eine reichhaltige Informationsquelle sind landesweite Volkszählungen.
In diesen beantworten fast alle Mitglieder eines Landes eine Reihe
standardisierter Fragen und reichen diese Antworten an die Regierung ein.
Wenn Sie so viele Befragte haben, sind
die Daten umfangreich und unübersichtlich.
Aber sobald diese große Datenbank für die Abfrage bereit ist,
sind die eingebetteten Antworten wichtig.
Hier haben wir ein sehr grundlegendes Ergebnis der letzten US-Volkszählung.
Dabei sind alle Befragten nach Geschlecht und Alter aufgeteilt.
Diese Verteilung ist in diesem Diagramm der Populationspyramide dargestellt.
Ich fordere Sie dringend auf,
bei der Volkszählungsbehörde Ihres Heimatlandes nachzuschauen, falls verfügbar, und sich einige der dortigen Daten anzusehen.
Dies ist ein Scheinbeispiel für eine elektronische Patientenakte.
Dies ist eine beliebte Methode zur Speicherung von Gesundheitsinformationen,
und immer mehr bevölkerungsbezogene Studien verwenden diese Daten, um
Fragen zu beantworten und Rückschlüsse auf die Bevölkerung
insgesamt zu ziehen oder um Möglichkeiten zur Verbesserung der medizinischen Versorgung zu identifizieren.
Wenn Sie beispielsweise nach den häufigsten Allergien einer Population fragen,
müssen Sie die Allergieinformationen vieler Personen extrahieren
und diese in ein leicht interpretierbares Tabellenformat umwandeln, in
dem Sie dann Ihre Analyse durchführen.
Eine komplexere Datenquelle zur Analyse unserer Bilder und Slash-Videos.
In einem Bild oder Video ist eine Fülle von Informationen codiert, die
nur darauf warten, extrahiert zu werden.
Ein Beispiel für eine Bildanalyse,
mit dem Sie vielleicht vertraut sind, ist das Hochladen eines Bildes auf Facebook.
Es erkennt nicht nur automatisch Gesichter auf dem Bild,
sondern schlägt dann vor, um wen es sich handelt.
Ein lustiges Beispiel, mit dem Sie spielen können, ist
die Software The Deep Dream, die ursprünglich für die Erkennung von Gesichtern in einem Bild entwickelt wurde,
sich aber inzwischen mehr künstlerischen Aktivitäten zugewandt hat.
Es gibt eine weitere unterhaltsame Google-Initiative zur Bildanalyse,
bei der Sie durch Kritzeln helfen, Daten für den Algorithmus für maschinelles Lernen von Google bereitzustellen.
In Anbetracht der Tatsache, dass wir viel Zeit damit verbracht haben, zu untersuchen, was Daten
sind, müssen wir wiederholen, dass Daten wichtig sind,
aber sie sind zweitrangig gegenüber Ihrer Frage.
Ein guter Datenwissenschaftler stellt zuerst Fragen und sucht dann nach relevanten Daten.
Zugegeben, oft beschränken die verfügbaren Daten
bestimmte Fragen, die Sie stellen möchten, oder ermöglichen es sogar, sie zu stellen.
In diesen Fällen müssen Sie möglicherweise Ihre Frage neu formulieren oder
eine verwandte Frage beantworten, aber die Daten selbst sind nicht ausschlaggebend für die Fragestellung.
In dieser Lektion haben wir uns auf Daten konzentriert,
sowohl bei der Definition als auch bei der Untersuchung, wie Daten aussehen und wie sie verwendet werden können.
Zunächst haben wir uns zwei Definitionen von Daten angesehen.
Eine, die sich auf die Aktionen rund um Daten konzentriert,
und eine andere darauf, was aus Daten besteht.
Die zweite Definition beinhaltet die Konzepte von Populationen
und Variablen und untersucht die Unterschiede zwischen quantitativen und qualitativen Daten.
Zweitens haben wir verschiedene Datenquellen untersucht, auf die Sie möglicherweise
stoßen, und den Mangel an aufgeräumten Datensätzen hervorgehoben.
Beispiele für unübersichtliche Datensätze, bei denen
Rohdaten in eine interpretierbare Form gebracht werden müssen,
können Sequenzierungsdaten,
Volkszählungsdaten, elektronische Patientenakten usw. sein.
Schließlich kehren wir zu unseren Ansichten zum Zusammenhang zwischen Daten
und Ihrer Frage zurück und betonen, wie wichtig Strategien sind, bei denen die Frage an erster Stelle steht.
Sie könnten alle Daten haben, auf die Sie sich jemals erhoffen könnten,
aber wenn Sie zu Beginn keine Frage haben, sind
die Daten nutzlos.
Hilfe bekommen
Eine der wichtigsten Fähigkeiten, die Sie
als Datenwissenschaftler benötigen, ist Ihre Fähigkeit, Probleme zu lösen.
Und manchmal braucht man dafür Hilfe.
Die Fähigkeit, Probleme zu lösen, ist die Grundlage der Datenwissenschaft. Es ist
also von größter Bedeutung, dies tun zu können.
In dieser Lektion werden wir Sie mit einigen Strategien ausstatten, die Ihnen helfen, wenn Sie
mit einem Problem nicht weiterkommen und Hilfe benötigen.
Ein Großteil dieser Informationen wurde aus Roger Pengs Video über Getting Help zusammengestellt.
Und Eric Raymonds How to Ask Questions the Smart Way, also
schauen Sie sich diese Ressourcen auf jeden Fall an.
Bevor wir uns damit befassen, wie Sie Hilfe erhalten können,
müssen wir uns zunächst darauf konzentrieren, warum Sie diese Fähigkeiten überhaupt benötigen.
Zunächst einmal ist dieser Kurs nicht wie ein Standardkurs, den
Sie zuvor besucht haben, an dem 30 bis 100 Personen teilnehmen können und
Sie sich an Ihren Professor wenden können, um sofortige Hilfe zu erhalten.
In dieser Klasse können zu jeder Zeit Tausende von Schülern an der Klasse
teilnehmen, niemand kann all diesen Menschen die ganze Zeit helfen.
Deshalb stellen wir Ihnen in diesem Kurs einige Strategien vor, mit denen Sie sich Hilfe holen können.
Wie bereits erwähnt,
ist die Fähigkeit, Probleme zu lösen, oft eine der Kernkompetenzen eines Datenwissenschaftlers.
Data Science ist neu, Sie sind möglicherweise die erste Person, die auf ein bestimmtes
Problem stößt, und Sie müssen über Fähigkeiten verfügen, mit denen Sie Probleme angehen können
, die sowohl für Sie als auch für die Community neu sind.
Schließlich ist die Problembehebung und
das Finden von Lösungen für Probleme eine großartige übertragbare Fähigkeit.
Es wird Ihnen als Datenwissenschaftler gute Dienste leisten, aber ein
Großteil dessen, was ein Job oft mit sich bringt, ist die Problemlösung.
In der Lage zu sein, über Probleme nachzudenken und effektiv Hilfe zu erhalten, ist für Sie von Vorteil,
egal auf welchem Karriereweg Sie sich befinden.
Bevor du anfängst, andere um
Hilfe bei deinem Problem zu bitten, gibt es einige Schritte, die du selbst ergreifen kannst.
Oft ist die schnellste Antwort eine, die Sie für sich selbst finden.
Eine Ihrer ersten Anlaufstellen bei Datenanalyseproblemen sollte das Lesen der Handbücher oder
Hilfedateien sein.
Versuchen Sie bei unseren Problemen, den Befehl Fragezeichen einzugeben.
Wenn Sie in einem Forum eine Frage stellen, die im Handbuch leicht beantwortet werden kann,
erhalten Sie häufig eine Antwort von, lies das Handbuch. Das
ist nicht der einfachste Weg, um zu der Antwort zu gelangen, nach der Sie gesucht haben. Die
nächsten Schritte sind die Suche bei Google und die Suche in relevanten Foren. Zu den
gängigen Foren für datenwissenschaftliche Probleme gehören Stack Overflow und
Cross Validated.
Zusätzlich
gibt es für Sie in diesem Kurs ein Kursforum, das eine großartige Ressource und sehr hilfreich ist.
Bevor Sie eine Frage in einem Forum posten,
überprüfen Sie mithilfe der Foren-Suchfunktionen, dass sie noch nicht gestellt wurde.
Während Sie googeln, sollten Sie auf Tutorials,
FAQs oder Vignetten aller Befehle oder Programme achten, die Ihnen Probleme bereiten.
Dies sind großartige Ressourcen, um Ihnen den Einstieg zu erleichtern.
Entweder indem wir Ihnen die Sprache/Wörter sagen, die Sie bei Ihren nächsten Suchanfragen verwenden sollen, oder indem wir Ihnen
direkt zeigen, wie Sie etwas tun können.
Wenn Sie weiter in diesen Kurs einsteigen und
R verwenden, können Codierungsprobleme und -fehler auftreten.
Und es gibt ein paar Strategien, die Sie bereit haben sollten, um damit umzugehen.
Meiner Erfahrung nach lassen sich Codierungsprobleme im Allgemeinen in zwei Kategorien einteilen.
Ihr Befehl erzeugt keine Daten und gibt eine Fehlermeldung aus, oder
Ihr Befehl erzeugt eine Ausgabe, aber es ist überhaupt nicht das, was Sie wollten. Für
diese beiden Probleme gibt es unterschiedliche Strategien, um mit ihnen umzugehen.
Wenn Sie eine Fehlermeldung erhalten, war ich dort.
Sie geben einen Befehl ein und alles, was Sie erhalten, sind Zeilen und Zeilen mit wütendem rotem Text, der
Ihnen sagt, dass Sie etwas falsch gemacht haben, und das kann überwältigend sein. Wenn Sie
sich jedoch eine Sekunde Zeit nehmen, um Ihren Befehl auf Tippfehler zu überprüfen und dann
die Fehlermeldung sorgfältig zu lesen, wird das Problem in fast allen Fällen behoben.
Die Fehlermeldungen sind da, um Ihnen zu helfen.
Es ist der Computer, der dir sagt, was schief gelaufen ist.
Und wenn alles andere fehlschlägt, können Sie ziemlich sicher sein, dass
jemand da draußen dieselbe Fehlermeldung erhalten hat, in Panik geraten ist und in einem Forum gepostet hat.
Die Antwort ist da draußen.
Wenn Sie andererseits eine Ausgabe erhalten, sollten Sie
berücksichtigen, wie die Ausgabe von Ihren Erwartungen abweicht.
Und denken Sie darüber nach, wie der Befehl tatsächlich aussieht,
warum er das tun würde und nicht, was Sie wollten.
Die meisten Probleme dieser Art sind darauf zurückzuführen, dass der Befehl, den Sie eingegeben haben,
das Programm angewiesen hat, eine Sache zu tun, und es hat genau diese Sache getan.
Es stellt sich nur heraus, dass das, was Sie ihm gesagt haben, nicht das war, was Sie wollten.
Diese Probleme sind oft am frustrierendsten.
Du bist so nah dran, aber so fern.
Diese Art von Problemen gibt Ihnen viel Übung, wie ein Computerprogramm zu denken. In
Ordnung, Sie haben alles getan, was Sie tun sollten, um das Problem
selbst zu lösen.
Ihr müsst jetzt die großen Waffen reinbringen, andere Leute.
Am einfachsten ist es, einen Kollegen mit etwas Erfahrung mit dem, woran Sie gerade arbeiten, zu finden
und ihn um Hilfe/Anleitung zu bitten.
Das ist oft großartig, weil die Person, die etwas erklärt, ihr
Verständnis festigen kann, während sie es dir beibringt.
Und Sie bekommen eine praktische Erfahrung, um zu sehen, wie sie das Problem lösen würden.
In diesem Kurs können Ihre Kollegen Ihre Klassenkameraden sein, und
Sie können über das Kursforum mit ihnen interagieren.
Überprüfe noch einmal, ob deine Frage noch nicht gestellt wurde.
Aber außerhalb dieses Kurses haben Sie möglicherweise nicht allzu viele Kollegen, die sich mit Data Science auskennen.
Was dann?
Rubber Duck Debugging ist eine lange Tradition einsamer Programmierer auf der ganzen Welt.
In dem Buch The Pragmatic Programmer gibt es eine Geschichte darüber, wie ratlose
Programmierer ihr Problem einer Gummiente erklären und
bei der Erklärung des Problems die Lösung finden.
Wikipedia erklärt es gut.
Viele Programmierer haben die Erfahrung gemacht, ein Programmierproblem
jemand anderem zu erklären, möglicherweise sogar jemandem, der nichts über Programmierung weiß.
Und dann bei der Erklärung des Problems auf die Lösung zu stoßen. Wenn
man beschreibt, was der Code tun soll, und beobachtet, was er tatsächlich tut, wird
jede Inkongruenz zwischen diesen beiden offensichtlich.
Also, wenn Sie das nächste Mal ratlos sind, bringen Sie das Badespielzeug heraus.
Sie haben Ihr Bestes gegeben, Sie haben gesucht und gesucht, Sie haben mit Kollegen gesprochen, Sie haben
alles Mögliche getan, um es selbst herauszufinden, und Sie stecken immer noch fest.
Es ist Zeit, deine Frage in einem relevanten Forum zu posten.
Bevor Sie einfach Ihre Frage stellen,
müssen Sie sich überlegen, wie Sie Ihre Frage am besten stellen können, um hilfreiche Antworten zu erhalten.
Versuchen Sie, Details anzugeben, z. B. eine sehr spezifische Frage, die Sie
beantworten möchten, und welche Schritte Sie bereits zur Fehlerbehebung unternommen haben.
Geben Sie Einzelheiten an, wie das Problem reproduziert werden kann, und fügen Sie Beispieldaten bei, anhand
derer die Problemlöser arbeiten können.
Erläutern Sie
detailliert, was Ihr Ziel und Ihre erwartete Leistung sind und was stattdessen Ihre Leistung war.
Wenn du eine Fehlermeldung bekommen hast, erwähne das auf jeden Fall in deinem Beitrag.
Darüber hinaus sind relevante Informationen zu Ihrem Betriebssystem oder der Version des
betreffenden Produkts häufig hilfreiche Informationen für Ihre potenziellen Problemlöser.
Eines der wichtigsten Details Ihres Beitrags ist der Titel.
Es ist das, was anderen signalisiert, dass Sie Probleme haben.
Es ist eine Kunst, deine Beiträge zu betiteln.
Ohne spezifisch zu sein, gibst du deinen potenziellen Helfern nicht viel zum Ausgehen.
Sie wissen nicht wirklich, was das Problem ist und ob sie Ihnen helfen können.
Stattdessen müssen Sie einige Details darüber angeben, womit Sie Probleme haben.
Zu beantworten, was Sie getan haben und
was das Problem ist, sind zwei wichtige Informationen, die Sie bereitstellen müssen.
Auf diese Weise weiß jemand, der im Forum ist, genau, was passiert und
dass er möglicherweise helfen kann.
Verwenden Sie Titel, die sich auf das ganz spezifische Kernproblem konzentrieren
, bei dem Sie Hilfe erhalten möchten.
Es signalisiert den Leuten, dass Sie nach einer ganz bestimmten Antwort suchen.
Je spezifischer die Frage, desto schneller die Antwort. Wenn Sie
alle
bisher genannten Tipps befolgen, können Sie in Foren posten und die Forenetikette einhalten.
Du bittest um Hilfe.
Sie hoffen, dass sich jemand anderes die Zeit nimmt, Ihnen zu helfen.
Du musst höflich sein.
Oft erfolgt dies in der Form, dass
Sie spezifische Fragen stellen und selbst einige Problemlösungen durchführen.
Und geben Sie potenziellen Problemlösern einfachen Zugriff auf alle Informationen, die sie
benötigen, um Ihnen zu helfen. Wenn Sie
einige dieser Vor- und Nachteile formalisieren, müssen Sie einige Richtlinien befolgen.
Stellen Sie vor dem Posten sicher, dass Sie Ihre Frage in der richtigen Form stellen, und
lesen Sie die Richtlinien für Forenbeiträge.
Stellen Sie sicher, dass Sie Ihr Ziel beschreiben und
das Problem in Ihren bisherigen Problemlösungsschritten explizit und detailliert erläutern.
Geben Sie die Mindestinformationen an, die zur Beschreibung und Replikation des Problems erforderlich sind. Überfordern Sie die
Leute nicht mit Problemen, die nichts miteinander zu tun haben.
Und zum Schluss die großen Zwei.
Erstens, sei höflich.
Diese Leute helfen dir.
Und zweitens, stellen Sie sicher, dass Sie Ihrem Beitrag nachgehen und die Lösung veröffentlichen.
Nicht nur die Menschen, die dir helfen, verdienen Dank, sondern
das ist auch hilfreich für alle anderen, die später das gleiche Problem haben wie du.
Es gibt auch ziemlich klare Richtlinien, was nicht zu tun ist.
Erstens möchte niemand jemandem helfen, der annimmt, dass die Ursache des Problems
nicht darin
besteht, dass er einen Fehler gemacht hat, sondern dass etwas mit dem Programm nicht stimmt.
Spoiler-Warnung.
Es liegt fast immer daran, dass du einen Fehler gemacht hast.
Ebenso möchte niemand deine Hausaufgaben für dich machen.
Sie wollen jemandem helfen, der wirklich versucht zu lernen, und
keine Abkürzung finden.
Außerdem ist es für Leute, die in mehreren Foren aktiv sind,
immer ärgerlich, wenn dieselbe Person dieselbe Frage in fünf verschiedenen Foren stellt.
Oder wenn dieselbe Frage wiederholt im selben Forum gestellt wird, seien Sie geduldig.
Wählen Sie das für Ihre Zwecke relevanteste Forum aus, posten Sie einmal und warten Sie.
Es ist eine Kunst, Probleme zu lösen, und
die einzige Möglichkeit, sich darin zu üben, besteht darin, rauszugehen und Probleme zu lösen.
In dieser Lektion
schauen wir uns an, wie Sie effektiv Hilfe erhalten, wenn Sie auf ein Problem stoßen.
Das ist wichtig für diesen Kurs, aber auch für deine Zukunft als Data Scientist.
Wir haben uns zuerst die Strategien angesehen, die wir anwenden können, bevor wir um Hilfe gebeten haben.
Dazu gehört das Lesen des Handbuchs, das Überprüfen der Hilfedateien und das Durchsuchen von Google und den
entsprechenden Foren.
Wir haben auch einige häufig auftretende Codierungsprobleme behandelt, mit denen Sie möglicherweise konfrontiert sind, und
einige vorbereitende Schritte, die Sie selbst ergreifen können.
Dazu gehört auch, dass Sie Fehlermeldungen besondere Aufmerksamkeit schenken und
untersuchen, wie sich Ihr Code im Vergleich zu Ihrem Ziel verhalten hat.
Sobald Sie diese Möglichkeiten ausgeschöpft haben, bitten wir andere Personen um Hilfe.
Wir können Kollegen um Hilfe bitten oder unseren treuen Gummienten unsere Probleme erklären,
sei es eine echte Gummiente oder ein ahnungsloser Mitarbeiter.
Unser Kursforum ist auch eine großartige Ressource für
Sie alle, um mit vielen Ihrer Kollegen zu sprechen.
Stell dich vor.
Und wenn alles andere fehlschlägt, können wir in Foren posten, sei es in diesem Kurs oder in einem anderen
Forum, wie Stack Overflow, mit sehr spezifischen, reproduzierbaren Fragen.
Bevor du das tust, solltest du deine Forum-Etikette auffrischen.
Es hat nie jemandem geschadet, höflich zu sein.
Sei ein guter Bürger unserer Foren.
Es ist eine Kunst, Probleme zu lösen, und
die einzige Möglichkeit, sich darin zu üben, besteht darin, rauszugehen und Probleme zu lösen.
Mach dich an die Arbeit.
Der Prozess der Datenwissenschaft
In den ersten Lektionen dieses Kurses
besprechen wir, was Daten und Datenwissenschaft sind und wie Sie Hilfe erhalten können.
Was wir noch nicht behandelt haben, ist, wie ein echtes Data-Science-Projekt aussieht.
Dazu werden wir zunächst ein echtes Data-Science-Projekt durchgehen,
die Teile eines typischen Projekts aufschlüsseln und dann
eine Reihe von Links zu anderen interessanten Data-Science-Projekten bereitstellen.
Unser Ziel in dieser Lektion ist es, Sie mit dem Prozess vertraut zu machen, den
man bei der Durchführung von Data-Science-Projekten durchläuft.
Jedes Data-Science-Projekt beginnt mit einer Frage, die mit Daten beantwortet werden soll.
Das bedeutet, dass die Fragestellung ein wichtiger erster Schritt in diesem Prozess ist.
Der zweite Schritt besteht darin,
die Daten zu finden oder zu generieren, die Sie zur Beantwortung dieser Frage verwenden werden.
Sobald die Frage geklärt ist und die Daten vorliegen,
werden die Daten zunächst analysiert, indem
die Daten untersucht und dann häufig modelliert werden,
was bedeutet, dass einige statistische oder maschinelle Lerntechniken verwendet werden, um
die Daten zu analysieren und Ihre Frage zu beantworten.
Nachdem aus dieser Analyse Schlüsse gezogen wurden,
muss das Projekt anderen mitgeteilt werden.
Manchmal ist dies der Bericht, den Sie an Ihren Chef oder Ihr Team bei der Arbeit senden,
manchmal ist es ein Blogbeitrag.
Oft ist es eine Präsentation vor einer Gruppe von Kollegen.
Unabhängig davon
beinhaltet ein Data-Science-Projekt fast immer irgendeine Form der Kommunikation der Projektergebnisse.
Wir werden diese Schritte anhand eines Beispiels für ein Data-Science-Projekt unten durchgehen.
Für dieses Beispiel verwenden wir
eine Beispielanalyse von einer Datenwissenschaftlerin namens Hilary Parker.
Ihre Arbeit ist auf ihrem Blog zu finden und
das spezifische Projekt, an dem wir hier arbeiten werden, stammt aus dem Jahr 2013 mit dem Titel
Hilary: Der giftigste Babyname in der Geschichte der USA.
Um das Beste aus dieser Lektion herauszuholen,
klicken Sie auf diesen Link und lesen Sie Hilarys Beitrag durch.
Wenn Sie fertig sind, kehren Sie zu
dieser Lektion zurück und lesen Sie sich die Aufschlüsselung dieses Beitrags durch.
Wenn Sie mit einem Data-Science-Projekt beginnen,
ist es immer gut, wenn Ihre Frage klar definiert ist.
Während der Analyse können weitere Fragen auftauchen.
Aber zu wissen, was Sie mit Ihrer Analyse beantworten möchten, ist ein wirklich wichtiger erster Schritt.
Hilary Parkers Frage ist in ihrem Beitrag fett gedruckt. Wenn Sie
dies hervorheben, wird deutlich, dass sie interessiert ist, und beantwortet die folgende Frage:
Ist Hilary/Hillary wirklich die am schnellsten vergiftete Benennung der aufgezeichneten amerikanischen Geschichte?
Um diese Frage zu beantworten,
sammelte Hilary Daten von der Website der sozialen Sicherheit.
Dieser Datensatz umfasste 1.000 der beliebtesten Babynamen von 1880 bis 2011.
Wie im Blogbeitrag erklärt,
war Hilary daran interessiert, das relative Risiko für jeden der
4.110 verschiedenen Namen in ihrem Datensatz von einem Jahr zum nächsten, von 1880-2011, zu berechnen.
Von Hand wäre das ein Albtraum.
Zum Glück
konnte Hilary durch das Schreiben von Code in R, der alle auf GitHub verfügbar ist, diese Werte für all diese Namen in all den Jahren generieren.
Zu diesem Zeitpunkt ist es nicht wichtig, vollständig zu
verstehen, was eine relative Risikoberechnung ist.
Hilary macht jedoch großartige Arbeit, wenn sie es in ihrem Beitrag aufschlüsselt.
Es ist jedoch wichtig zu wissen, dass nach dem Zusammenstellen der Daten
der nächste Schritt darin besteht, herauszufinden, was Sie
mit diesen Daten tun müssen, um Ihre Frage zu beantworten.
Für Hilarys Frage
musste sie zur Beantwortung ihrer Frage das relative Risiko für jeden Namen von einem Jahr zum nächsten von 1880 bis 2011 berechnen und den Prozentsatz der Babys betrachten, die in einem bestimmten Jahr jeden Namen nannten.
Was Sie in dem Blogbeitrag nicht sehen, ist der gesamte Code, den Hilary
geschrieben hat, um die Daten von der Website der Sozialversicherung abzurufen,
um sie in dem Format zu erhalten, das sie für die Analyse und die Generierung der Zahlen benötigt hat.
Wie oben erwähnt, stellte sie den gesamten Code auf GitHub zur Verfügung
, damit andere sehen konnten, was sie getan hat, und ihre Schritte wiederholen konnten, wenn sie wollten.
Zusätzlich zu diesem Code müssen
Data-Science-Projekte oft viel Code schreiben und
viele Zahlen generieren, die nicht in Ihren Endergebnissen enthalten sind.
Dies ist Teil des datenwissenschaftlichen Prozesses, um
herauszufinden, wie Sie das tun können, was Sie tun möchten, um Ihre interessante Frage zu beantworten.
Es ist Teil des Prozesses.
Es taucht nicht immer in Ihrem Abschlussprojekt auf und kann sehr zeitaufwändig sein.
Da Hilary nun die erforderlichen Werte berechnet hatte,
begann sie jedoch, die Daten zu analysieren.
Als Erstes sah sie sich die Namen an, bei denen
der Prozentsatz von einem Jahr zum nächsten am stärksten gesunken ist.
Nach dieser vorläufigen Analyse belegte
Hilary den sechsten Platz auf der Liste. Das
heißt, es gab fünf weitere Namen, deren Beliebtheitsrückgang in einem einzigen Jahr
größer war als der, den der Name Hilary von 1992 bis 1993 erlebt hatte.
Betrachtet
man die Ergebnisse dieser Analyse, so erschienen die ersten fünf Jahre Hilary Parker eigenartig.
Es ist immer gut zu überlegen, ob die Ergebnisse den
Erwartungen vieler Analysen entsprachen oder nicht.
Keiner von ihnen schien ein Name zu sein, der lange Zeit beliebt war.
Um zu sehen, ob diese Vermutung zutrifft, zeichnete
Hilary den Prozentsatz der Babys auf, die
jedes Jahr mit jedem der Namen aus dieser Tabelle geboren wurden.
Was sie herausfand, war, dass unter diesen vergifteten
Namen, die von einem Jahr auf das
andere
einen starken Rückgang ihrer Popularität erlebten, alle Namen außer Hilary plötzlich populär wurden und dann an Popularität verloren.
Hilary Parker konnte herausfinden, warum die meisten dieser anderen Namen populär wurden.
Lesen Sie also auf jeden Fall diesen Abschnitt ihres Beitrags.
Der Name Hilary war jedoch anders.
Es war eine Zeit lang beliebt und verlor dann völlig an Popularität.
Um herauszufinden, was genau mit dem Namen Hilary los war,
entfernte sie Namen, die für kurze Zeit populär wurden, bevor sie
abbrach, und betrachtete nur Namen, die mehr als 20 Jahre lang unter den Top 1.000 waren.
Die Ergebnisse dieser Analyse zeigten definitiv, dass Hilary
1992 von allen weiblichen Babys, die zwischen 1880 und 2011 benannt wurden, am schnellsten an Popularität verlor.
Marians Niedergang vollzog sich über viele Jahre allmählich.
Für den letzten Schritt in diesem Datenanalyseprozess
war es an der Zeit, sie mit der Welt zu teilen, nachdem Hilary Parker ihre Frage beantwortet hatte.
Ein wichtiger Teil jedes Data-Science-Projekts ist die
effektive Kommunikation der Projektergebnisse.
Hilary tat dies, indem sie
einen wunderbaren Blogbeitrag schrieb, in dem sie die Ergebnisse ihrer Analyse mitteilte.
Beantwortete die Frage, die sie beantworten
wollte, und zwar auf unterhaltsame Weise.
Darüber hinaus ist es wichtig zu beachten, dass die meisten Projekte auf der Arbeit anderer aufbauen.
Es ist wirklich wichtig, diesen Leuten Anerkennung zu geben.
Hilary erreicht dies, indem sie auf einen Blogbeitrag verlinkt,
in dem zuvor jemand eine ähnliche Frage gestellt hatte,
auf die Website der sozialen Sicherheit, auf der sie
die Daten erhielt und auf der sie etwas über Web-Scraping erfuhr.
Hilarys Arbeit wurde mit der Programmiersprache R ausgeführt.
In den Kursen dieser Reihe
lernen Sie die Grundlagen der Programmierung in R, der
Untersuchung und Analyse von Daten
sowie der Erstellung von Berichten und Webanwendungen, mit
denen Sie Ihre Ergebnisse effektiv kommunizieren können.
Um Ihnen ein Beispiel für die Arten von Dingen zu geben, die mit
der R-Programmierung und
einer Reihe verfügbarer Tools, die R verwenden, erstellt werden können, finden Sie im Folgenden einige Beispiele für die Arten von Dingen, die
mit dem Data-Science-Prozess und der R-Programmiersprache erstellt wurden.
Die Arten von Dingen, die Sie am Ende dieser Kursreihe generieren können.
Masterstudenten der University of Pennsylvania machten sich daran,
das Risiko einer Opioidüberdosierung in Providence, Rhode Island, vorherzusagen.
Sie enthalten Einzelheiten zu den von ihnen verwendeten Daten.
Die Schritte, die sie unternommen haben, um ihre Daten zu bereinigen
, ihren Visualisierungsprozess und ihre Endergebnisse.
Die Details sind jetzt zwar nicht wichtig, aber es ist
wichtig, den Prozess zu sehen und zu sehen, welche Arten von Berichten generiert werden können.
Darüber hinaus haben sie eine Shiny-App erstellt,
bei der es sich um eine interaktive Webanwendung handelt.
Das bedeutet, dass Sie wählen können, auf welches Viertel in Providence Sie sich konzentrieren möchten.
All dies wurde mit R-Programmierung erstellt.
Die folgenden sind kleinere Projekte als das obige Beispiel,
aber dennoch datenwissenschaftliche Projekte.
In jedem Projekt hatte der Autor eine Frage, die er
beantworten wollte, und verwendete Daten, um diese Frage zu beantworten.
Sie untersuchten, visualisierten und analysierten die Daten.
Anschließend verfassten sie Blogbeiträge, um ihre Ergebnisse zu kommunizieren.
Werfen Sie einen Blick darauf, um mehr über die aufgelisteten Themen zu erfahren und zu sehen, wie andere
den Data-Science-Projektprozess bearbeiten und ihre Ergebnisse kommunizieren.
Maelle Samuel wollte anhand von Daten herausfinden, wo man
in den USA angesichts ihrer Wetterpräferenzen leben sollte.
David Robinson führte eine Analyse von
Trumps Tweets durch, um zu zeigen, dass Trump nur die wütenderen Tweets selbst schreibt.
Charlotte Galvin verwendete offene Daten
der Stadt Toronto, um eine Karte mit Informationen über Kliniken für sexuelle Gesundheit zu erstellen.
Wir hoffen, in dieser Lektion vermittelt zu haben, dass sich
Data-Science-Projekte manchmal mit schwierigen Fragen befassen.
Können wir das Risiko einer Opioidüberdosierung vorhersagen?
In anderen Fällen besteht das Ziel des Projekts darin,
eine Frage zu beantworten, die Sie persönlich interessiert:
Ist Hilary der am schnellsten vergiftete Babyname in der aufgezeichneten amerikanischen Geschichte?
In beiden Fällen ist der Prozess ähnlich.
Sie müssen Ihre Frage formulieren, Daten abrufen,
Ihre Daten untersuchen und analysieren
und Ihre Ergebnisse kommunizieren.
Mit den Tools, die Sie in dieser Kursreihe erlernen,
können Sie
Ihre eigenen Data-Science-Projekte wie die in dieser Lektion enthaltenen Beispiele planen und durchführen.
Installieren von R
Jetzt, wo wir wissen, was ein Data Scientist ist,
wie man Antworten findet,
und dann einige Zeit damit verbringen, ein Beispiel für Data Science zu besprechen,
ist es an der Zeit, Sie darauf vorzubereiten, auf eigene Faust mit der Erkundung zu beginnen.
Der erste Schritt ist die Installation von R.
Lassen Sie uns zunächst genau daran erinnern, was R ist und warum wir es vielleicht verwenden möchten.
R ist sowohl eine Programmiersprache in einer Umgebung, die
sich hauptsächlich auf statistische Analysen als auch auf Grafiken konzentriert.
Es wird eines der wichtigsten Tools sein, die Sie in diesem und den folgenden Kursen verwenden.
R wird vom Comprehensive R Archive Network oder CRAN heruntergeladen.
Dies ist zwar Ihr erster Versuch, aber
wir werden immer wieder zu CRAN zurückkehren, wenn wir Pakete installieren.
Halten Sie also Ausschau.
Außerhalb dieses Kurses
fragen Sie sich vielleicht: „Warum sollte ich R verwenden?“
Ein Grund, R verwenden zu wollen, ist die Beliebtheit.
R entwickelt sich schnell zur Standardsprache für statistische Analysen.
Das macht R zu einer großartigen Sprache zum Erlernen, denn je beliebter Software ist,
desto schneller werden neue Funktionen entwickelt,
desto leistungsfähiger wird sie und desto besser ist die Unterstützung.
Wie Sie in dieser Grafik sehen können,
ist R außerdem eine der fünf Sprachen, nach denen in Stellenausschreibungen von Datenwissenschaftlern am häufigsten gefragt wird.
Ein weiterer Vorteil für R sind die Kosten.
Kostenlos. Dieser ist ziemlich selbsterklärend.
Jeder Aspekt von R kann kostenlos verwendet werden,
im Gegensatz zu einigen anderen Statistikpaketen, die Sie vielleicht von EG, SAS oder SPSS gehört haben.
Es gibt also keine Kostenbarriere für die Nutzung von R.
Ein weiterer Vorteil ist die umfangreiche Funktionalität von R.
R ist eine sehr vielseitige Sprache.
Wir haben über seine Verwendung in Statistiken und Grafiken gesprochen.
Es kann jedoch um
viele verschiedene Funktionen erweitert werden, z. B. um das Erstellen von Websites, das Erstellen von Karten, das
Verwenden von GIS-Daten, das Analysieren von Sprachen und sogar das Erstellen dieser Vorträge und Videos.
Hier zeigen wir eine in R erstellte Punktdichtekarte der Bevölkerung Europas.
Jeder Punkt ist 50 Menschen in Europa wert.
Für welche Aufgabe Sie auch immer im Sinn haben,
es gibt oft ein Paket zum Herunterladen, das genau das tut.
Der Grund dafür, dass die Funktionalität von R so
umfangreich ist, ist die Community, die rund um
R aufgebaut wurde. Einzelpersonen haben sich zusammengeschlossen, um Pakete zu entwickeln, die die Funktionalität von R erweitern,
und täglich werden weitere entwickelt.
Insbesondere für Leute, die gerade erst mit R anfangen,
ist die Community aufgrund ihrer Beliebtheit ein großer Vorteil.
Es gibt mehrere Foren mit Seiten und Seiten, die der Lösung von R-Problemen gewidmet sind.
Darüber haben wir in der Lektion Hilfe bekommen gesprochen.
Diese Foren sind großartig, beide haben andere Leute gefunden, die
das gleiche Problem wie Sie hatten, und Ihre eigenen neuen Probleme gepostet.
Nachdem wir einige Zeit damit verbracht haben, uns mit den Vorteilen von R zu befassen,
ist es an der Zeit, es zu installieren. Im
Folgenden gehen wir auf die Installation für Windows und Mac ein.
Beachten Sie jedoch, dass dies allgemeine Richtlinien
sind und dass sich kleine Details im Laufe der Vorlesung wahrscheinlich ändern werden.
Benutze das als Gerüst.
Sowohl für Windows- als auch für Mac-Computer
beginnen wir auf der CRAN-Homepage.
Wenn Sie einen Windows-Computer verwenden,
folgen Sie dem Link R für Windows herunterladen und folgen Sie den dortigen Anweisungen.
Wenn Sie R zum ersten Mal installieren,
wechseln Sie zur Basisdistribution und klicken Sie oben auf der Seite auf den Link, der
etwa R-Versionsnummer für Windows herunterladen lauten sollte.
Dadurch wird eine ausführbare Datei zur Installation heruntergeladen.
Öffnen Sie die ausführbare Datei und lassen Sie sie laufen, wenn Sie von einer Sicherheitswarnung dazu aufgefordert werden.
Wählen Sie bei der
Installation die Sprache aus, die Sie bevorzugen, und stimmen Sie den Lizenzinformationen zu.
Als Nächstes werden Sie nach einem Zielort gefragt.
Dies werden wahrscheinlich standardmäßig Programmdateien in einem Unterordner namens R sein,
gefolgt von einem anderen Unterverzeichnis für die Versionsnummer.
Sofern Sie keine Probleme damit haben,
ist der Standardspeicherort perfekt.
Sie werden dann aufgefordert, auszuwählen, welche Komponenten installiert werden sollen.
Sofern Ihnen nicht genügend Speicher zur Verfügung steht,
ist die Installation aller Komponenten wünschenswert.
Als Nächstes werden Sie nach den Startoptionen gefragt, und
auch hier sind die Standardeinstellungen dafür in Ordnung.
Sie werden dann gefragt, wo das Setup die Verknüpfungen platzieren soll.
Das liegt ganz bei dir.
Sie können zulassen,
dass das Programm zum Startmenü hinzugefügt wird, oder Sie können unten auf das Feld mit der Aufschrift
„Keinen Startmenü-Link erstellen“ klicken.
Schließlich werden Sie gefragt, ob Sie ein Desktop- oder Schnellstartsymbol wünschen.
Es liegt an dir. Ich empfehle jedoch nicht, die Standardeinstellungen für die Registrierungseinträge zu ändern.
Nach diesem Fenster sollte die Installation beginnen.
Testen Sie, ob die Installation funktioniert hat, indem Sie R zum ersten Mal öffnen.
Wenn Sie einen Mac-Computer verwenden,
folgen Sie dem Link R für Mac OS X herunterladen.
Dort finden Sie die verschiedenen R-Versionen zum Herunterladen.
Hinweis: Wenn Ihr Mac älter als OS X 10.6 Snow Leopard ist,
müssen Sie die Anweisungen auf dieser Seite befolgen, um
ältere Versionen von R herunterzuladen, die mit diesen Betriebssystemen kompatibel sind.
Klicken Sie auf den Link zur neuesten Version von R,
wodurch eine PKG-Datei heruntergeladen wird.
Öffnen Sie die PKG-Datei und folgen Sie den Anweisungen des Installationsprogramms.
Klicken Sie zunächst auf der Willkommensseite
und erneut auf der Seite mit wichtigen Informationen auf „Weiter“.
Als Nächstes wird Ihnen die Softwarelizenzvereinbarung angezeigt.
Nochmals, fahren Sie fort.
Als Nächstes werden Sie möglicherweise aufgefordert, ein Ziel für R auszuwählen, das
entweder für alle Benutzer oder für eine bestimmte Festplatte verfügbar ist.
Wählen Sie aus, was Ihrer Meinung nach am besten zu Ihrem Setup passt.
Schließlich befinden Sie sich auf der Standardinstallationsseite.
R wählt ein Standardverzeichnis aus,
und wenn Sie mit diesem Speicherort zufrieden sind
, klicken Sie auf Installieren.
An dieser Stelle werden Sie möglicherweise aufgefordert, das Admin-Passwort einzugeben.
Tun Sie dies und die Installation beginnt.
Sobald die Installation abgeschlossen ist,
gehen Sie zu Ihren Anwendungen und suchen Sie R. Testen Sie, ob
die Installation funktioniert hat, indem Sie R zum ersten Mal öffnen.
In dieser Lektion haben wir uns zunächst angesehen, was R ist und warum wir es vielleicht verwenden möchten.
Anschließend konzentrierten wir uns auf den Installationsprozess für R auf Windows- und Mac-Computern.
Vergewissern Sie sich, dass R ordnungsgemäß installiert ist, bevor Sie mit der nächsten Lektion fortfahren.
Installieren von R Studio
Wir haben R installiert und können die R-Schnittstelle öffnen, um Code einzugeben.
Es gibt aber auch andere Möglichkeiten, mit R zu kommunizieren,
und eine dieser Möglichkeiten ist die Verwendung von RStudio.
In dieser Lektion installieren wir RStudio auf Ihrem Computer.
RStudio ist eine grafische Benutzeroberfläche für R, mit der Sie
Code schreiben, bearbeiten und speichern,
Plots generieren, anzeigen und speichern, Dateien, Objekte und Datenrahmen verwalten und in
Versionskontrollsysteme integrieren können, um nur einige seiner Funktionen zu nennen.
Wir werden in zukünftigen Lektionen genau untersuchen, was RStudio für Sie tun kann.
Aber für alle, die gerade erst mit R-Codierung beginnen,
ist der visuelle Charakter dieses Programms als Schnittstelle für R ein großer Vorteil.
Zum Glück ist die Installation von RStudio ziemlich einfach.
Zuerst gehen Sie zur RStudio-Downloadseite.
Wir möchten die RStudio Desktop-Version der Software herunterladen.
Klicken Sie daher unter dieser Überschrift auf den entsprechenden Download.
Sie sehen eine Liste der Installationsprogramme für unterstützte Plattformen.
Zu diesem Zeitpunkt unterscheidet sich der Installationsvorgang für Macs und Windows.
Folgen Sie daher den Anweisungen für das entsprechende Betriebssystem.
Wählen Sie für Windows den RStudio-Installer für die verschiedenen Windows-Editionen; Vista,7,8,10.
Dadurch wird der Download-Vorgang eingeleitet.
Wenn der Download abgeschlossen ist,
öffnen Sie diese ausführbare Datei, um auf den Installationsassistenten zuzugreifen.
Möglicherweise wird zu diesem Zeitpunkt eine Sicherheitswarnung angezeigt.
Erlauben Sie der App, Änderungen an Ihrem Computer vorzunehmen.
Danach öffnet sich der Installationsassistent.
Es ist für die Installation geeignet, die Standardeinstellungen in jedem Fenster des Assistenten zu befolgen.
Kurz gesagt, klicken Sie auf dem Willkommensbildschirm auf Weiter.
Wenn Sie RStudio an einem anderen Ort installieren möchten,
durchsuchen Sie Ihr Dateisystem.
Andernfalls wird wahrscheinlich standardmäßig der Ordner mit den Programmdateien verwendet. Dies ist angemessen.
Klicken Sie auf „Weiter“.
Erlauben Sie RStudio auf dieser letzten Seite, eine Startmenü-Verknüpfung zu erstellen.
Klicken Sie auf „Installieren“. R Studio wird jetzt installiert.
Warten Sie, bis dieser Vorgang abgeschlossen ist.
R Studio ist jetzt auf Ihrem Computer installiert.
Klicken Sie auf „Fertig stellen“. Überprüfen Sie, ob RStudio
ordnungsgemäß funktioniert, indem Sie es von Ihrem Startmenü aus öffnen.
Wählen Sie für Macs das Macs OS X RStudio-Installationsprogramm;
Mac OS X 10.6+ (64-Bit).
Dadurch wird der Download-Vorgang eingeleitet.
Wenn der Download abgeschlossen ist,
klicken Sie auf die heruntergeladene Datei und die Installation beginnt.
Wenn dies abgeschlossen ist,
öffnet sich das Anwendungsfenster.
Ziehen Sie das RStudio-Symbol in das Anwendungsverzeichnis.
Testen Sie die Installation, indem
Sie Ihren Anwendungsordner und die RStudio-Software öffnen.
In dieser Lektion haben wir RStudio
sowohl für Macs als auch für Windows-Computer installiert.
Bevor Sie mit der nächsten Vorlesung fortfahren,
klicken Sie sich durch die verfügbaren Menüs und erkunden Sie die Software ein wenig.
Wir werden eine ganze Lektion der Erkundung von RStudio widmen,
aber es ist hilfreich, vorher etwas Vertrautheit zu haben.
RStudio Tour
Nachdem wir RStudio installiert haben,
sollten wir uns mit den verschiedenen Komponenten und Funktionen vertraut machen.
RStudio bietet einen Spickzettel der
RStudio-Umgebung, den Sie sich unbedingt ansehen sollten.
Rstudio kann grob in vier Quadranten unterteilt werden, die
jeweils spezifische und vielfältige Funktionen sowie eine Hauptmenüleiste haben.
Wenn Sie RStudio zum ersten Mal öffnen,
sollten Sie ein Fenster sehen, das ungefähr so aussieht.
Möglicherweise fehlt Ihnen der obere linke Quadrant und stattdessen befindet sich auf
der linken Bildschirmseite nur ein Bereich, die Konsole.
Wenn dies der Fall ist, gehen Sie zu „Datei“, dann zu „Neue Datei“
und dann zu „RScript“. Jetzt sollte es dem Bild ähnlicher sein.
Sie können die Größe der einzelnen Quadranten ändern, indem Sie mit der Maus über die
Zwischenräume zwischen den Quadranten fahren und auf die Trennlinie klicken, um die Größe dieser Abschnitte zu ändern.
Wir werden jede der Regionen durchgehen und einige ihrer Hauptfunktionen beschreiben.
Es wäre unmöglich, alles abzudecken, was RStudio kann.
Wir empfehlen Ihnen daher dringend, RStudio auch auf eigene Faust zu erkunden.
Die Menüleiste verläuft über den oberen Bildschirmrand und sollte zwei Zeilen haben.
Die erste Zeile sollte ein ziemlich normales Menü sein, das mit Datei und Bearbeiten beginnt.
Darunter befand sich eine Reihe von Symbolen, die
Abkürzungen für Funktionen sind, die Sie häufig verwenden werden.
Schauen wir uns zunächst die Hauptbereiche der Menüleiste an, die Sie verwenden werden.
Das erste ist das Dateimenü.
Hier können wir neue oder gespeicherte Dateien
öffnen, neue oder gespeicherte Projekte öffnen.
Wir werden in Zukunft eine ganze Lektion über unsere Projekte haben, also bleib dran.
Speichern Sie unser aktuelles Dokument oder schließen Sie RStudio.
Wenn Sie mit der Maus über eine neue Datei fahren,
erscheint ein neues Menü, das Ihnen die verschiedenen verfügbaren Dateiformate vorschlägt.
RScript- und RMarkdown-Dateien sind die am häufigsten verwendeten Dateitypen,
aber Sie können auch rNotebooks,
Web-Apps, Websites oder Folienpräsentationen generieren.
Wenn Sie auf eine dieser Optionen klicken, wird
eine neue Registerkarte im Quellquadranten geöffnet.
In einer zukünftigen Lektion werden wir mehr Zeit mit RMarkdown-Dateien und deren Verwendung verbringen.
Das Session-Menü enthält einige R-spezifische Funktionen, mit denen Sie
R neu starten, unterbrechen oder beenden können. Diese können hilfreich sein, wenn R
sich nicht verhält oder hängen bleibt und Sie die Arbeit beenden und von vorne beginnen möchten.
Das Tools-Menü ist eine Fundgrube an Funktionen, die Sie erkunden können.
Vorerst sollten Sie wissen, dass Sie hier neue Pakete installieren, bis zur
nächsten Vorlesung, zur
Einrichtung Ihrer Versionskontrollsoftware, zur zukünftigen Lektion, zur
Verknüpfung von GitHub und RStudio und zur Festlegung
Ihrer Optionen und Einstellungen für das Aussehen und die Funktionsweise von RStudio gehen können.
Im Moment lassen wir das in Ruhe,
aber schauen Sie sich diese Menüs auf jeden Fall selbst an, sobald Sie
etwas mehr Erfahrung mit RStudio haben und sehen,
was Sie ändern können, um Ihren Vorlieben am besten zu entsprechen.
Die Konsolenregion sollte Ihnen bekannt vorkommen.
Als Sie R öffneten, wurde Ihnen die Konsole angezeigt.
Hier geben Sie
Ausführungsbefehle ein und die Ausgabe dieses Befehls wird angezeigt.
Um Ihren ersten Befehl auszuführen, geben
Sie 1 plus 1 ein und geben Sie dann an der Eingabeaufforderung größer als die Eingabe ein.
Sie sollten die Ausgabe sehen, die von
eckigen Klammern umgeben ist, gefolgt von einer Zwei unter Ihrem Befehl.
Kopieren Sie nun den Code auf dem Bildschirm, fügen Sie ihn in Ihre Konsole ein und drücken Sie „Enter“.
Dadurch wird eine Matrix mit vier Zeilen und zwei Spalten mit den Zahlen eins bis acht erstellt.
Um diese Matrix
zu sehen, schauen Sie sich zuerst den Umgebungsquadranten an, in dem Sie einen Datensatz mit dem Namen Beispiel sehen sollten.
Klicken Sie auf eine beliebige Stelle in der Beispielzeile und eine neue Registerkarte
im Quellquadranten sollte die von Ihnen erstellte Matrix angezeigt werden.
Jeder Datenrahmen oder jede Matrix, die Sie in R erstellen, kann auf diese Weise in RStudio angezeigt werden.
Rstudio gibt Ihnen auch einige Informationen über das Objekt in der Umgebung.
Zum Beispiel, ob es sich um eine Liste oder einen Datenrahmen handelt oder ob es
Zahlen, Ganzzahlen oder Zeichen enthält.
Dies ist eine sehr hilfreiche Information, da einige Funktionen nur mit
bestimmten Datenklassen funktionieren. Zu wissen, welche Art von Daten Sie haben, ist der erste Schritt dazu.
Der Quadrant hat zwei weitere Tabs, die sich über den oberen Rand des Quadranten erstrecken.
Wir schauen uns jetzt nur den Tab Verlauf an.
Ihr Verlaufs-Tab sollte ungefähr so aussehen.
Hier sehen Sie die Befehle, die wir in
dieser Sitzung von R ausgeführt haben. Wenn Sie auf einen von ihnen
klicken, können Sie auf die Konsole oder auf Source klicken. Dadurch wird entweder der Befehl in
der Konsole erneut ausgeführt oder der Befehl wird in die Quelle verschoben.
Tun Sie dies jetzt für Ihre Beispielmatrix und senden Sie sie an die Quelle.
Im Quellbereich werden Sie die meiste Zeit in RStudio verbringen.
Hier speichern Sie die R-Befehle, die Sie für später speichern möchten,
entweder als Aufzeichnung dessen, was Sie getan haben, oder um den Code erneut auszuführen.
Wir werden viel Zeit in diesem Quadranten verbringen, wenn wir über RMarkdown sprechen.
Aber vorerst klicken Sie oben in diesem Quadranten auf das Symbol „Speichern“
und speichern Sie dieses Skript unter dem Namen my_First_R_Script.R.
Jetzt haben Sie immer einen Datensatz über die Erstellung dieser Matrix.
Die letzte Region, die wir uns ansehen werden, befindet sich unten rechts im RStudio-Fenster.
In diesem Quadranten befinden sich oben fünf Tabs:
Dateien, Plots, Pakete, Hilfe und Viewer.
Unter Dateien können Sie alle Dateien in Ihrem aktuellen Arbeitsverzeichnis sehen.
Wenn Sie hier keine Dateien speichern oder abrufen möchten,
können Sie auf
dieser Registerkarte auch das aktuelle Arbeitsverzeichnis ändern, indem Sie die Ellipse ganz rechts verwenden,
den gewünschten Ordner suchen und dann unter dem Zahnrad Mehr
diesen neuen Ordner als Arbeitsverzeichnis festlegen.
Wenn Sie auf der Registerkarte Plots ein Diagramm mit Ihrem Code generieren, wird es hier angezeigt.
Sie können die Pfeile verwenden, um zu zuvor generierten Diagrammen zu navigieren.
Die Zoomfunktion öffnet das Diagramm in
einem neuen Fenster, das viel größer als der Quadrant ist.
Mit „Exportieren“ speichern Sie den Plot.
Sie können es entweder als Bild oder als PDF speichern.
Das Besensymbol löscht alle Plots aus dem Speicher.
Die Registerkarte „Pakete“ wird in der nächsten Lektion zu R-Paketen eingehender untersucht.
Hier können Sie alle Pakete sehen, die Sie installiert haben,
diese Pakete laden und entladen und aktualisieren. Auf
der Registerkarte „Hilfe“ finden Sie
die Dokumentation für Ihre R-Pakete in verschiedenen Funktionen.
Oben rechts in diesem Bereich
befindet sich eine Suchfunktion, wenn Sie eine bestimmte Funktion oder ein bestimmtes Paket in Frage stellen.
In dieser Lektion haben wir einen Rundgang durch die RStudio-Software gemacht.
Wir haben uns mit dem Hauptmenü und seinen verschiedenen Menüs vertraut gemacht.
Wir haben uns die Konsole angesehen, in der unser Code eingegeben und ausgeführt wird.
Wir sind dann zum Umgebungsfenster übergegangen, das alle Objekte auflistet, die
in einer R-Sitzung erstellt wurden, und es Ihnen ermöglicht, diese Objekte in einer neuen Registerkarte und Quelle anzuzeigen.
In demselben Quadranten
gibt es eine Registerkarte „Verlauf“, auf der alle ausgeführten Befehle aufgezeichnet werden.
Es bietet auch die Möglichkeit, den Befehl entweder erneut in der
Konsole auszuführen oder den Befehl zum Speichern an die Quelle zu senden. In
der Quelle speichern Sie Ihre R-Befehle.
Der untere rechte Quadrant enthält eine Liste aller Dateien in Ihrem Arbeitsverzeichnis,
zeigt generierte Plots an, listet Ihre installierten Pakete auf
und stellt Hilfedateien bereit, wenn Sie Hilfe benötigen.
Nehmen Sie sich etwas Zeit, um RStudio auf eigene Faust zu erkunden.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
R Packages
Jetzt, wo wir R in RStudio installiert haben und
ein grundlegendes Verständnis dafür haben, wie sie zusammenarbeiten,
können wir herausfinden, was R so besonders macht, Pakete.
Bisher verwendet alles, was wir mit einem R herumgespielt haben, das Base-R-System.
Base R oder alles, was in R enthalten ist, wenn Sie
es herunterladen, hat eher grundlegende Funktionen für Statistiken und Plotten,
aber es kann manchmal einschränkend sein.
Um die grundlegenden Funktionen von R zu erweitern,
haben die Leute Pakete entwickelt.
Ein Paket ist eine Sammlung von Funktionen, Daten
und Code, die bequem in einem schönen vollständigen Format für Sie bereitgestellt werden.
Zum Zeitpunkt des Verfassens dieses Artikels
stehen etwas mehr als 14.300 Pakete zum Herunterladen zur Verfügung,
jedes mit seinen eigenen speziellen Funktionen und Code,
alle für einen anderen Zweck. Das
R-Paket darf nicht mit der Bibliothek verwechselt werden.
Diese beiden Begriffe werden in der Umgangssprache über R oft miteinander verwechselt.
Eine Bibliothek ist der Ort, an dem sich das Paket auf Ihrem Computer befindet.
Um an eine Analogie zu denken:
Eine Bibliothek ist gut,
eine Bibliothek, und ein Paket ist ein Buch in der Bibliothek.
In der Bibliothek befinden sich das Buch/die Pakete.
Pakete machen R so einzigartig.
Base R hat nicht nur einige großartige Funktionen,
sondern diese Pakete erweitern seine Funktionalität erheblich. Das
vielleicht interessanteste von allem
ist, dass jedes Paket von
der gesamten R-Community entwickelt und veröffentlicht und in Repositorys hinterlegt wird.
Ein Repository ist ein zentraler Ort, an dem sich
viele entwickelte Pakete befinden und zum Herunterladen zur Verfügung stehen.
Es gibt drei große Repositorien.
Sie sind das Comprehensive R Archive Network (CRAN),
das Hauptrepositorium von R mit über 12.100 verfügbaren Paketen.
Es gibt auch das Bioconductor-Repository,
das hauptsächlich für bioinformatische Fokuspakete bestimmt ist.
Schließlich gibt es GitHub, ein sehr beliebtes
Open-Source-Repository, das nicht R-spezifisch ist.
Sie wissen also, wo Sie Pakete finden.
Aber es gibt so viele von ihnen.
Wie können Sie ein Paket finden, das das tut, was Sie in R tun möchten?
Es gibt verschiedene Möglichkeiten, Pakete zu erkunden.
Zunächst gruppiert CRAN alle Pakete nach ihrer Funktionalität/ihrem Thema in 35 Themen.
Es nennt dies seine Aufgabenansicht.
So können Sie zumindest die Pakete eingrenzen und
nach einem Thema suchen, das für Ihre Interessen relevant ist.
Zweitens gibt es eine großartige Website.
R-Dokumentation, eine Suchmaschine für Pakete und Funktionen von CRAN,
Bioconductor und GitHub, also
den drei großen Repositorys.
Wenn Sie eine Aufgabe im Kopf haben,
ist dies eine großartige Möglichkeit, nach bestimmten Paketen zu suchen, die Ihnen bei der Erfüllung dieser Aufgabe helfen.
Es hat auch eine Aufgabenansicht wie CRAN, mit der Sie Themen durchsuchen können.
Wenn Sie eine bestimmte Aufgabe im Sinn haben,
ist es häufiger ein guter Anfang, diese Aufgabe zu googeln, gefolgt vom R-Paket.
Von dort aus können Sie sich Tutorials, Vignetten
und Foren für Leute ansehen, die bereits das tun, was Sie
tun möchten, um relevante Pakete zu finden.
Großartig. Sie haben ein Paket gefunden, das Sie wollen.
Wie installiert man es?
Wenn Sie aus dem CRAN-Repository installieren,
verwenden Sie die Funktion „Pakete installieren“ mit dem Namen des
Pakets, das Sie installieren möchten, in Anführungszeichen zwischen den Klammern.
Beachten Sie, dass Sie entweder einfache oder doppelte Anführungszeichen verwenden können.
Wenn Sie beispielsweise das Paket ggplot2 installieren möchten,
verwenden Sie install.packages („ggplot2″).
Versuche das in deiner R Console.
Dieser Befehl lädt das Paket ggplot2 von CRAN herunter und installiert es auf Ihrem Computer.
Wenn Sie mehrere Pakete gleichzeitig installieren möchten,
können Sie dies tun, indem Sie einen Zeichenvektor verwenden, bei dem die Namen
der Pakete durch Kommas getrennt sind, wie hier formatiert.
Wenn Sie die grafische Oberfläche von RStudio verwenden möchten, um Pakete zu installieren,
rufen Sie das Menü Tools auf.
Die erste Option sollte Pakete installieren sein.
Wenn Sie von CRAN aus installieren,
wählen Sie das Repository aus und geben Sie die gewünschten Pakete in das entsprechende Feld ein.
Das Bioconductor-Repository verwendet eine eigene Methode, um Pakete zu installieren.
Verwenden Sie zunächst source (“ https://bioconductor.org/biocLite.R „), um die grundlegenden Funktionen zu erhalten, die für die Installation über Bioconductor erforderlich sind. Dadurch steht Ihnen
die Hauptinstallationsfunktion von Bioconductor BioClite zur Verfügung.
Danach rufen Sie das Paket, das Sie installieren möchten, in Anführungszeichen zwischen
den Klammern des BioClite-Befehls auf, wie hier für das GenomicRanges-Paket zu sehen ist.
Die Installation von GitHub ist
ein speziellerer Fall, auf den Sie wahrscheinlich nicht allzu oft stoßen werden.
Falls Sie dies tun möchten,
müssen Sie zuerst das gewünschte Paket auf GitHub
finden und sowohl den Paketnamen als auch den Autor des Pakets notieren.
Der allgemeine Arbeitsablauf besteht darin,
das Paket devtools nur dann zu installieren, wenn Sie devtools noch nicht installiert haben.
Wenn Sie diese Lektion befolgt haben,
haben Sie sie möglicherweise installiert, als wir Installationen mit der R-Konsole geübt haben.
Anschließend laden Sie das Paket devtools mithilfe der Bibliotheksfunktion SO.
Weitere Informationen zu diesem Befehl sind in wenigen Sekunden erledigt.
Verwenden Sie abschließend den Befehl install_github und
rufen Sie den GitHub-Benutzernamen des Autors gefolgt vom Paketnamen auf. Durch die
Installation eines Pakets stehen Ihnen dessen Funktionen nicht sofort zur Verfügung.
Zuerst müssen Sie das Paket in R laden.
Verwenden Sie dazu die Bibliotheksfunktion.
Stellen Sie sich das wie jede andere Software vor, die Sie auf Ihrem Computer installieren.
Nur weil Sie das Programm installiert haben, heißt das nicht, dass es automatisch läuft.
Sie müssen das Programm öffnen. Das
Gleiche gilt für R, du hast es installiert, aber jetzt musst du es öffnen.
Um beispielsweise das Paket ggplot2 zu öffnen,
würden Sie die Bibliotheksfunktion verwenden und sie ggplot2 nennen.
Hinweis: Setzen Sie den Paketnamen nicht in Anführungszeichen.
Im Gegensatz zur Installation der Pakete
akzeptiert der Bibliotheksbefehl keine Paketnamen in Anführungszeichen.
Es gibt eine Reihenfolge zum Laden von Paketen.
Bei einigen Paketen müssen zuerst andere Pakete geladen werden, auch bekannt als Abhängigkeiten.
Dieses Paket besteht aus Handbuch-/Hilfeseiten.
Wir helfen Ihnen dabei, diese Bestellung zu finden, wenn sie wählerisch sind.
Wenn Sie ein Paket über die RStudio-Schnittstelle laden möchten
,
gibt es im unteren rechten Quadranten eine Registerkarte namens Pakete, auf der alle Pakete in
einer kurzen Beschreibung sowie
die Versionsnummer aller von Ihnen installierten Pakete aufgeführt sind.
Um ein Paket zu laden, klicken Sie einfach auf das Kästchen neben dem Paketnamen.
Sobald Sie ein Paket erhalten haben, müssen
Sie möglicherweise einige Dinge wissen, wie Sie vorgehen müssen.
Wenn Sie sich nicht sicher sind, ob Sie
das Paket bereits installiert haben oder überprüfen möchten, ob Pakete installiert sind,
können Sie entweder die Befehle „Pakete installieren“ oder „library“
ohne Angabe in Klammern verwenden.
In RStudio
ist die zuvor eingeführte Paketregisterkarte eine weitere Möglichkeit, alle von Ihnen installierten Pakete anzuzeigen.
Sie können überprüfen, welche Pakete aktualisiert werden müssen, indem Sie die Funktionspakete aufrufen.
Dadurch werden alle Pakete identifiziert, die
seit Ihrer Installation/der letzten Aktualisierung aktualisiert wurden.
Um alle Pakete zu aktualisieren, verwenden Sie Aktualisierungspakete.
Wenn Sie nur ein bestimmtes Paket aktualisieren möchten,
verwenden Sie einfach erneut Pakete installieren.
In der RStudio-Oberfläche, die sich immer noch auf der Registerkarte Pakete befindet,
können Sie auf Aktualisieren klicken, wodurch alle Pakete aufgelistet werden, die nicht aktuell sind.
Sie haben die Möglichkeit, alle
Ihre Pakete zu aktualisieren oder bestimmte Pakete auszuwählen.
Sie sollten Ihre Pakete regelmäßig überprüfen
und überprüfen, ob Sie nicht mehr auf dem neuesten Stand sind. Seien Sie jedoch vorsichtig.
Manchmal kann ein Update die Funktionalität bestimmter Funktionen ändern.
Wenn Sie also alten Code erneut ausführen, wird
der Befehl möglicherweise geändert oder sogar ganz
entfernt, und Sie müssen Ihr CO2 aktualisieren.
Manchmal möchten Sie ein Paket mitten in einem Skript entladen.
Das Paket, das Sie geladen haben, funktioniert möglicherweise nicht gut mit einem anderen Paket, das Sie verwenden möchten.
Um ein bestimmtes Paket zu entladen,
können Sie die Funktion detach verwenden.
Sie würden beispielsweise detach
package:ggplot2 eingeben und dann unload entspricht true in dem angezeigten Format.
Dies würde das ggplot2-Paket entladen, das wir zuvor geladen haben.
In der RStudio-Oberfläche auf der Registerkarte Pakete
können Sie einfach ein Paket entladen, indem Sie das Kontrollkästchen neben dem Paketnamen deaktivieren.
Wenn Sie ein Paket nicht mehr installiert haben möchten,
können Sie es einfach mit der Funktion Removed.packages deinstallieren.
Entferne zum Beispiel Pakete, gefolgt von ggplot2, versuche das.
Aber dann habe ich das Paket ggplot2 tatsächlich neu installiert.
Es ist ein sehr nützliches Plotpaket. Wenn Sie
in RStudio auf der Registerkarte Pakete
auf das X am Ende der Zeile eines Pakets klicken, wird dieses Paket deinstalliert.
Wenn Sie sich ein Paket ansehen, das Sie vielleicht installieren möchten,
werden Sie manchmal feststellen, dass eine bestimmte Version von R erforderlich ist, um ausgeführt zu werden.
Um zu wissen, ob Sie dieses Paket verwenden können,
müssen Sie wissen, welche Version von R Sie verwenden.
Eine Möglichkeit, Ihre R-Version zu ermitteln, besteht darin, zu überprüfen, wann Sie R oder RStudio zum ersten Mal öffnen.
Das erste, was es in der Konsole ausgibt,
sagt Ihnen, welche Version von R gerade läuft.
Wenn Sie am Anfang nicht aufgepasst haben,
können Sie Version in die Konsole eingeben und es werden
Informationen über die R-Version ausgegeben, die Sie ausführen.
Ein weiterer hilfreicher Befehl ist die Sitzungsinformation.
Es wird Ihnen sagen, welche Version von R Sie verwenden,
zusammen mit einer Liste aller Pakete, die Sie geladen haben.
Die Ausgabe dieses Befehls ist ein großartiges Detail
, das beim Posten einer Frage in Foren enthalten sein sollte.
Es gibt potenziellen Helfern viele Informationen über Ihr Betriebssystem
, R und die Pakete sowie deren Versionsnummern, die Sie verwenden.
In all diesen Informationen über Pakete
haben wir nicht wirklich besprochen, wie man die Funktionen eines Pakets benutzt.
Zunächst müssen Sie wissen, welche Funktionen in einem Paket enthalten sind.
Um dies zu tun, können Sie sich die Hilfeseiten ansehen, die in allen gut gemachten Paketen enthalten sind.
In der Konsole können Sie die Hilfefunktion verwenden, um auf die Hilfedatei eines Pakets zuzugreifen.
Versuchen Sie, die Hilfefunktion zu verwenden, die package equals
ggplot2 aufruft, und Sie werden all die vielen Funktionen sehen, die ggplot2 bietet.
Innerhalb der RStudio-Oberfläche
können Sie über die Registerkarte Pakete auf die Hilfedateien zugreifen. Wenn Sie
erneut auf einen Paketnamen klicken, sollten
diese zugehörigen Hilfedateien auf der Registerkarte Hilfe geöffnet werden
, die sich in demselben Quadranten neben der Registerkarte Pakete befindet.
Wenn Sie auf eine dieser Hilfeseiten klicken, gelangen Sie zur
Hilfeseite dieser Funktion, auf der Sie erfahren, wofür diese Funktion gedacht ist und wie Sie sie verwenden können.
Sobald Sie wissen, welche Funktion innerhalb eines Pakets Sie verwenden möchten,
rufen Sie sie einfach in der Konsole auf, wie
jede andere Funktion, die wir in dieser Lektion verwendet haben.
Sobald ein Paket geladen wurde,
ist es so, als wäre es Teil der Basisfunktionalität von R.
Wenn Sie immer noch Fragen dazu haben, welche Funktionen
innerhalb eines Pakets für Sie geeignet sind oder wie Sie sie verwenden können,
enthalten viele Pakete Vignetten.
Dies sind erweiterte Hilfedateien, die einen Überblick über das Paket und seine Funktionen enthalten,
aber oft gehen sie noch einen Schritt weiter und enthalten detaillierte Beispiele für
die Verwendung der Funktionen in einfachen Worten, denen Sie
folgen können, um zu sehen, wie das Paket verwendet wird.
Um die in einem Paket enthaltenen Vignetten zu sehen,
können Sie die Funktion browseVignettes verwenden.
Schauen wir uns zum Beispiel die in
ggplot2 enthaltenen Vignetten mit browseVignettes gefolgt von ggplot2 an. Sie sollten sehen, dass zwei enthaltene Vignetten enthalten sind.
Erweiterung der ggplot2- und Ästhetikspezifikation.
Das Erkunden der Vignette mit ästhetischen Spezifikationen ist ein gutes Beispiel dafür, wie
hilfreich Vignetten sein können. Klare Anweisungen zur Verwendung der enthaltenen Funktionen.
In dieser Lektion haben wir unsere Pakete eingehend untersucht.
Wir haben untersucht, was ein Paket ist und wie es sich von einer Bibliothek unterscheidet,
was Repositorien sind und wie Sie ein Paket finden, das für Ihre Interessen relevant ist.
Wir haben alle Aspekte der Funktionsweise von Paketen untersucht,
wie man sie aus den verschiedenen Repositorys installiert,
wie man sie lädt, wie man überprüft, welche Pakete installiert sind
und wie man Pakete aktualisiert, deinstalliert und entlädt.
Wir haben einen kleinen Umweg gemacht und uns angesehen, wie Sie die Version von R überprüfen können, die Sie
haben. Dies ist oft ein wichtiges Detail, das Sie bei der Installation von Paketen beachten sollten.
Schließlich haben wir einige Zeit damit verbracht, zu lernen, wie man Hilfedateien und
Vignetten untersucht, die Ihnen oft
eine gute Vorstellung davon geben, wie ein Paket und all seine Funktionen verwendet werden.
Projects in R
Eine der Möglichkeiten, wie Menschen ihre Arbeit in R organisieren, ist die Verwendung von R-Projekten.
Eine integrierte Funktion von R Studio, mit der Sie alle zugehörigen Dateien zusammenhalten können.
R Studio bietet eine großartige Anleitung zur Verwendung von Projekten.
Also, schau dir das auf jeden Fall an.
Zunächst einmal, was ist ein R-Projekt?
Wenn Sie ein Projekt erstellen,
wird ein Ordner erstellt, in dem alle Dateien gespeichert werden. Dies
ist hilfreich, um sich selbst
zu organisieren und mehrere Projekte voneinander zu trennen.
Wenn Sie ein Projekt erneut öffnen,
merkt sich R Studio, welche Dateien geöffnet waren, und stellt
die Arbeitsumgebung wieder her, als ob Sie sie nie verlassen hätten. Dies
ist sehr hilfreich, wenn Sie nach einer gewissen Pause mit der Sicherung eines Projekts beginnen.
Funktional gesehen wird beim Erstellen eines Projekts in R ein neuer Ordner erstellt und dieser
als Arbeitsverzeichnis zugewiesen, sodass alle
generierten Dateien demselben Verzeichnis zugewiesen werden.
Der Hauptvorteil der Verwendung von Projekten besteht darin, dass der Organisationsprozess richtig gestartet wird.
Es erstellt einen Ordner für Sie und jetzt haben Sie einen Ort, an dem Sie alle Ihre Eingabedaten,
Ihren Code und die Ausgabe Ihres Codes speichern können.
Alles, woran Sie innerhalb eines Projekts arbeiten, ist in sich abgeschlossen,
was oft bedeutet, dass es viel einfacher ist, Dinge zu finden.
Es gibt nur einen Ort, an dem man nachschauen kann.
Da sich alles, was mit einem Projekt zu tun hat, an derselben Stelle befindet,
ist es außerdem viel einfacher, Ihre Arbeit mit anderen zu teilen,
indem Sie entweder die Ordner-Slash-Dateien direkt teilen
oder indem Sie sie mit Versionskontrollsoftware verknüpfen.
In
einer zukünftigen Lektion, die ausschließlich dem Thema gewidmet ist, werden wir mehr über das Verknüpfen von Projekten in R mit Versionskontrollsystemen sprechen.
Und da R Studio sich merkt,
welche Dokumente Sie geöffnet haben, wenn Sie diese Sitzung schließen,
ist es einfacher, ein Projekt nach einer Pause wieder aufzunehmen.
Alles ist so eingerichtet, wie du es verlassen hast.
Es gibt drei Möglichkeiten, ein Projekt zu erstellen.
Erstens können Sie es von Grund auf neu erstellen.
Dadurch wird ein neues Verzeichnis erstellt, in das alle Ihre Dateien aufgenommen werden können.
Oder Sie können ein Projekt aus einem vorhandenen Ordner erstellen.
Dadurch wird ein vorhandenes Verzeichnis mit R Studio verknüpft.
Schließlich können Sie ein Projekt von der Versionskontrolle aus verknüpfen.
Dadurch wird ein vorhandenes Projekt auf Ihren Computer geklont.
Mach dir darüber keine allzu großen Sorgen. In den
nächsten Lektionen werden Sie sich damit besser vertraut machen.
Lassen Sie uns ein Projekt von Grund auf neu erstellen,
was Sie oft tun werden.
Öffnen Sie R Studio und wählen Sie unter „Datei“ die Option „Neues Projekt“ aus.
Sie können auch ein neues Projekt erstellen, indem Sie
die Projekt-Werkzeugleiste verwenden und im Drop-down-Menü Neues Projekt auswählen,
oder es gibt eine neue Projektverknüpfung in der Werkzeugleiste.
Da wir bei Null anfangen, wählen Sie „Neues Verzeichnis“.
Wenn Sie nach dem Projekttyp gefragt werden, wählen Sie „Neues Projekt“.
Wählen Sie einen Namen für Ihr Projekt und
speichern Sie es für diese Zeit auf Ihrem Desktop.
Dadurch wird ein Ordner auf Ihrem Desktop erstellt, in dem alle
mit diesem Projekt verknüpften Dateien gespeichert werden.
Klicken Sie auf Projekt erstellen.
Eine leere R Studio-Sitzung sollte geöffnet werden.
Ein paar Dinge, die Sie beachten sollten.
Erstens
können Sie im Dateiquadranten des Bildschirms sehen, dass R Studio dieses neue Verzeichnis,
Ihr Arbeitsverzeichnis, erstellt und eine einzelne Datei mit der Erweiterung „R project“ generiert hat.
Zweitens befindet sich oben rechts im Fenster die Werkzeugleiste eines Projekts, die den Namen Ihres aktuellen Projekts enthält und über ein Dropdownmenü mit einigen verschiedenen Optionen verfügt, über die wir gleich sprechen werden. Das
Öffnen eines vorhandenen Projekts ist so einfach wie ein
Doppelklick auf die R Project-Datei auf Ihrem Computer.
Sie können dasselbe in R Studio tun, indem Sie
R Studio öffnen, zur Datei gehen und dann das Projekt öffnen.
Sie können auch die Projekt-Werkzeugleiste verwenden und
das Drop-down-Menü öffnen und „Projekt öffnen“ auswählen.
Das Beenden eines Projekts ist so einfach wie das Schließen Ihres R Studio-Fensters.
Sie können auch zur Datei „Projekt schließen“ gehen, und das wird dasselbe tun.
Schließlich können Sie die Projekt-Werkzeugleiste verwenden,
indem Sie auf das Drop-down-Menü klicken und Geschlossenes Projekt auswählen.
All diese Optionen beenden ein Projekt und
dadurch schreibt R Studio, welche Dokumente
gerade geöffnet sind, sodass sie wiederhergestellt werden können, wenn Sie das
Backup erneut starten und dann die R-Sitzung schließen.
Wenn Sie Ihr Projekt einrichten,
können Sie ihm sagen, dass es die Umwelt schonen soll.
So werden beispielsweise alle Ihre Variablen in
Datentabellen vorgeladen, wenn Sie das Projekt erneut öffnen,
aber das ist nicht das Standardverhalten.
Die Projekt-Werkzeugleiste ist auch eine einfache Möglichkeit, zwischen Projekten zu wechseln.
Klicken Sie auf das Drop-down-Menü und wählen Sie „
Projekt öffnen“ und suchen Sie Ihr neues Projekt, das Sie öffnen möchten.
Dadurch wird das aktuelle Projekt gespeichert,
geschlossen und dann das neue Projekt im selben Fenster geöffnet.
Wenn Sie möchten, dass mehrere Projekte gleichzeitig geöffnet werden,
tun Sie dasselbe,
wählen Sie jedoch stattdessen „Projekt in neuer Sitzung öffnen“.
Dies kann auch über das Dateimenü erreicht werden,
in dem dieselben Optionen verfügbar sind.
Wenn Sie ein Projekt einrichten,
kann es hilfreich sein, zunächst einige Verzeichnisse zu erstellen.
Probieren Sie ein paar Strategien aus und finden Sie heraus, was für Sie am besten funktioniert.
Die meisten Dateistrukturen sind jedoch so eingerichtet, dass sie ein Verzeichnis haben, das die Rohdaten enthält.
Ein Verzeichnis, in dem Sie Slash R-Dateien mit Schrägstrichen speichern,
und ein Verzeichnis für die Ausgabe Ihres Codes.
Wenn Sie diese Felsbrocken aufstellen, bevor Sie beginnen,
können Sie sich später in
einem Projekt organisatorische Kopfschmerzen ersparen, wenn Sie sich nicht mehr genau erinnern können, wo sich etwas befindet.
In dieser Lektion haben wir behandelt, was Projekte in R sind.
Warum Sie sie vielleicht verwenden möchten, wie Sie
Projekte öffnen, schließen oder zwischen ihnen wechseln und
einige bewährte Methoden, um sich am besten selbst zu organisieren.
Versionskontrolle
Nachdem wir unser RStudio und unsere Projekte im Griff haben,
möchten wir Sie noch
mit ein paar weiteren Dingen vertraut machen, bevor wir zu den anderen Kursen übergehen, die
Versionskontrolle verstehen, Git installieren
und Git mit RStudio verknüpfen.
In dieser Lektion vermitteln wir Ihnen ein grundlegendes Verständnis der Versionskontrolle.
Das Wichtigste zuerst: Was ist Versionskontrolle?
Versionskontrolle ist ein System, das
Änderungen aufzeichnet, die im Laufe der Zeit an einer Datei oder einer Reihe von Dateien vorgenommen werden.
Während Sie Änderungen vornehmen, erstellt das Versionskontrollsystem Schnappschüsse
Ihrer Dateien und der Änderungen und speichert diese Snapshots dann, sodass Sie darauf zurückgreifen und bei Bedarf
später zu früheren Versionen zurückkehren können.
Wenn Sie jemals die Funktion zum Verfolgen von Änderungen in Microsoft Word verwendet
haben, kennen Sie eine rudimentäre Art der Versionskontrolle, bei der die Änderungen an einer Datei
nachverfolgt werden und Sie
diese Änderungen entweder beibehalten oder zum Originalformat zurückkehren können.
Versionskontrollsysteme wie Git sind insofern ausgefeiltere
Track-Änderungen, sie sind weitaus leistungsfähiger und in der Lage, aufeinanderfolgende Änderungen an
vielen Dateien akribisch zu verfolgen, wobei potenziell viele Personen
gleichzeitig an denselben Dateigruppen arbeiten.
Hoffentlich
gehört finaldoc.docx für Sie der Vergangenheit an, sobald Sie Versionskontrollsoftware beherrschen, Paper Final Two.
Wie wir in diesem Beispiel gesehen haben,
behalten Sie ohne Versionskontrolle möglicherweise mehrere,
sehr ähnliche Kopien einer Datei, was gefährlich sein kann.
Möglicherweise beginnen Sie mit der Bearbeitung der falschen Version, ohne zu
erkennen, dass das Dokument mit der Bezeichnung
final bis zu den letzten beiden weiterbearbeitet wurde und jetzt alle Ihre neuen Änderungen
auf die falsche Datei angewendet wurden.
Versionskontrollsysteme helfen, dieses Problem zu lösen, indem sie
eine einzige aktualisierte Version jeder Datei mit einer Aufzeichnung
aller früheren Versionen und einer Aufzeichnung der genauen Änderungen zwischen
den Versionen führen, was uns zum nächsten großen Vorteil der Versionskontrolle bringt.
Es zeichnet alle Änderungen auf, die an den Dateien vorgenommen wurden.
Dies kann sehr hilfreich sein, wenn Sie mit vielen Personen an denselben Dateien zusammenarbeiten.
Die Versionskontrollsoftware verfolgt, wer
, wann und warum diese spezifischen Änderungen vorgenommen wurden.
Es ist wie Streckenwechsel bis zum Äußersten.
Dieser Datensatz ist auch bei der Entwicklung von Code hilfreich.
Wenn Sie nach einiger Zeit feststellen, dass Sie einen Fehler gemacht und einen Fehler eingeführt
haben, können Sie herausfinden, wann Sie das letzte Mal den bestimmten Code bearbeitet haben, die
Änderungen sehen, die Sie vorgenommen haben, und zum ursprünglichen,
ununterbrochenen Code zurückkehren und alles andere, was Sie in der Zwischenzeit getan haben, unverändert lassen.
Schließlich
ist die Versionskontrolle hilfreich, wenn Sie mit einer Gruppe von Personen an denselben Dateien arbeiten, um sicherzustellen, dass Sie keine
Änderungen an Dateien vornehmen, die mit anderen Änderungen in Konflikt stehen.
Wenn Sie schon einmal ein Dokument mit einer anderen Person zur Bearbeitung geteilt haben,
wissen Sie, wie frustrierend es ist, deren Änderungen in
ein Dokument zu integrieren, das sich seit dem Senden der Originaldatei geändert hat.
Jetzt haben Sie zwei Versionen desselben Originaldokuments. Die
Versionskontrolle ermöglicht es mehreren Personen, an derselben Datei zu arbeiten, und hilft dann dabei,
alle Versionen der Datei und all ihre Änderungen in einer zusammenhängenden Datei zusammenzuführen.
Git ist ein kostenloses Open-Source-Versionskontrollsystem.
Es wurde 2005 entwickelt und ist seitdem
das am häufigsten verwendete Versionskontrollsystem.
Stack Overflow, das Ihnen aus unserer Lektion „Hilfe holen“ bekannt vorkommen sollte,
befragte über 60.000 Befragte zu dem von ihnen verwendeten Versionskontrollsystem.
Wie Sie der Tabelle entnehmen können,
ist Git mit Abstand der Gewinner.
Wenn Sie sich mit Git und der Funktionsweise von Benutzeroberflächen mit Ihren Projekten vertraut machen
, werden Sie verstehen, warum es so beliebt geworden ist.
Einer der Hauptvorteile von Git ist, dass es
eine lokale Kopie deiner Arbeit und deiner Revisionen speichert, die du dann offline vernetzen kannst.
Sobald Sie dann zum Internetdienst zurückkehren,
können Sie Ihre Kopie des Werks mit all
Ihren neuen Änderungen synchronisieren und Änderungen am Hauptrepositorium online verfolgen.
Da alle Mitarbeiter an einem Projekt ihre eigene lokale Kopie des Codes hatten,
kann außerdem jeder gleichzeitig an seinen eigenen Teilen des
Codes arbeiten, ohne das gemeinsame Repository zu stören.
Ein weiterer großer Vorteil, den wir auf jeden Fall nutzen werden, ist
die einfache Schnittstelle zwischen RStudio und Git.
In der nächsten Lektion werden wir daran arbeiten, Git zu
installieren und mit RStudio zu verknüpfen und ein GitHub-Konto zu erstellen.
GitHub ist eine Online-Schnittstelle für Git.
Git ist eine Software, die lokal auf Ihrem Computer verwendet wird, um Änderungen aufzuzeichnen.
GitHub ist ein Host für deine Dateien und die Aufzeichnungen der vorgenommenen Änderungen.
Sie können es sich als ähnlich wie Dropbox vorstellen.
Die Dateien befinden sich auf Ihrem Computer, werden aber auch
online gehostet und sind von vielen Computern aus zugänglich.
GitHub hat den zusätzlichen Vorteil einer Schnittstelle mit Git, um den
Überblick über all Ihre Dateiversionen und Änderungen zu behalten.
Die Arbeit mit Git erfordert viel Vokabular und
oft hängt das Verständnis eines Wortes davon ab, dass
Sie ein anderes Git-Konzept verstehen.
Nehmen Sie sich etwas Zeit, um sich mit den folgenden Wörtern vertraut zu machen,
und gehen Sie sie einige Male durch, um zu sehen, wie die Konzepte zusammenhängen.
Ein Repository entspricht dem Projektordner oder -verzeichnis.
Alle Ihre versionskontrollierten Dateien und
die aufgezeichneten Änderungen befinden sich in einem Repository.
Dies wird oft auf Repo abgekürzt.
Repositorys werden auf GitHub gehostet. Über diese Schnittstelle können Sie
Ihre Repositorys entweder privat halten und sie mit
ausgewählten Mitarbeitern teilen oder sie öffentlich machen.
Jeder kann Ihre Dateien in seinem Verlauf sehen.
Bestätigen bedeutet, Ihre Änderungen und die vorgenommenen Änderungen zu speichern.
Ein Commit ist wie eine Momentaufnahme Ihrer Dateien.
Git vergleicht die vorherige Version all deiner Dateien im Repo mit
der aktuellen Version und identifiziert diejenigen, die sich seitdem geändert haben.
Diejenigen, die sich nicht geändert haben
, behält die zuvor gespeicherte Datei unverändert bei.
Diejenigen, die sich geändert haben,
vergleicht die Dateien,
lädt die Änderungen und lädt die neue Version Ihrer Datei hoch.
Wir werden im nächsten Abschnitt darauf eingehen,
aber wenn Sie eine Datei übertragen,
begleiten Sie diese Dateiänderung in der Regel
mit einer kleinen Notiz darüber, was Sie geändert haben und warum.
Wenn wir über Versionskontrollsysteme sprechen,
stehen Commits im Mittelpunkt.
Wenn Sie einen Fehler finden,
setzen Sie Ihre Dateien auf einen früheren Commit zurück.
Wenn du sehen möchtest, was sich in einer Datei im Laufe der Zeit geändert hat,
vergleichst du die Commits und schaust dir die Nachrichten an, um zu sehen, warum und wer.
Pushen bedeutet, das Repository mit Ihren Änderungen zu aktualisieren.
Da bei Git Änderungen lokal vorgenommen werden müssen,
müssen Sie in der Lage sein, Ihre Änderungen mit dem gemeinsamen Online-Repository zu teilen.
Pushing sendet diese übergebenen Änderungen an
dieses Repository, sodass jetzt jeder Zugriff auf Ihre Änderungen hat.
Beim Pullen wird Ihre lokale Version des Repositorys auf
die aktuelle Version aktualisiert, da in der Zwischenzeit möglicherweise andere Änderungen vorgenommen haben.
Da das gemeinsame Repository online
bei einem Ihrer Mitarbeiter oder sogar bei Ihnen selbst
auf einem anderen Computer gehostet wird, könnte es Änderungen an
den Dateien vornehmen und sie dann in das gemeinsame Repository übertragen.
Sie hinken der Zeit hinterher,
die Dateien, die Sie lokal auf Ihrem Computer haben, sind möglicherweise veraltet.
Sie ziehen also, um zu überprüfen, ob Sie mit dem Haupt-Repository auf dem neuesten Stand waren.
Ein letzter Begriff, den du kennen musst, ist Staging
, also das Vorbereiten einer Datei für einen Commit.
Wenn Sie beispielsweise seit Ihrem letzten Commit
drei Dateien aus völlig unterschiedlichen Gründen bearbeitet haben,
möchten Sie nicht alle Änderungen
auf einmal übernehmen. Ihre Nachricht, warum Sie die Änderung übernehmen, wird
kompliziert sein, da drei Dateien aus unterschiedlichen Gründen geändert wurden.
Stattdessen können Sie nur eine der Dateien bereitstellen und sie für die Übertragung vorbereiten.
Sobald Sie diese Datei festgeschrieben haben,
können Sie die zweite Datei bereitstellen und sie festschreiben und so weiter.
Staging ermöglicht es dir, Dateiänderungen in separate Commits aufzuteilen, was sehr hilfreich ist.
Um diese
bisher häufig verwendeten Begriffe zusammenzufassen und zu testen, ob Sie den Dreh raus haben,
werden Dateien in einem Repository gehostet, das online mit Mitarbeitern geteilt wird.
Sie rufen den Inhalt des Repositorys ab, sodass Sie
eine lokale Kopie der Dateien haben, die Sie bearbeiten können.
Sobald Sie mit Ihren Änderungen an einer Datei zufrieden sind, stellen
Sie die Datei bereit und übernehmen sie dann.
Sie übertragen diesen Commit in das gemeinsam genutzte Repository.
Dadurch werden Ihre neue Datei und alle Änderungen hochgeladen. Außerdem
wird eine Nachricht angezeigt, in der erklärt wird, was geändert wurde
, warum und von wem.
Eine Verzweigung liegt vor, wenn dieselbe Datei zwei gleichzeitige Kopien hat.
Als Sie lokal an der Bearbeitung einer Datei gearbeitet haben,
haben Sie einen Zweig erstellt, in dem Ihre Änderungen noch nicht mit dem Haupt-Repository geteilt wurden.
Es gibt also zwei Versionen der Datei.
Die Version, auf die jeder
im Repository Zugriff hat, und Ihre lokal bearbeitete Version der Datei.
Bis Sie Ihre Änderungen per Push übertragen und sie wieder in das Haupt-Repository zusammenführen,
arbeiten Sie an einem Zweig.
Nach einem Verzweigungspunkt
teilt sich der Versionsverlauf in zwei Teile auf und verfolgt
die unabhängigen Änderungen, die an beiden Originaldateien im
Repository vorgenommen wurden, die möglicherweise von anderen bearbeitet werden, und
Ihre Änderungen in Ihrem Zweig verfolgen, und führt die Dateien dann zusammen.
Beim Zusammenführen werden unabhängige Bearbeitungen derselben Datei
in eine einzige vereinheitlichte Datei integriert.
Unabhängige Änderungen werden von Git identifiziert und
in einer einzigen Datei zusammengefasst, in der beide Bearbeitungssätze enthalten sind.
Aber Sie können hier ein potenzielles Problem sehen.
Wenn beide Personen denselben Satz bearbeitet
haben, sodass eine der Änderungen nicht möglich ist, liegt ein Problem vor.
Git erkennt diese Ungleichheit und diesen
Konflikt und bittet die Benutzer um Unterstützung bei der Auswahl, welche Bearbeitung beibehalten werden soll.
Ein Konflikt liegt also vor, wenn mehrere Personen Änderungen
an derselben Datei vornehmen und Git die Änderungen nicht zusammenführen kann.
Sie haben die Möglichkeit, manuell zu versuchen,
die Änderungen zusammenzuführen oder eine Bearbeitung der anderen vorzuziehen.
Wenn Sie etwas klonen,
erstellen Sie eine Kopie eines vorhandenen Git-Repositorys.
Wenn Sie gerade zu einem Projekt weitergeleitet wurden, das mit der Versionskontrolle verfolgt wurde,
klonen Sie das Repository, um Zugriff auf alle Dateien des
Repositorys und aller Track-Änderungen zu erhalten und eine lokale Version dieser Dateien zu erstellen.
Ein Fork ist eine persönliche Kopie eines Repositorys, das Sie einer anderen Person entnommen haben.
Wenn jemand an einem coolen Projekt arbeitet und du damit herumspielen möchtest,
kannst du sein Repository forken und wenn du dann Änderungen vornimmst,
werden die Änderungen in deinem Repository protokolliert, nicht in seinem.
Es kann einige Zeit dauern, bis Sie sich an die Arbeit mit Versionskontrollsoftware wie Git gewöhnt haben,
aber es gibt ein paar Dinge, die
Sie beachten sollten, um gute Gewohnheiten zu entwickeln, die Ihnen in Zukunft helfen werden.
Eines dieser Dinge ist es, gezielte Verpflichtungen einzugehen.
Jeder Commit sollte nur als einzelnes Problem behandelt werden.
Wenn Sie also herausfinden müssen, wann Sie eine bestimmte Codezeile geändert haben,
gibt es nur einen Ort, an dem Sie nach
der Änderung suchen können, und Sie können leicht erkennen, wie Sie den Code rückgängig machen können.
Ebenso
ist es eine hilfreiche Angewohnheit, darauf zu achten, dass du bei jedem Commit formative Nachrichten schreibst.
Wenn in jeder Nachricht genau angegeben ist, was geändert wurde,
kann jeder die übergebene Datei überprüfen und den Zweck Ihrer Änderung ermitteln.
Wenn du nach einer bestimmten Bearbeitung suchst, die du in der Vergangenheit vorgenommen hast,
kannst du außerdem ganz einfach all deine Commits durchsuchen, um
die Änderungen zu identifizieren, die sich auf die gewünschte Änderung beziehen.
Achten Sie abschließend auf ihre Version der Dateien, an denen Sie gerade arbeiten.
Überprüfen Sie regelmäßig, ob Sie mit dem aktuellen Repo auf dem neuesten Stand sind, indem Sie häufig abrufen.
Horten Sie Ihre bearbeiteten Dateien außerdem nicht.
Sobald Sie Ihre Dateien gespeichert und diese hilfreiche Nachricht geschrieben haben,
sollten Sie diese Änderungen in das gemeinsame Repository übertragen.
Wenn Sie mit der Bearbeitung eines Codeabschnitts fertig sind und
vorhaben, sich mit einem Problem zu befassen, das nichts damit
zu tun hat, müssen Sie diese Änderung mit Ihren Mitarbeitern teilen. Nachdem
wir nun erklärt haben, was Versionskontrolle ist und welche Vorteile sie bietet,
sollten Sie verstehen können, warum wir
drei ganze Lektionen der Versionskontrolle und deren Installation gewidmet haben.
Wir haben uns angesehen, was Git und GitHub sind, und dann einen Großteil
des häufig verwendeten und manchmal verwirrenden Vokabulars behandelt, das der Arbeit mit der Versionskontrolle innewohnt.
Wir haben dann schnell einige Best Practices für die Verwendung von Git besprochen,
aber der beste Weg, das alles in den Griff zu bekommen, ist es, es zu verwenden.
Hoffentlich haben Sie das Gefühl, die Funktionsweise von Git jetzt besser im Griff zu haben. Fahren
wir also mit der nächsten Lektion fort und installieren sie.
Github und Git
Jetzt haben wir verstanden, was Versionskontrolle ist.
In dieser Lektion registrierst du dich für ein GitHub-Konto,
navigierst auf der GitHub-Website, um dich mit
einigen ihrer Funktionen vertraut zu machen, und installierst und konfigurierst Git.
Alles in Vorbereitung für die Verknüpfung beider mit Ihrem RStudio.
Wie wir bereits erfahren haben,
ist GitHub ein cloudbasiertes Managementsystem für Ihre versionskontrollierten Dateien.
Wie bei Dropbox befinden sich Ihre Dateien sowohl lokal auf
Ihrem Computer als auch online gehostet und sind leicht zugänglich.
Die Benutzeroberfläche ermöglicht die Verwaltung der Versionskontrolle und bietet
Benutzern eine webbasierte Oberfläche zum Erstellen,
Teilen, Aktualisieren von Code usw.
Um ein GitHub-Konto zu erhalten,
gehen Sie zunächst zu www.github.com.
Sie werden auf ihre Homepage weitergeleitet, wo Sie Ihre Daten eingeben,
einen Benutzernamen erstellen, Ihre E-Mail-Adresse eingeben,
ein sicheres Passwort wählen
und auf „Für GitHub registrieren“ klicken sollten.
Du solltest jetzt bei GitHub angemeldet sein.
Um sich in Zukunft bei GitHub anzumelden,
gehen Sie zu github.com, wo Ihnen eine Homepage angezeigt wird.
Wenn Sie noch nicht angemeldet sind,
klicken Sie oben auf den Anmeldelink.
Sobald Sie dies getan haben, wird die Anmeldeseite angezeigt, auf der Sie
Ihren zuvor erstellten Benutzernamen und Ihr Passwort eingeben.
Sobald Sie angemeldet sind, werden Sie wieder auf
github.com sein, aber dieses Mal sollte der Bildschirm so aussehen.
Wir werden einen kurzen Überblick über die GitHub-Website geben und
uns insbesondere auf diese Abschnitte der Benutzeroberfläche,
Benutzereinstellungen, Benachrichtigungen, Hilfedateien und des GitHub-Leitfadens konzentrieren.
Im Anschluss an diese Tour erstellen wir mithilfe des GitHub-Leitfadens Ihr allererstes Repository.
Schauen wir uns zunächst Ihre Benutzereinstellungen an.
Nachdem Sie sich bei GitHub angemeldet haben,
sollten wir einige
Ihrer Profilinformationen eingeben und uns mit den Kontoeinstellungen vertraut machen.
In der oberen rechten Ecke
befindet sich ein Symbol mit einem schmalen Symbol daneben.
Klicke darauf und gehe zu deinem Profil. Von
hier aus steuerst du dein Konto und kannst
deine Beiträge, Historien und Repositorys einsehen.
Da du gerade erst anfängst,
wirst du noch keine Repositorys oder Beiträge haben,
aber wir hoffen, dass wir das bald genug ändern werden.
Was wir jetzt tun können, ist Ihr Profil zu bearbeiten.
Gehen Sie am linken Seitenrand zum Bearbeiten des Profils.
Nehmen Sie sich hier etwas Zeit und geben Sie Ihren Namen
und eine kleine Beschreibung Ihrer Person in das Bio-Feld ein.
Wenn du möchtest, lade ein Bild von dir hoch.
Wenn Sie fertig sind, klicken Sie auf Profil aktualisieren.
Auf der linken Seite dieser Seite
gibt es viele Optionen, die Sie erkunden können.
Klicken Sie sich durch jedes dieser Menüs, um sich mit den verfügbaren Optionen vertraut zu machen.
Gehen Sie zur Kontoseite, um loszulegen.
Hier können Sie Ihr Passwort bearbeiten oder, wenn Sie mit Ihrem Benutzernamen nicht zufrieden sind, es ändern.
Seien Sie jedoch vorsichtig, es kann unbeabsichtigte Folgen haben, wenn Sie
Ihren Benutzernamen ändern, wenn Sie gerade erst anfangen und noch keine Inhalte haben.
Sie sind jedoch wahrscheinlich auf der sicheren Seite. Schauen
Sie sich die persönlichen Einstellungsmöglichkeiten weiterhin auf eigene Faust an.
Wenn du fertig bist, kehre zu deinem Profil zurück.
Sobald Sie etwas mehr Erfahrung mit GitHub gesammelt haben,
werden Sie irgendwann einige Repositorys auf Ihren Namen haben.
Um diese zu finden, klicken Sie in Ihrem Profil auf den Link Repositorys.
Vorerst wird es wahrscheinlich so aussehen.
Am Ende der Vorlesung kehren
Sie jedoch zu dieser Seite zurück, um Ihr neu erstelltes Repository zu finden.
Als Nächstes schauen wir uns das Benachrichtigungsmenü an.
In der Menüleiste oben in Ihrem Fenster
befindet sich ein Glockensymbol, das Ihre Benachrichtigungen darstellt.
Klicke auf die Glocke. Sobald du
auf GitHub aktiver wirst und mit anderen zusammenarbeitest,
findest du hier Nachrichten und Benachrichtigungen für alle Repositorys,
Teams und Konversationen, an denen du teilnimmst.
Am Ende jeder einzelnen Seite befindet sich die Hilfeschaltfläche.
GitHub verfügt über ein großartiges Hilfesystem.
Wenn Sie jemals eine Frage zu GitHub haben,
sollte dies Ihr erster Suchpunkt sein.
Nehmen Sie sich jetzt etwas Zeit und schauen Sie sich die verschiedenen Hilfedateien an und sehen Sie, ob Ihnen welche auffallen.
GitHub ist sich bewusst, dass dies für
neue Benutzer ein überwältigender Prozess sein kann, und hat daher ein Mini-Tutorial entwickelt, um Ihnen den Einstieg in GitHub zu erleichtern.
Gehen Sie jetzt diese Anleitung durch und erstellen Sie Ihr erstes Repository.
Wenn Sie fertig sind, sollten Sie ein Repository haben, das ungefähr so aussieht.
Nehmen Sie sich etwas Zeit, um das Repositorium zu erkunden.
Sieh dir deinen bisherigen Commit-Verlauf an.
Hier findest du alle Änderungen, die am
Projektarchiv vorgenommen wurden, und du kannst sehen, wer die Änderung vorgenommen hat,
wann die Änderung vorgenommen wurde
und sofern du eine entsprechende Commit-Nachricht geschrieben hast.
Sie können sehen, warum sie die Änderung vorgenommen haben.
Sobald Sie alle Optionen im Repository untersucht haben,
kehren Sie zu Ihrem Benutzerprofil zurück.
Es sollte ein bisschen anders aussehen als zuvor.
Wenn Sie sich jetzt in Ihrem Profil befinden,
können Sie Ihr zuletzt erstelltes Repository sehen.
Für eine vollständige Liste Ihrer Repositorys
klicken Sie auf den Tab Repositorys.
Hier siehst du all deine Repositorys,
eine kurze Beschreibung, den Zeitpunkt der letzten Bearbeitung
und auf der rechten Seite findest du
ein Aktivitätsdiagramm, das zeigt,
wie viele Änderungen am Repository vorgenommen wurden.
Wie Sie sich vielleicht aus unserer letzten Vorlesung erinnern,
ist Git das kostenlose Open-Source-Versionskontrollsystem, auf dem GitHub aufbaut.
Einer der Hauptvorteile der Verwendung des Git-Systems ist die Kompatibilität mit RStudio.
Um die beiden Programme miteinander zu verknüpfen,
müssen wir jedoch zuerst Git herunterladen und auf Ihrem Computer installieren.
Um Git herunterzuladen, gehe zu git-scm.com/download.
Klicken Sie auf den entsprechenden Download-Link für Ihr Betriebssystem.
Dies sollte den Download-Vorgang einleiten.
Wir werden uns zunächst den Installationsvorgang für
Windows-Computer ansehen und anschließend die Mac-Installationsschritte ausführen.
Folgen Sie den entsprechenden Anweisungen für Ihr Betriebssystem.
Öffnen Sie bei Windows-Computern nach Abschluss des Downloads die Datei the.exe, um den Installationsassistenten zu starten.
Wenn Sie eine Sicherheitswarnung erhalten,
klicken Sie auf Ausführen und auf Zulassen.
Klicken Sie sich anschließend durch den Installationsassistenten und
akzeptieren Sie im Allgemeinen die Standardoptionen, sofern Sie keinen triftigen Grund haben, dies nicht zu tun.
Klicken Sie auf Installieren und lassen Sie den Assistenten den Installationsvorgang abschließen.
Aktivieren Sie anschließend die Option Git Bash starten.
Wenn Sie nicht neugierig sind,
deaktivieren Sie das Feld Versionshinweise anzeigen, da Sie derzeit wahrscheinlich nicht daran interessiert sind.
Dadurch wird eine Befehlszeilenumgebung geöffnet.
Sofern du die Standardoptionen während des Installationsvorgangs akzeptiert hast,
wird es in Zukunft eine Startmenü-Verknüpfung geben, mit der du Git Bash starten kannst.
Sie haben jetzt Git installiert.
Für Macs führen wir Sie durch den gängigsten Installationsvorgang.
Es gibt jedoch mehrere Möglichkeiten, Git auf Ihren Mac zu bringen.
Du kannst den Tutorials
unter www.@lash.com /git/tutorials/installgitforalternativeinstallationrats folgen.
Nachdem Sie die entsprechende Git-Version für Macs
heruntergeladen haben, sollten Sie eine DMG-Datei zur Installation auf Ihrem Mac heruntergeladen haben. Öffne diese Datei.
Dadurch wird Git auf deinem Computer installiert. Es öffnet
sich ein neues Fenster.
Doppelklicken Sie auf die PKG-Datei und ein Installationsassistent wird geöffnet.
Klicken Sie sich durch die Optionen und akzeptieren Sie die Standardeinstellungen. Klicken Sie auf Installieren.
Wenn Sie dazu aufgefordert werden, schließen Sie den Installationsassistenten.
Du hast Git erfolgreich installiert.
Jetzt, wo Git installiert ist,
müssen wir es für die Verwendung mit GitHub konfigurieren, um es mit RStudio zu verknüpfen.
Wir müssen Git deinen Benutzernamen und deine E-Mail-Adresse mitteilen
, damit es weiß, wie jeder Commit benannt werden muss, der von dir kommt. Geben
Sie dazu in der Befehlszeile entweder Git Bash für Windows oder Terminal für Mac
git config –global
user.name „Jane Doe“ mit Ihrem gewünschten Benutzernamen anstelle von Jane Doe ein.
Dies ist der Name, mit dem jeder Commit gekennzeichnet wird.
Geben Sie anschließend in der Befehlszeile
git config –global user.email
janedoe@gmail.com ein und achten Sie darauf,
dieselbe E-Mail-Adresse zu verwenden, mit der Sie sich bei GitHub angemeldet haben.
An dieser Stelle sollten Sie für den nächsten Schritt bereit sein.
Aber nur um das zu überprüfen, bestätige deine Änderungen, indem du git config –list eingibst.
Dabei sollten dir der Benutzername und die E-Mail-Adresse angezeigt werden, die du oben ausgewählt hast.
Wenn Sie Probleme feststellen oder diese Werte ändern möchten,
geben Sie einfach die ursprünglichen Konfigurationsbefehle von zuvor mit den gewünschten Änderungen erneut ein.
Wenn Sie sicher sind, dass Ihr Benutzername und Ihre E-Mail-Adresse korrekt sind,
verlassen Sie die Befehlszeile, indem Sie exit eingeben und die Eingabetaste drücken.
An diesem Punkt sind Sie bereit für die nächste Vorlesung.
In dieser Lektion haben wir uns für ein GitHub-Konto angemeldet und die GitHub-Website besucht.
Wir haben dein erstes Repository erstellt und einige grundlegende Profilinformationen auf GitHub eingegeben.
Anschließend haben wir Git auf Ihrem Computer installiert und
für die Kompatibilität mit GitHub und RStudio konfiguriert.
Verknüpfung von Github und R Studio
Jetzt, da wir sowohl RStudio als auch Git auf Ihrem Computer in einem GitHub-Konto eingerichtet haben,
ist es an der Zeit, sie miteinander zu verknüpfen, damit Sie die
Vorteile der Verwendung von RStudio in Ihren Versionskontroll-Pipelines maximieren können.
Um RStudio in Git zu verknüpfen,
gehen Sie in RStudio zu Tools, dann zu Global Options, dann Git/SVN.
Manchmal ist der Standardpfad zur ausführbaren Git-Datei nicht korrekt.
Bestätigen Sie, dass sich git.exe in dem von RStudio angegebenen Verzeichnis befindet.
Wenn nicht, ändern Sie das Verzeichnis in den richtigen Pfad.
Andernfalls klicken Sie auf „Okay“ oder „Anwenden“.
Rstudio und Git sind jetzt verknüpft.
Um RStudio im selben RStudio-Optionsfenster mit GitHub zu verknüpfen,
klicken Sie auf „RSA-Schlüssel erstellen“ und, wenn der Vorgang abgeschlossen ist, auf „Schließen“.
Klicken Sie anschließend im selben Fenster erneut auf „Öffentlichen Schlüssel anzeigen“ und kopieren Sie die Zahlen- und Buchstabenfolge. Schließt dieses Fenster.
Sie haben jetzt einen für Sie spezifischen Schlüssel erstellt, den wir
GitHub zur Verfügung stellen, damit GitHub weiß, wer Sie sind, wenn Sie eine Änderung in RStudio vornehmen.
Gehen Sie dazu zu github.com,
melden Sie sich an, falls Sie dies noch nicht getan haben,
und gehen Sie zu Ihren Kontoeinstellungen.
Gehen Sie dort zu SSH- und GPG-Schlüsseln und klicken Sie auf „Neuer SSH-Schlüssel“.
Fügen Sie den öffentlichen Schlüssel, den Sie aus RStudio kopiert haben, in
das Schlüsselfeld ein und geben Sie ihm einen Titel, der sich auf RStudio bezieht.
Bestätige das Hinzufügen des Schlüssels mit deinem GitHub-Passwort.
GitHub und RStudio sind jetzt verknüpft.
Von hier aus können wir ein Repository auf GitHub erstellen und auf RStudio verlinken.
Gehe dazu zu GitHub und erstelle
ein neues Repository, indem du zu deinem Profil, Repositorys und Neu gehst.
Benennen Sie Ihr neues Test-Repository und geben Sie ihm eine kurze Beschreibung.
Klicken Sie auf „Repository erstellen“ und kopieren Sie die URL für Ihr neues Repository.
Gehen Sie in RStudio zu Datei, Neues Projekt,
wählen Sie Versionskontrolle und wählen Sie Git als Ihre Versionskontrollsoftware aus.
Fügen Sie die Repository-URL von zuvor ein und
wählen Sie den Speicherort aus, an dem das Projekt gespeichert werden soll.
Wenn Sie fertig sind, klicken Sie auf „Projekt erstellen“.
Dadurch wird ein neues Projekt initialisiert, das mit
dem GitHub-Repository verknüpft ist, und eine neue Sitzung von RStudio geöffnet.
Erstellen Sie ein neues R-Skript, indem Sie zu Datei, Neue Datei,
R-Skript gehen und den folgenden Code kopieren und einfügen:
print („Diese Datei wurde in RStudio erstellt“) und dann in eine neue Zeile einfügen,
drucken („Und jetzt lebt sie auf GitHub“).
Speichern Sie die Datei. Beachten Sie, dass sich
der Standardspeicherort für die Datei in dem
neuen Projektverzeichnis befindet, das Sie zuvor erstellt haben.
Sobald das erledigt ist,
sollten Sie, wenn Sie auf RStudio zurückblicken, im Git-Tab des Umgebungsquadranten Ihre gerade erstellte Datei sehen.
Klicken Sie auf das Kontrollkästchen unter Staged, um Ihre Datei zu speichern.
Klicke darauf. Es sollte sich ein neues Fenster öffnen,
in dem alle geänderten Dateien von früheren und nachfolgenden Dateien aufgeführt sind und die Unterschiede der Staging-Dateien zu früheren Versionen angezeigt werden.
Schreiben Sie sich im oberen Quadranten in das Nachrichtenfeld COMMIT eine Commit-Nachricht.
Klicken Sie auf Commit und schließen Sie das Fenster.
Bisher haben Sie eine Datei erstellt,
gespeichert, bereitgestellt und festgeschrieben.
Wenn du dich an deine Vorlesung
zur Versionskontrolle erinnerst, besteht der nächste Schritt darin, deine Änderungen in dein Online-Repository zu
übertragen, deine Änderungen in das GitHub-Repository zu übertragen,
zu deinem GitHub-Repository zu gehen und zu überprüfen, ob der Commit aufgezeichnet wurde.
Sie haben gerade erfolgreich Ihren ersten Commit aus RStudio auf GitHub übertragen.
In dieser Lektion haben wir Git und RStudio verknüpft, sodass
RStudio erkennt, dass Sie es als Ihre Versionskontrollsoftware verwenden.
Anschließend haben wir RStudio mit GitHub verknüpft,
sodass Sie Repositorys von RStudio aus verschieben und abrufen können.
Um dies zu testen, haben wir ein Repository auf GitHub erstellt,
es mit einem neuen Projekt in RStudio verknüpft,
eine neue Datei erstellt und die Datei dann bereitgestellt,
festgeschrieben und in Ihr GitHub-Repository übertragen.
Projects under Version Control
In der vorherigen Lektion
haben wir RStudio mit Git und GitHub verknüpft.
Dabei haben wir ein Repository auf GitHub erstellt und es mit RStudio verknüpft.
Manchmal haben Sie jedoch möglicherweise bereits ein R-Projekt, das
noch nicht unter Versionskontrolle steht oder mit GitHub verknüpft ist. Lass uns das reparieren.
Was ist, wenn Sie bereits ein R-Projekt haben, an dem Sie gearbeitet
haben, es aber nicht mit einer entsprechenden Versionskontrollsoftware verknüpft haben?
Zum Glück erkennen RStudio und GitHub, dass dies passieren kann, und haben Maßnahmen ergriffen, um Ihnen zu helfen.
Zugegeben, das ist etwas mühsamer, als nur
ein Repository auf GitHub zu erstellen und es mit RStudio zu verknüpfen, bevor das Projekt gestartet wird.
Lassen Sie uns also zunächst eine Situation einrichten, in der wir
ein lokales Projekt haben, das nicht unter Versionskontrolle steht.
Gehen Sie zu Datei, Neues Projekt,
Neues Verzeichnis, Neues Projekt und geben Sie Ihrem Projekt einen Namen.
Da wir versuchen, eine Zeit zu emulieren, in der Sie
ein Projekt haben, das derzeit nicht unter Versionskontrolle steht,
klicken Sie nicht auf Git-Repository erstellen, sondern auf Projekt erstellen.
Wir haben jetzt ein R-Projekt erstellt, das derzeit nicht unter Versionskontrolle steht.
Lass uns das reparieren. Richten wir es zunächst für die Interaktion mit Git ein.
Öffne Git Bash oder Terminal und navigiere zu dem Verzeichnis, das deine Projektdateien enthält.
Navigieren Sie in Verzeichnissen, indem Sie CD als Verzeichnis ändern eingeben,
gefolgt vom Pfad des Verzeichnisses.
Wenn die Befehlszeile in der Zeile vor
dem Dollarzeichen den richtigen Standort Ihres Projekts angibt,
befinden Sie sich an der richtigen Position.
Sobald Sie hier sind, geben Sie git init gefolgt von GitHub period ein.
Dadurch wird dieses Verzeichnis als Git-Repository initialisiert und
alle Dateien im Verzeichnis werden Ihrem lokalen Repository hinzugefügt.
Übertrage diese Änderungen mit git commit dash m initial commit in das Git-Repository.
Zu diesem Zeitpunkt haben wir
ein R-Projekt erstellt und es nun mit der Git-Versionskontrolle verknüpft.
Der nächste Schritt besteht darin, dies mit GitHub zu verknüpfen.
Gehen Sie dazu zu github.com.
Erstellen Sie erneut ein neues Repository.
Stellen Sie sicher, dass der Name genau mit Ihrem R-Projekt übereinstimmt, und
initialisieren Sie nicht die Readme-Datei, Gitignore oder Lizenz.
Sobald Sie dieses Repository erstellt haben,
sollten Sie sehen, dass es eine Option gibt, ein vorhandenes Repository von
der Befehlszeile aus zu übertragen. Die folgenden Anweisungen enthalten Code dazu.
Kopiere diese Codezeilen in Git Bash oder Terminal und füge sie ein, um dein Repository mit GitHub zu verknüpfen.
Aktualisiere danach deine GitHub-Seite und sie sollte jetzt ungefähr so aussehen.
Wenn Sie Ihr Projekt erneut in RStudio öffnen,
sollten Sie jetzt Zugriff auf den Git-Tab im oberen rechten Quadranten haben und alle zukünftigen Änderungen von
RStudio aus auf GitHub übertragen können.
Wenn es ein bestehendes Projekt gibt, an
dem andere arbeiten und zu dem Sie aufgefordert werden, einen Beitrag zu leisten,
können Sie das bestehende Projekt mit Ihrem RStudio verknüpfen.
Es folgt genau den gleichen Prämissen wie in der letzten Lektion, in der Sie
ein GitHub-Repository erstellt und es dann mit RStudio auf Ihren lokalen Computer geklont haben.
Kurz gesagt,
gehen Sie in RStudio zu Datei, Neues Projekt, Versionskontrolle.
Wählen Sie Git als Versionskontrollsystem aus
und
geben Sie wie in der letzten Lektion die URL zu dem Repository an, das Sie
klonen möchten, und wählen Sie einen Speicherort auf Ihrem Computer aus, um die Dateien lokal zu speichern.
Erstellen Sie das Projekt.
Alle vorhandenen Dateien im Repository sollten jetzt lokal auf
Ihrem Computer gespeichert sein und Sie haben die Möglichkeit, sie von Ihrer RStudio-Oberfläche aus zu übertragen.
Der einzige Unterschied zur letzten Lektion besteht darin, dass Sie
das ursprüngliche Repository nicht erstellt haben.
Stattdessen hast du die von jemand anderem geklont.
In dieser Lektion haben wir erklärt, wie Sie
ein vorhandenes Projekt mithilfe der Befehlszeile so konvertieren, dass es unter Git-Versionskontrolle steht.
Anschließend haben wir
Ihr neues versionskontrolliertes Projekt
mithilfe einer Mischung aus GitHub-Befehlen in der Befehlszeile mit GitHub verknüpft.
Anschließend fassen wir kurz zusammen, wie Sie mit
RStudio ein vorhandenes GitHub-Repository auf Ihren lokalen Computer klonen.
R Markdown
Wir haben viel Zeit damit verbracht, R und RStudio zum Laufen zu bringen und
etwas über Projekte und Versionskontrolle zu lernen.
Darin sind Sie praktisch ein Experte.
Es gibt eine letzte wichtige Funktion unseres Slash R Studio, die wir
nicht in Ihre Einführung in R aufnehmen würden: Markdown.
R Markdown ist eine Möglichkeit,
vollständig reproduzierbare Dokumente zu erstellen, in denen sowohl Text als auch Code kombiniert werden können.
Tatsächlich wurden diese Lektionen mit R Markdown geschrieben.
So erstellen wir Dinge wie Aufzählungslisten,
fett und kursiv gedruckten Text,
Inline-Links und führen Inline-R-Code aus.
Am Ende dieser Lektion
sollten Sie in der Lage sein, all diese Dinge und noch mehr zu tun.
Obwohl diese Dokumente alle als einfacher Text beginnen,
können Sie sie in HTML-Seiten oder PDF oder
Word-Dokumente oder Folien rendern.
Die Symbole, mit denen Sie beispielsweise
fett oder kursiv signalisieren, sind mit all diesen Formaten kompatibel.
Einer der Hauptvorteile ist die Reproduzierbarkeit der Verwendung von R Markdown.
Da Sie Text- und Codeblöcke problemlos in einem Dokument kombinieren können,
können Sie Einführungen, Hypothesen, den
von Ihnen ausgeführten Code, die Ergebnisse dieses Codes
und Ihre Schlussfolgerungen problemlos in einem Dokument integrieren.
Es
wird so einfach, zu teilen, was Sie getan haben, warum Sie es getan haben und wie es ausgegangen ist,
und die Person, mit der Sie es teilen, kann
Ihren Code erneut ausführen und genau die gleichen Antworten erhalten, die Sie erhalten haben.
Das meinen wir mit Reproduzierbarkeit.
Manchmal arbeiten Sie aber auch an einem Projekt, dessen Fertigstellung viele Wochen in Anspruch nimmt.
Sie möchten sehen können, was Sie vor langer Zeit getan haben,
und vielleicht genau daran erinnert werden, warum Sie das getan haben.
Und Sie können genau sehen, was Sie ausgeführt haben und welche Ergebnisse dieser Code hat,
und mit R Markdown-Dokumenten können Sie das tun.
Ein weiterer großer Vorteil von R Markdown ist, dass es, da es sich um einfache Texte
handelt, sehr gut mit Versionskontrollsystemen funktioniert.
Im Gegensatz zu anderen Formaten, die im Klartext vorliegen, ist es einfach nachzuverfolgen, welche Zeichenänderungen zwischen Commits auftreten.
Zum Beispiel
habe ich in einer Version dieser Lektion vielleicht vergessen, „dieses“ Wort fett zu schreiben.
Wenn ich meinen Fehler erkenne,
kann ich den Klartext ändern, um zu signalisieren, dass das Wort fett gedruckt werden soll,
und im Commit können Sie die
genauen Zeichenänderungen sehen, die vorgenommen wurden, sodass das Wort jetzt fett gedruckt wird.
Ein weiterer egoistischer Vorteil von R Markdown ist die einfache Bedienung.
Wie alles in R stammt diese erweiterte Funktionalität aus einem R-Paket: rmarkdown.
Alles, was Sie tun müssen, um es zu installieren, ist install.packages R Markdown auszuführen
, und fertig. Du bist bereit zu gehen.
Um ein R Markdown-Dokument in Rstudio zu erstellen,
gehen Sie zu Datei, Neue Datei, R Markdown.
Dieses Fenster wird Ihnen angezeigt.
Ich habe einen Titel und einen Autor eingegeben und das Ausgabeformat auf PDF umgestellt.
Erkunden Sie dieses Fenster und die Tabs auf der linken Seite
, um all die verschiedenen Formate zu sehen, die Sie auch ausgeben können.
Wenn Sie fertig sind, klicken Sie auf OK.
Ein neues Fenster sollte sich mit einer kleinen Erklärung zu R Markdown-Dateien öffnen.
Es gibt drei Hauptabschnitte eines R Markdown-Dokuments.
Die erste ist die Kopfzeile oben, die durch die drei Bindestriche begrenzt wird.
Hier können Sie Details wie den Titel,
Ihren Namen, das Datum
und die Art des Dokuments angeben, das Sie ausgeben möchten.
Wenn Sie die Lücken im Fenster zuvor ausgefüllt haben,
sollten diese für Sie ausgefüllt werden.
Auf dieser Seite
können Sie auch Textabschnitte sehen.
Ein Abschnitt beginnt beispielsweise mit ## R Markdown.
Wir werden gleich mehr darüber sprechen, was das bedeutet,
aber dieser Abschnitt wird als Text gerendert, wenn Sie das PDF dieser Datei erstellen,
und alle Formatierungen, die Sie lernen werden, gelten im Allgemeinen für diesen Abschnitt.
Schließlich werden Sie Code-Chunks sehen.
Diese werden durch die Dreifachrückentexte begrenzt.
Dies sind Teile unserer Code-Chunks, die Sie direkt in Ihrem Dokument ausführen können,
und die Ausgabe dieses Codes wird in das PDF aufgenommen, wenn Sie es erstellen.
Der einfachste Weg, um zu sehen, wie sich die einzelnen Abschnitte verhalten, besteht darin, das PDF zu erstellen.
Wenn Sie mit einem Dokument in R Markdown
fertig sind, können Sie Ihren Klartext und Code in Ihr endgültiges Dokument einbinden.
Klicken Sie dazu oben im Quellfenster auf die Schaltfläche Stricken.
Wenn Sie dies tun, werden Sie aufgefordert, das Dokument als RMD-Datei zu speichern. Tun Sie dies.
Sie sollten ein Dokument wie dieses sehen.
Hier können Sie also sehen, dass der Inhalt einer Kopfzeile in einen Titel gerendert wurde,
gefolgt von Ihrem Namen und dem Datum.
Die Textblöcke erzeugten eine Abschnittsüberschrift namens R Markdown,
die für zwei Textabsätze gültig ist.
Danach sehen Sie den R-Code, die
Zusammenfassung (Cars), gefolgt von der Ausgabe der Ausführung dieses Codes.
Weiter unten sehen Sie Code, der ausgeführt wurde, um einen Plot zu erstellen, und dann diesen Plot.
Dies ist einer der großen Vorteile von R Markdown, da
die Ergebnisse in Inline-Code gerendert werden.
Gehen Sie zurück zu der R Markdown-Datei, die dieses PDF erstellt hat,
und sehen Sie, ob Sie sehen können, wie Sie Sie im Text bezeichnen, erstellen Sie es,
und schauen Sie sich das Wort Knit an und sehen Sie, wovon es umgeben ist.
Ich hoffe, wir haben Sie an dieser Stelle davon überzeugt, dass
R Markdown eine nützliche Methode ist, um Ihren Code/Ihre Daten zu behalten,
und Sie so eingerichtet haben, dass Sie damit herumspielen können.
Um Ihnen den Einstieg zu erleichtern, üben wir einige
der Formatierungen, die R Markdown-Dokumenten innewohnen.
Schauen wir uns zunächst die Fettschrift und Kursivschrift von Text an.
Um Text fett zu formatieren, umgeben Sie ihn auf beiden Seiten mit zwei Sternchen.
Um Text kursiv zu schreiben,
umgeben Sie das Wort auf beiden Seiten mit einem einzelnen Sternchen.
Wir haben auch anhand des Standarddokuments gesehen, dass Sie Abschnittsüberschriften erstellen können.
Dazu setzen Sie eine Reihe von Hashmarken.
Die Anzahl der Hashmarkierungen bestimmt, um welche Ebene der Überschrift es sich handelt.
Ein Hash ist die höchste Stufe und ergibt den größten Text.
Zwei Hashes sind die nächsthöhere Stufe und so weiter.
Spielen Sie mit dieser Formatierung herum und erstellen Sie eine Reihe von Überschriften.
Die andere Sache, die wir bisher gesehen haben, sind Code-Chunks.
Um einen R-Code-Block zu erstellen,
können Sie die drei hinteren Häkchen eingeben,
gefolgt von den geschweiften Klammern, die ein kleines
R umgeben. Fügen Sie Ihren Code in eine neue Zeile ein und beenden Sie den Block mit drei hinteren Häkchen.
Zum Glück weiß RStudio, dass Sie das oft tun würden, und es gibt Abkürzungen.
Nämlich Control, Alt, I für Windows.
Oder Befehl, Option, I für max.
Zusätzlich
befindet sich am oberen Rand des Quellquadranten die Schaltfläche „Einfügen“, die ebenfalls einen leeren Code-Chunk erzeugt.
Versuche, einen leeren Code-Chunk zu erstellen.
Geben Sie darin den Code Print ein, Hello world.
Wenn Sie Ihr Dokument benötigen,
werden Sie diesen Code-Chunk und die zugegebenermaßen vereinfachte Ausgabe dieses Chunks sehen.
Wenn Sie noch nicht bereit sind, Ihr Dokument zu stricken, aber die Ausgabe Ihres Codes sehen möchten,
wählen Sie die Codezeile aus, die Sie ausführen möchten, und
drücken Sie die Strg-/Eingabetaste oder klicken Sie oben im Quellfenster auf die Schaltfläche Ausführen.
Der Text Hello World sollte in Ihrem Konsolenfenster ausgegeben werden.
Wenn Sie mehrere Codezeilen in einem Block haben und sie alle auf einmal ausführen möchten,
können Sie den gesamten Chunk ausführen, indem Sie die Strg-
, Shift- oder Eingabetaste verwenden oder die grüne Pfeiltaste auf der rechten Seite des Chunks drücken
oder im Menü Ausführen die Option Aktuellen Chunk ausführen auswählen.
Eine letzte Sache, auf die wir näher eingehen werden, ist die Erstellung von Aufzählungslisten,
wie die oben in dieser Lektion.
Listen lassen sich einfach erstellen, indem jedem perspektivischen Aufzählungspunkt ein einzelner Bindestrich
gefolgt von einem Leerzeichen vorangestellt wird.
Wichtig ist, dass Sie am Ende jeder Aufzählungszeile
mit zwei Leerzeichen enden.
Dies ist eine Eigenart von R Markdown, die zu Abstandsproblemen führt, wenn sie nicht enthalten ist.
Dies ist ein guter Ausgangspunkt,
und mit R Markdown können Sie noch viel mehr tun.
Zum Glück haben die RStudio-Entwickler
einen R Markdown-Spickzettel erstellt, den wir Ihnen dringend empfehlen,
sich anzusehen und alles zu sehen, was Sie mit R Markdown machen können.
Der Himmel ist die Grenze.
In dieser Lektion haben wir uns
mit R Markdown befasst und damit begonnen, was es ist und warum Sie es vielleicht verwenden möchten.
Hoffentlich haben wir Ihnen den Einstieg in R Markdown ermöglicht,
indem wir es zuerst installiert
und dann unser erstes R Markdown-Dokument generiert und gestrickt haben.
Anschließend haben wir uns einige der verschiedenen Formatierungsoptionen angesehen, die Ihnen in der
Praxis zur Verfügung stehen, um Code zu generieren und ihn in der RStudio-Oberfläche auszuführen.
Arten von Data Science Fragen
In dieser Lektion werden wir etwas konzeptioneller vorgehen und uns
einige der Arten von Analysen ansehen, mit denen Datenwissenschaftler
Fragen in der Datenwissenschaft beantworten. Im
Großen und Ganzen gibt es sechs Kategorien, in die Datenanalysen fallen.
In der ungefähren Reihenfolge ihrer Schwierigkeitsgrade sind sie beschreibend, explorativ,
inferentiell, prädiktiv, kausal und mechanistisch.
Lassen Sie uns die Ziele der einzelnen Typen
untersuchen und uns einige Beispiele für jede Analyse ansehen.
Schauen wir uns zunächst die deskriptive Datenanalyse an.
Das Ziel der deskriptiven Analyse besteht darin, einen Datensatz zu beschreiben oder zusammenzufassen.
Wann immer Sie einen neuen Datensatz untersuchen müssen,
ist dies normalerweise die erste Art der Analyse, die Sie durchführen.
Die deskriptive Analyse liefert einfache Zusammenfassungen über die Proben und
ihre Messungen.
Möglicherweise sind Sie mit gängigen deskriptiven Statistiken vertraut,
einschließlich Messgrößen der zentralen Tendenz, z. B. Mittelwert, Median, Modus.
Oder Variabilitätsmaße, z. B. Bereich, Standardabweichungen oder Varianz.
Diese Art der Analyse zielt darauf ab, Ihre Stichprobe zusammenzufassen, nicht darauf,
die Ergebnisse der Analyse auf eine größere Population zu verallgemeinern oder Schlüsse
zu ziehen.
Die Beschreibung der Daten ist von der Interpretation getrennt.
Verallgemeinerungen und Interpretationen erfordern zusätzliche statistische Schritte.
Einige Beispiele für rein deskriptive Analysen finden sich in Volkszählungen.
Hier sammelt die Regierung eine Reihe von Messungen an allen
Bürgern des Landes, die dann zusammengefasst werden können.
Hier wird Ihnen die Altersverteilung in den USA angezeigt, stratifiziert nach Geschlecht.
Das Ziel ist nur, die Verteilung zu beschreiben.
Es gibt keine Rückschlüsse darauf, was dies bedeutet, oder
Vorhersagen darüber, wie sich die Daten in Zukunft entwickeln könnten.
Es dient nur dazu, Ihnen eine Zusammenfassung der gesammelten Daten zu zeigen.
Das Ziel der explorativen Analyse besteht darin, die Daten zu untersuchen oder zu untersuchen und
Zusammenhänge zu finden, die bisher nicht bekannt waren.
Explorative Analysen untersuchen, wie verschiedene Maßnahmen
miteinander in Beziehung stehen könnten, bestätigen jedoch nicht, dass ein kausaler Zusammenhang besteht.
Sie haben wahrscheinlich den Satz gehört, dass Korrelation keine Kausalität impliziert, und
explorative Analysen liegen diesem Sprichwort zugrunde.
Nur weil Sie bei der explorativen
Analyse eine Beziehung zwischen zwei Variablen beobachtet haben, heißt das nicht, dass die eine auch die andere verursacht.
Aus diesem Grund
sollten explorative Analysen zwar nützlich sein, um neue Zusammenhänge zu entdecken, aber nicht das letzte Wort bei der Beantwortung einer Frage sein.
Es kann Ihnen ermöglichen, Hypothesen zu formulieren und die Gestaltung zukünftiger Studien und
Datenerhebungen voranzutreiben.
Explorative Analysen allein sollten jedoch niemals als letzte Entscheidung darüber verwendet werden, warum oder
wie Daten miteinander in Beziehung stehen könnten.
Wenn wir zum Beispiel der Volkszählung von oben zurückkehren,
können wir nicht nur die Datenpunkte innerhalb einer einzigen Variablen zusammenfassen, sondern uns ansehen, wie zwei oder mehr Variablen miteinander in Beziehung stehen könnten.
In diesem Diagramm können wir sehen, wie viel Prozent der Erwerbsbevölkerung aus Frauen in
verschiedenen Sektoren bestehen, und wie sich dieser Anteil zwischen 2000 und 2016 verändert hat. Wenn wir
diese Daten untersuchen, können wir einige Zusammenhänge erkennen.
Wenn wir uns nur die oberste Zeile der Daten ansehen, können wir sehen, dass Frauen die
überwiegende Mehrheit der Krankenschwestern ausmachen und dass dieser Anteil in den letzten 16 Jahren leicht zurückgegangen ist.
Dies sind zwar interessante Zusammenhänge, aber
die Ursachen für diese Beziehung sind aus dieser Analyse nicht ersichtlich.
Alle explorativen Analysen können uns sagen, dass ein Zusammenhang besteht, nicht die Ursache.
Das Ziel der Inferenzanalyse besteht darin, anhand einer relativ kleinen Datenstichprobe
etwas über die gesamte Population zu ermitteln oder daraus Schlüsse zu ziehen.
Inferenzanalyse ist häufig das Ziel statistischer Modelle.
Wo Sie eine kleine Menge an Informationen haben, um diese Informationen zu extrapolieren und für
eine größere Gruppe zu verallgemeinern.
Bei der Inferenzanalyse werden in der Regel die Daten verwendet, die Sie benötigen, um diesen
Wert in der Grundgesamtheit zu schätzen, und
dann ein Maß für die Unsicherheit in Bezug auf Ihre Schätzung angeben.
Da Sie von einer kleinen Datenmenge übergehen und versuchen, auf
eine größere Grundgesamtheit zu generalisieren,
hängt Ihre Fähigkeit, genaue Informationen über die größere Grundgesamtheit abzuleiten, stark von Ihrem Stichprobenschema ab.
Wenn die von Ihnen gesammelten Daten nicht aus einer repräsentativen Stichprobe der Grundgesamtheit stammen,
sind die von Ihnen abgeleiteten Verallgemeinerungen für die Grundgesamtheit nicht korrekt.
Im Gegensatz zu unseren vorherigen Beispielen
sollten wir Volkszählungsdaten nicht in der Inferenzanalyse verwenden.
Eine Volkszählung sammelt bereits Informationen über die gesamte Bevölkerung,
es gibt niemanden mehr, auf den man schließen könnte.
Und Daten aus der US-Volkszählung auf ein anderes Land abzuleiten, wäre keine gute Idee,
da die USA nicht unbedingt repräsentativ für ein anderes Land
sind, über das wir Wissen ableiten wollen.
Ein besseres Beispiel
für Inferenzanalysen ist stattdessen eine Studie, in der eine Untergruppe der US-Bevölkerung in Bezug auf
ihre Lebenserwartung angesichts des Ausmaßes der Luftverschmutzung, der sie ausgesetzt waren, nicht sicher war.
Diese Studie verwendet die Daten, die sie an einer Stichprobe der US-Bevölkerung gesammelt haben, um
abzuleiten, wie sich die Luftverschmutzung auf die Lebenserwartung in den gesamten USA auswirken könnte.
Das Ziel der prädiktiven Analyse besteht darin, aktuelle Daten zu verwenden, um Vorhersagen über
zukünftige Daten zu treffen.
Im Wesentlichen verwenden Sie aktuelle und historische Daten, um Muster zu finden und
die Wahrscheinlichkeit zukünftiger Ergebnisse vorherzusagen.
Wie bei der Inferenzanalyse
hängen Ihre Genauigkeit und Prognosen von der Messung der richtigen Variablen ab.
Wenn Sie nicht die richtigen Variablen messen, um ein Ergebnis vorherzusagen,
werden Ihre Vorhersagen nicht korrekt sein.
Darüber hinaus gibt es viele Möglichkeiten, Vorhersagemodelle aufzubauen, von denen einige
für bestimmte Fälle besser oder schlechter sind.
Im Allgemeinen schneiden jedoch mehr Daten und ein einfaches Modell
bei der Vorhersage zukünftiger Ergebnisse gut ab.
All dies wurde gesagt, ähnlich wie bei einer explorativen Analyse,
nur weil eine Variable, eine Variable, eine andere vorhersagen kann,
heißt das nicht, dass eine die andere verursacht.
Sie nutzen nur diese beobachtete Beziehung, um diese zweite
Variable vorherzusagen.
Ein gängiges Sprichwort besagt, dass Vorhersagen schwierig sind, insbesondere was die Zukunft betrifft.
Es gibt keine einfachen Methoden, um abzuschätzen, wie gut Sie ein Ereignis vorhersagen werden
, bis dieses Ereignis eingetreten ist. Die
Bewertung verschiedener Ansätze oder Modelle ist daher eine Herausforderung.
Wir verbringen viel Zeit damit, Dinge vorherzusagen.
Das bevorstehende Wetter.
Die Ergebnisse von Sportveranstaltungen.
Und in dem Beispiel, das wir hier untersuchen werden, sind die Wahlergebnisse.
Wir haben bereits Nate Silver von FiveThirtyEight erwähnt,
wo sie versuchen, die Ergebnisse von US-Wahlen und auch von Sportspielen vorherzusagen.
Auf der Grundlage historischer Umfragedaten und aktueller Umfragetrends erstellt FiveThirtyEight
Modelle zur Vorhersage der Ergebnisse der nächsten US-Präsidentschaftswahlen und
war dabei ziemlich genau. Die
Modelle von FiveThirtyEight sagten die Wahlen 2008 und 2012 genau voraus und galten
bei den US-Wahlen 2016 weithin als Ausreißer, da es eines der
wenigen Modelle war, das darauf hindeutete, dass Donald Trump eine Gewinnchance hatte.
Der Vorbehalt bei vielen Analysen, die wir uns bisher angesehen haben, ist, dass wir nur
Korrelationen erkennen und die Ursache der beobachteten Zusammenhänge nicht ermitteln können. Die
Kausalanalyse füllt diese Lücke.
Das Ziel der Kausalanalyse besteht darin, herauszufinden, was mit einer Variablen passiert, wenn wir eine
andere Variable manipulieren, und dabei die Ursache und Wirkung der Beziehung zu untersuchen.
Im Allgemeinen ist die Kausalanalyse
allein mit beobachteten Daten ziemlich kompliziert.
Es wird immer Fragen geben, ob diese Korrelationen Ihre
Schlussfolgerungen beeinflussen oder ob die Annahmen, die Ihrer Analyse zugrunde liegen, gültig sind.
Häufiger wird die Kausalanalyse auf die Ergebnisse randomisierter Studien angewendet, mit denen die Kausalität
identifiziert werden sollte. Die
Kausalanalyse wird oft als Goldstandard in der Datenanalyse angesehen und
findet sich häufig in wissenschaftlichen Studien, in denen Wissenschaftler versuchen,
die Ursache eines Phänomens zu identifizieren.
Oft ist es jedoch eine Herausforderung, geeignete Daten für eine Kausalanalyse zu erhalten. Bei
der Kausalanalyse ist zu beachten, dass die Daten in der Regel
aggregiert analysiert werden und beobachtete Zusammenhänge in der Regel durchschnittliche Auswirkungen sind.
Während also im Durchschnitt die Verabreichung eines
Arzneimittels an eine bestimmte Population die Symptome einer Krankheit lindern kann,
gilt dieser kausale Zusammenhang möglicherweise nicht für jede einzelne betroffene Person.
Wie bereits erwähnt, ermöglichen viele wissenschaftliche Studien eine Kausalanalyse.
Randomisierte kontrollierte Studien mit Medikamenten sind ein Paradebeispiel dafür. In
einer randomisierten Kontrollstudie wurde beispielsweise die Wirkung eines neuen
Arzneimittels bei der Behandlung von Säuglingen mit spinaler Muskelatrophie untersucht.
Vergleich einer Stichprobe von Säuglingen, die das Medikament erhielten, mit einer Stichprobe, die eine
Scheinkontrolle erhielt.
Sie messen verschiedene klinische Ergebnisse
bei Säuglingen und untersuchen, wie sich das Medikament auf die Ergebnisse auswirkt.
Mechanistische Analysen werden bei weitem nicht so häufig verwendet wie die vorherige Analyse.
Das Ziel der mechanistischen Analyse ist es, die genauen
Änderungen von Variablen zu verstehen, die zu exakten Änderungen anderer Variablen führen. Es ist
äußerst schwierig, aus diesen Analysen viele Schlüsse zu ziehen, außer in einfachen Situationen
oder in Situationen, die durch deterministische Gleichungen gut modelliert werden.
Angesichts dieser Beschreibung könnte klar sein, wie mechanistische Analysen am
häufigsten in den Physik- oder Ingenieurwissenschaften, den Biowissenschaften, angewendet werden.
Zum Beispiel sind die Datensätze viel zu laut, um mechanistische Analysen zu verwenden.
Wenn diese Analysen angewendet werden,
ist das einzige Rauschen in den Daten oft ein Messfehler, der berücksichtigt werden kann.
Beispiele für mechanistische Analysen finden Sie im Allgemeinen in
materialwissenschaftlichen Experimenten.
Hier haben wir eine Studie über Biokomposite, bei der im Wesentlichen biologisch abbaubare Kunststoffe hergestellt werden, in der
untersucht wurde, wie sich die Partikelgröße der Biokohlenstoffe, die Art der funktionellen Polymere und die
Konzentration auf die mechanischen Eigenschaften des resultierenden Kunststoffs auswirken.
Sie sind in der Lage, mechanistische Analysen durchzuführen, indem sie ein sorgfältiges Gleichgewicht zwischen kontrollierenden
und manipulierenden Variablen mit sehr genauen Messungen sowohl dieser Variablen als auch
des gewünschten Ergebnisses durchführen.
In dieser Lektion haben wir die verschiedenen Arten der Datenanalyse und ihre Ziele behandelt.
Und habe mir jeweils ein paar Beispiele angesehen, um zu zeigen
, wozu jede Analyse in der Lage ist und was noch wichtiger ist, was nicht.
Experimenteller Entwurf
Nachdem wir uns nun mit den verschiedenen Arten von datenwissenschaftlichen Fragen befasst haben,
werden wir einige Zeit damit verbringen, uns mit experimentellen Designkonzepten zu befassen.
Als Datenwissenschaftler
sind Sie ein Wissenschaftler als solcher.
Wir müssen in der Lage sein,
geeignete Experimente zu entwerfen, um Ihre datenwissenschaftlichen Fragen bestmöglich zu beantworten.
Experimentelles Design ist Organisieren und Experimentieren.
Damit Sie die richtigen Daten haben und genug davon, um
Ihre datenwissenschaftliche Frage klar und effektiv zu beantworten.
Dieser Prozess beinhaltet die klare Formulierung
Ihrer Fragen vor jeder Datenerfassung,
die Entwicklung der bestmöglichen Konfiguration zur Erfassung der Daten zur Beantwortung Ihrer Frage, die
Identifizierung von Problemen oder Luftquellen in Ihrem Design
und erst dann die Erfassung der entsprechenden Daten.
Wenn
Sie mit einer Analyse beginnen, müssen Sie im Voraus planen, was
Sie tun und wie Sie die Daten analysieren werden.
Wenn Sie die falsche Analyse durchführen,
können Sie zu falschen Schlüssen kommen.
Wir haben im
Laufe der Jahre viele Beispiele für genau dieses Szenario in der wissenschaftlichen Gemeinschaft gesehen.
Es gibt eine ganze Website,
Retraction Watch, die sich der Identifizierung von Arbeiten widmet, die
aufgrund schlechter wissenschaftlicher Praktiken zurückgezogen oder aus der Literatur entfernt wurden,
und manchmal sind diese schlechten Praktiken das Ergebnis einer schlechten Versuchsplanung und Analyse.
Gelegentlich können diese falschen Schlussfolgerungen
weitreichende Auswirkungen haben, insbesondere im Bereich der menschlichen Gesundheit.
Hier haben wir zum Beispiel einen Artikel, in dem
versucht wurde, die Auswirkungen des Genoms einer Person auf
ihre Reaktion auf verschiedene Chemotherapien vorherzusagen, um herauszufinden
, welcher Patient welche Medikamente zur besten Behandlung seines Krebses erhält.
Wie Sie sehen können, wurde dieser Artikel
über vier Jahre nach seiner ursprünglichen Veröffentlichung zurückgezogen.
In dieser Zeit
wurden diese Daten, von denen sich später herausstellte, dass sie zahlreiche Probleme bei der Einrichtung und Reinigung aufwiesen,
in fast 450 anderen Veröffentlichungen zitiert, die
diese fehlerhaften Ergebnisse möglicherweise zur Unterstützung ihrer eigenen Forschungspläne verwendet haben.
Darüber hinaus wurden diese falsch analysierten Daten in
klinischen Studien verwendet, um Behandlungspläne für Krebspatienten festzulegen.
Wenn so viel auf dem Spiel steht,
ist experimentelles Design von größter Bedeutung.
Dem experimentellen Design sind viele Konzepte und Begriffe inhärent.
Lassen Sie uns jetzt einige davon durchgehen. Die
unabhängige Variable AKA-Faktor
ist die Variable, die der Experimentator manipuliert.
Es hängt nicht von anderen gemessenen Variablen ab, die
oft auf der X-Achse angezeigt werden.
Abhängige Variablen sind Variablen, von denen erwartet wird, dass
sie sich aufgrund von Änderungen der unabhängigen Variablen ändern, die
häufig auf der Y-Achse angezeigt werden.
Das ändert also den Effekt in x,
der Effekt der unabhängigen Variablen ändert sich in y.
Wenn Sie also ein Experiment entwerfen,
müssen Sie entscheiden, welche Variablen Sie messen
und welche Sie manipulieren, um Änderungen und andere gemessene Variablen zu bewirken.
Darüber hinaus müssen Sie Ihre Hypothese entwickeln.
Im Wesentlichen eine fundierte Vermutung der Beziehung
zwischen Ihren Variablen und dem Ergebnis Ihres Experiments.
Lassen Sie uns jetzt ein Beispielexperiment machen,
sagen wir zum Beispiel, dass ich die Hypothese habe, dass mit
zunehmender Schuhgröße auch die Alphabetisierung zunimmt.
In diesem Fall
werde ich bei der Gestaltung meines Experiments ein Maß für die Alphabetisierung verwenden, z. B. die
fließende Lesefähigkeit als meine Variable, die von der Schuhgröße einer Person abhängt.
Um diese Frage zu beantworten,
werde ich ein Experiment entwerfen, bei dem ich
diese Schuhgröße und den Alphabetisierungsgrad von 100 Personen messe. Die
Stichprobengröße ist die Anzahl der Versuchspersonen, die Sie in Ihr Experiment aufnehmen werden.
Es gibt Möglichkeiten, eine optimale Stichprobengröße auszuwählen, die Sie in späteren Kursen behandeln werden.
Bevor ich meine Daten sammle,
muss ich jedoch abwägen, ob es Probleme mit
diesem Experiment gibt, die zu einem falschen Ergebnis führen könnten.
In diesem Fall könnte mein Experiment durch einen Störfaktor fatale Fehler aufweisen.
Ein Störfaktor ist eine Fremdvariable, die die
Beziehung zwischen den abhängigen und unabhängigen Variablen beeinflussen kann.
In unserem Beispiel hängen die Auswirkungen des Alters auf Größe und Alphabetisierung vom Alter ab.
Wenn wir einen Zusammenhang zwischen Schuhgröße und Alphabetisierung sehen,
könnte der Zusammenhang tatsächlich auf das Alter zurückzuführen sein, da das Alter
unser Versuchsdesign durcheinander bringt.
Um dies zu kontrollieren, können wir sicherstellen, dass wir auch das Alter jedes Einzelnen messen. Damit
wir also die Auswirkungen des Alters auf die Alphabetisierung berücksichtigen können,
und eine andere Möglichkeit, die Auswirkungen des Alters auf die
Alphabetisierung zu kontrollieren, bestünde darin, das Alter aller Teilnehmer festzulegen.
Wenn alle, die wir studieren, im gleichen Alter sind,
haben wir die möglichen Auswirkungen des Alters auf die Alphabetisierung beseitigt.
In anderen experimentellen Entwurfsparadigmen
kann eine Kontrollgruppe angemessen sein.
Dies ist der Fall, wenn Sie eine Gruppe von Versuchspersonen haben, die nicht manipuliert werden.
Wenn Sie also die Wirkung eines Arzneimittels auf das Überleben untersuchen
würden, hätten Sie eine Gruppe, die das Medikament und die
Behandlung erhalten hat, und eine Gruppe, die das Medikament nicht kontrolliert.
Auf diese Weise können Sie die Wirkungen des Arzneimittels und der Behandlung mit der Kontrollgruppe vergleichen.
In diesen Studiendesigns
gibt es Strategien, mit denen wir störende Effekte kontrollieren können.
Erstens können wir die Probanden blind für die ihnen zugewiesene Behandlungsgruppe machen.
Manchmal, wenn ein Patient weiß, dass er zur Behandlungsgruppe gehört (z. B. wenn er
das experimentelle Medikament erhält),
kann es sein, dass er sich nicht durch das Medikament
selbst besser fühlt, sondern weil er weiß, dass er behandelt wird.
Dies wird als möglicher Effekt bezeichnet.
Um dem entgegenzuwirken, sind die Teilnehmer oft blind gegenüber der Behandlungsgruppe, in der sie sich befinden.
Dies wird normalerweise erreicht, indem die Kontrollgruppe und die Lock-Therapie verabreicht werden, z. B. indem
ihnen eine Zuckerpille verabreicht wird, denen gesagt wird, dass es sich um das Medikament handelt.
Auf diese Weise
sollten beide Gruppen, wenn der mögliche Effekt ein Problem bei Ihrem Experiment verursacht, ihn gleichermaßen erleben,
und diese Strategie steht im Mittelpunkt vieler dieser Studien, bei denen
mögliche Störeffekte gleichmäßig auf die verglichenen Gruppen verteilt werden.
Wenn Sie beispielsweise der Meinung sind, dass das Alter ein möglicher Störeffekt ist,
können Sie sicherstellen, dass beide Gruppen ein ähnliches Alter und eine ähnliche Altersgruppe haben, um etwaige Auswirkungen des Alters auf Ihre abhängige Variable zu mildern.
Der Effekt des Alters ist zwischen Ihren beiden Gruppen gleich.
Dieser Ausgleich der Störfaktoren wird häufig durch Randomisierung erreicht.
Im Allgemeinen wissen wir im Voraus nicht, was ein Störfaktor sein wird, um
das Risiko zu verringern, dass versehentlich eine Gruppe voreingenommen wird, um für einen Störfaktor bereichert zu werden.
Sie können jeder Ihrer Gruppen nach dem Zufallsprinzip Personen zuweisen.
Dies bedeutet, dass alle potenziellen Störvariablen
ungefähr gleichmäßig auf die einzelnen Gruppen verteilt werden sollten,
um systematische Fehler zu eliminieren/zu reduzieren.
Es gibt ein letztes Konzept des experimentellen Designs, das
wir in dieser Lektion behandeln müssen, und das ist die Replikation.
Replikation ist so ziemlich das, wonach es sich anhört,
ein Experiment mit verschiedenen Versuchspersonen zu wiederholen.
Da es sich bei einzelnen Experimenten um zufällige Ergebnisse handeln kann.
Ein Störfaktor war ungleichmäßig auf Ihre Gruppen verteilt.
Bei der Datenerhebung ist ein systematischer Fehler aufgetreten.
Es gab einige Ausreißer usw.
Wenn Sie das Experiment jedoch wiederholen und
einen ganz neuen Datensatz sammeln und trotzdem zu demselben Ergebnis kommen,
ist Ihre Studie viel aussagekräftiger.
Das Herzstück der Replikation ist auch, dass Sie damit
die Variabilität Ihrer Daten genauer messen können,
sodass Sie besser beurteilen können,
ob die Unterschiede, die Sie in Ihren Daten sehen, signifikant sind.
Sobald Sie Ihre Daten gesammelt und analysiert haben, besteht
einer der nächsten Schritte, um
ein guter Citizen Scientist zu werden, darin, Ihre Daten und Ihren Code zur Analyse weiterzugeben.
Jetzt, wo Sie ein GitHub-Konto haben und wir Ihnen gezeigt haben, wie Sie
Ihre Versionskontrolldaten und Analysen auf GitHub speichern können,
ist dies ein großartiger Ort, um Ihren Code zu teilen.
Tatsächlich
hat unsere Gruppe, die Leek Group, auf GitHub gehostet, einen Leitfaden entwickelt, der gute Ratschläge enthält, wie man Daten am besten teilt.
Eines der vielen Dinge, die in Experimenten häufig als Wert angegeben werden, der als p-Wert bezeichnet wird.
Dies ist ein Wert, der Ihnen die Wahrscheinlichkeit angibt, dass
die Ergebnisse Ihres Experiments zufällig beobachtet wurden.
Dies ist ein sehr wichtiges Konzept in der Statistik, auf das wir hier nicht näher eingehen werden.
Wenn Sie mehr wissen möchten,
schauen Sie sich das verlinkte YouTube-Video an, in dem mehr über p-Werte erklärt wird.
Worauf Sie achten müssen, wenn Sie P-Werte zu Ihrem eigenen Zweck manipulieren,
häufig wenn Ihr p-Wert unter 0,05 liegt.
Mit anderen Worten, es besteht eine Wahrscheinlichkeit von fünf Prozent
, dass die Unterschiede, die Sie gesehen haben, zufällig beobachtet wurden.
Ein Ergebnis wird als signifikant angesehen.
Wenn Sie jedoch zufällig 20 Tests durchführen,
würden Sie erwarten, dass einer der 20 Tests, also fünf Prozent, signifikant ist.
Im Zeitalter von Big Data
ist es sehr einfach, 20 Hypothesen zu testen,
und daher stammt der Begriff P-Hacking.
In diesem Fall durchsuchen Sie einen Datensatz ausgiebig nach Mustern und Korrelationen, die
aufgrund der bloßen Anzahl der von Ihnen durchgeführten Tests statistisch signifikant erscheinen.
Diese falschen Korrelationen können
als signifikant gemeldet werden. Wenn Sie genügend Tests durchführen,
können Sie einen Datensatz und eine Analyse finden, die Ihnen zeigen, was Sie sehen wollten.
Schauen Sie sich diese 538-Aktivität
an, bei der Sie ungefilterte Daten manipulieren und eine Reihe von
Tests durchführen können, damit Sie die Daten abrufen können, um die gewünschte Beziehung zu finden.
XKCD verspottet dieses Konzept in einem Comic, der den Zusammenhang zwischen Gummibärchen und Akne testet.
Offensichtlich gibt es dort keinen Link.
Wenn Sie jedoch irgendwann genügend Gummibärchen testen,
korreliert eine davon mit Akne bei einem p-Wert von weniger als 0,05.
In dieser Lektion haben wir behandelt, was
experimentelles Design ist und warum gutes experimentelles Design wichtig ist.
Anschließend haben wir uns eingehend mit den Prinzipien des Versuchsdesigns befasst und
einige der gebräuchlichen Begriffe definiert, die Sie bei der Planung eines Experiments berücksichtigen müssen.
Als Nächstes haben wir uns ein bisschen überlegt, wie Sie Ihre Daten und Ihren Code für Analysezwecke weitergeben sollten,
und schließlich haben wir uns die Gefahren angesehen, die mit
P-Hacking und der Manipulation von Daten verbunden sind, um Signifikanz zu erlangen.
Experimenteller Entwurf
Nachdem wir uns nun mit den verschiedenen Arten von datenwissenschaftlichen Fragen befasst haben,
werden wir einige Zeit damit verbringen, uns mit experimentellen Designkonzepten zu befassen.
Als Datenwissenschaftler
sind Sie ein Wissenschaftler als solcher.
Wir müssen in der Lage sein,
geeignete Experimente zu entwerfen, um Ihre datenwissenschaftlichen Fragen bestmöglich zu beantworten.
Experimentelles Design ist Organisieren und Experimentieren.
Damit Sie die richtigen Daten haben und genug davon, um
Ihre datenwissenschaftliche Frage klar und effektiv zu beantworten.
Dieser Prozess beinhaltet die klare Formulierung
Ihrer Fragen vor jeder Datenerfassung,
die Entwicklung der bestmöglichen Konfiguration zur Erfassung der Daten zur Beantwortung Ihrer Frage, die
Identifizierung von Problemen oder Luftquellen in Ihrem Design
und erst dann die Erfassung der entsprechenden Daten.
Wenn
Sie mit einer Analyse beginnen, müssen Sie im Voraus planen, was
Sie tun und wie Sie die Daten analysieren werden.
Wenn Sie die falsche Analyse durchführen,
können Sie zu falschen Schlüssen kommen.
Wir haben im
Laufe der Jahre viele Beispiele für genau dieses Szenario in der wissenschaftlichen Gemeinschaft gesehen.
Es gibt eine ganze Website,
Retraction Watch, die sich der Identifizierung von Arbeiten widmet, die
aufgrund schlechter wissenschaftlicher Praktiken zurückgezogen oder aus der Literatur entfernt wurden,
und manchmal sind diese schlechten Praktiken das Ergebnis einer schlechten Versuchsplanung und Analyse.
Gelegentlich können diese falschen Schlussfolgerungen
weitreichende Auswirkungen haben, insbesondere im Bereich der menschlichen Gesundheit.
Hier haben wir zum Beispiel einen Artikel, in dem
versucht wurde, die Auswirkungen des Genoms einer Person auf
ihre Reaktion auf verschiedene Chemotherapien vorherzusagen, um herauszufinden
, welcher Patient welche Medikamente zur besten Behandlung seines Krebses erhält.
Wie Sie sehen können, wurde dieser Artikel
über vier Jahre nach seiner ursprünglichen Veröffentlichung zurückgezogen.
In dieser Zeit
wurden diese Daten, von denen sich später herausstellte, dass sie zahlreiche Probleme bei der Einrichtung und Reinigung aufwiesen,
in fast 450 anderen Veröffentlichungen zitiert, die
diese fehlerhaften Ergebnisse möglicherweise zur Unterstützung ihrer eigenen Forschungspläne verwendet haben.
Darüber hinaus wurden diese falsch analysierten Daten in
klinischen Studien verwendet, um Behandlungspläne für Krebspatienten festzulegen.
Wenn so viel auf dem Spiel steht,
ist experimentelles Design von größter Bedeutung.
Dem experimentellen Design sind viele Konzepte und Begriffe inhärent.
Lassen Sie uns jetzt einige davon durchgehen. Die
unabhängige Variable AKA-Faktor
ist die Variable, die der Experimentator manipuliert.
Es hängt nicht von anderen gemessenen Variablen ab, die
oft auf der X-Achse angezeigt werden.
Abhängige Variablen sind Variablen, von denen erwartet wird, dass
sie sich aufgrund von Änderungen der unabhängigen Variablen ändern, die
häufig auf der Y-Achse angezeigt werden.
Das ändert also den Effekt in x,
der Effekt der unabhängigen Variablen ändert sich in y.
Wenn Sie also ein Experiment entwerfen,
müssen Sie entscheiden, welche Variablen Sie messen
und welche Sie manipulieren, um Änderungen und andere gemessene Variablen zu bewirken.
Darüber hinaus müssen Sie Ihre Hypothese entwickeln.
Im Wesentlichen eine fundierte Vermutung der Beziehung
zwischen Ihren Variablen und dem Ergebnis Ihres Experiments.
Lassen Sie uns jetzt ein Beispielexperiment machen,
sagen wir zum Beispiel, dass ich die Hypothese habe, dass mit
zunehmender Schuhgröße auch die Alphabetisierung zunimmt.
In diesem Fall
werde ich bei der Gestaltung meines Experiments ein Maß für die Alphabetisierung verwenden, z. B. die
fließende Lesefähigkeit als meine Variable, die von der Schuhgröße einer Person abhängt.
Um diese Frage zu beantworten,
werde ich ein Experiment entwerfen, bei dem ich
diese Schuhgröße und den Alphabetisierungsgrad von 100 Personen messe. Die
Stichprobengröße ist die Anzahl der Versuchspersonen, die Sie in Ihr Experiment aufnehmen werden.
Es gibt Möglichkeiten, eine optimale Stichprobengröße auszuwählen, die Sie in späteren Kursen behandeln werden.
Bevor ich meine Daten sammle,
muss ich jedoch abwägen, ob es Probleme mit
diesem Experiment gibt, die zu einem falschen Ergebnis führen könnten.
In diesem Fall könnte mein Experiment durch einen Störfaktor fatale Fehler aufweisen.
Ein Störfaktor ist eine Fremdvariable, die die
Beziehung zwischen den abhängigen und unabhängigen Variablen beeinflussen kann.
In unserem Beispiel hängen die Auswirkungen des Alters auf Größe und Alphabetisierung vom Alter ab.
Wenn wir einen Zusammenhang zwischen Schuhgröße und Alphabetisierung sehen,
könnte der Zusammenhang tatsächlich auf das Alter zurückzuführen sein, da das Alter
unser Versuchsdesign durcheinander bringt.
Um dies zu kontrollieren, können wir sicherstellen, dass wir auch das Alter jedes Einzelnen messen. Damit
wir also die Auswirkungen des Alters auf die Alphabetisierung berücksichtigen können,
und eine andere Möglichkeit, die Auswirkungen des Alters auf die
Alphabetisierung zu kontrollieren, bestünde darin, das Alter aller Teilnehmer festzulegen.
Wenn alle, die wir studieren, im gleichen Alter sind,
haben wir die möglichen Auswirkungen des Alters auf die Alphabetisierung beseitigt.
In anderen experimentellen Entwurfsparadigmen
kann eine Kontrollgruppe angemessen sein.
Dies ist der Fall, wenn Sie eine Gruppe von Versuchspersonen haben, die nicht manipuliert werden.
Wenn Sie also die Wirkung eines Arzneimittels auf das Überleben untersuchen
würden, hätten Sie eine Gruppe, die das Medikament und die
Behandlung erhalten hat, und eine Gruppe, die das Medikament nicht kontrolliert.
Auf diese Weise können Sie die Wirkungen des Arzneimittels und der Behandlung mit der Kontrollgruppe vergleichen.
In diesen Studiendesigns
gibt es Strategien, mit denen wir störende Effekte kontrollieren können.
Erstens können wir die Probanden blind für die ihnen zugewiesene Behandlungsgruppe machen.
Manchmal, wenn ein Patient weiß, dass er zur Behandlungsgruppe gehört (z. B. wenn er
das experimentelle Medikament erhält),
kann es sein, dass er sich nicht durch das Medikament
selbst besser fühlt, sondern weil er weiß, dass er behandelt wird.
Dies wird als möglicher Effekt bezeichnet.
Um dem entgegenzuwirken, sind die Teilnehmer oft blind gegenüber der Behandlungsgruppe, in der sie sich befinden.
Dies wird normalerweise erreicht, indem die Kontrollgruppe und die Lock-Therapie verabreicht werden, z. B. indem
ihnen eine Zuckerpille verabreicht wird, denen gesagt wird, dass es sich um das Medikament handelt.
Auf diese Weise
sollten beide Gruppen, wenn der mögliche Effekt ein Problem bei Ihrem Experiment verursacht, ihn gleichermaßen erleben,
und diese Strategie steht im Mittelpunkt vieler dieser Studien, bei denen
mögliche Störeffekte gleichmäßig auf die verglichenen Gruppen verteilt werden.
Wenn Sie beispielsweise der Meinung sind, dass das Alter ein möglicher Störeffekt ist,
können Sie sicherstellen, dass beide Gruppen ein ähnliches Alter und eine ähnliche Altersgruppe haben, um etwaige Auswirkungen des Alters auf Ihre abhängige Variable zu mildern.
Der Effekt des Alters ist zwischen Ihren beiden Gruppen gleich.
Dieser Ausgleich der Störfaktoren wird häufig durch Randomisierung erreicht.
Im Allgemeinen wissen wir im Voraus nicht, was ein Störfaktor sein wird, um
das Risiko zu verringern, dass versehentlich eine Gruppe voreingenommen wird, um für einen Störfaktor bereichert zu werden.
Sie können jeder Ihrer Gruppen nach dem Zufallsprinzip Personen zuweisen.
Dies bedeutet, dass alle potenziellen Störvariablen
ungefähr gleichmäßig auf die einzelnen Gruppen verteilt werden sollten,
um systematische Fehler zu eliminieren/zu reduzieren.
Es gibt ein letztes Konzept des experimentellen Designs, das
wir in dieser Lektion behandeln müssen, und das ist die Replikation.
Replikation ist so ziemlich das, wonach es sich anhört,
ein Experiment mit verschiedenen Versuchspersonen zu wiederholen.
Da es sich bei einzelnen Experimenten um zufällige Ergebnisse handeln kann.
Ein Störfaktor war ungleichmäßig auf Ihre Gruppen verteilt.
Bei der Datenerhebung ist ein systematischer Fehler aufgetreten.
Es gab einige Ausreißer usw.
Wenn Sie das Experiment jedoch wiederholen und
einen ganz neuen Datensatz sammeln und trotzdem zu demselben Ergebnis kommen,
ist Ihre Studie viel aussagekräftiger.
Das Herzstück der Replikation ist auch, dass Sie damit
die Variabilität Ihrer Daten genauer messen können,
sodass Sie besser beurteilen können,
ob die Unterschiede, die Sie in Ihren Daten sehen, signifikant sind.
Sobald Sie Ihre Daten gesammelt und analysiert haben, besteht
einer der nächsten Schritte, um
ein guter Citizen Scientist zu werden, darin, Ihre Daten und Ihren Code zur Analyse weiterzugeben.
Jetzt, wo Sie ein GitHub-Konto haben und wir Ihnen gezeigt haben, wie Sie
Ihre Versionskontrolldaten und Analysen auf GitHub speichern können,
ist dies ein großartiger Ort, um Ihren Code zu teilen.
Tatsächlich
hat unsere Gruppe, die Leek Group, auf GitHub gehostet, einen Leitfaden entwickelt, der gute Ratschläge enthält, wie man Daten am besten teilt.
Eines der vielen Dinge, die in Experimenten häufig als Wert angegeben werden, der als p-Wert bezeichnet wird.
Dies ist ein Wert, der Ihnen die Wahrscheinlichkeit angibt, dass
die Ergebnisse Ihres Experiments zufällig beobachtet wurden.
Dies ist ein sehr wichtiges Konzept in der Statistik, auf das wir hier nicht näher eingehen werden.
Wenn Sie mehr wissen möchten,
schauen Sie sich das verlinkte YouTube-Video an, in dem mehr über p-Werte erklärt wird.
Worauf Sie achten müssen, wenn Sie P-Werte zu Ihrem eigenen Zweck manipulieren,
häufig wenn Ihr p-Wert unter 0,05 liegt.
Mit anderen Worten, es besteht eine Wahrscheinlichkeit von fünf Prozent
, dass die Unterschiede, die Sie gesehen haben, zufällig beobachtet wurden.
Ein Ergebnis wird als signifikant angesehen.
Wenn Sie jedoch zufällig 20 Tests durchführen,
würden Sie erwarten, dass einer der 20 Tests, also fünf Prozent, signifikant ist.
Im Zeitalter von Big Data
ist es sehr einfach, 20 Hypothesen zu testen,
und daher stammt der Begriff P-Hacking.
In diesem Fall durchsuchen Sie einen Datensatz ausgiebig nach Mustern und Korrelationen, die
aufgrund der bloßen Anzahl der von Ihnen durchgeführten Tests statistisch signifikant erscheinen.
Diese falschen Korrelationen können
als signifikant gemeldet werden. Wenn Sie genügend Tests durchführen,
können Sie einen Datensatz und eine Analyse finden, die Ihnen zeigen, was Sie sehen wollten.
Schauen Sie sich diese 538-Aktivität
an, bei der Sie ungefilterte Daten manipulieren und eine Reihe von
Tests durchführen können, damit Sie die Daten abrufen können, um die gewünschte Beziehung zu finden.
XKCD verspottet dieses Konzept in einem Comic, der den Zusammenhang zwischen Gummibärchen und Akne testet.
Offensichtlich gibt es dort keinen Link.
Wenn Sie jedoch irgendwann genügend Gummibärchen testen,
korreliert eine davon mit Akne bei einem p-Wert von weniger als 0,05.
In dieser Lektion haben wir behandelt, was
experimentelles Design ist und warum gutes experimentelles Design wichtig ist.
Anschließend haben wir uns eingehend mit den Prinzipien des Versuchsdesigns befasst und
einige der gebräuchlichen Begriffe definiert, die Sie bei der Planung eines Experiments berücksichtigen müssen.
Als Nächstes haben wir uns ein bisschen überlegt, wie Sie Ihre Daten und Ihren Code für Analysezwecke weitergeben sollten,
und schließlich haben wir uns die Gefahren angesehen, die mit
P-Hacking und der Manipulation von Daten verbunden sind, um Signifikanz zu erlangen.
Big Data
Ein Begriff, von dem Sie vielleicht vor diesem Kurs gehört haben, ist Big Data.
Es gab schon immer große Datensätze,
aber es scheint, als ob
dies in letzter Zeit zu einem Passwort in der Datenwissenschaft geworden ist.
Was bedeutet das?
In der allerersten Vorlesung dieses Kurses haben wir ein wenig über Big Data gesprochen.
Wie der Name schon sagt,
handelt es sich bei Big Data um sehr große Datensätze.
Wir haben zuvor drei Eigenschaften erörtert, die
großen Datensätzen häufig zugeschrieben werden: Volumen, Geschwindigkeit, Vielfalt.
Aus diesen drei Adjektiven
können wir erkennen, dass Big Data große Datensätze mit
unterschiedlichen Datentypen beinhaltet, die sehr schnell generiert werden.
Aber keine dieser Eigenschaften scheint besonders neu zu sein.
Warum wurde das Konzept von Big Data in letzter Zeit populär gemacht?
Teilweise hat
sich die Technologie im Bereich der Datenspeicherung weiterentwickelt, um immer größere Datensätze speichern zu können.
Die Definition von „groß“ hat sich ebenfalls weiterentwickelt.
Außerdem hat sich unsere Fähigkeit, Daten zu sammeln und aufzuzeichnen, mit der
Zeit verbessert, sodass die Geschwindigkeit, mit der Daten gesammelt werden, beispiellos ist.
Schließlich hat sich das, was als Daten betrachtet wird, weiterentwickelt,
sodass es heute mehr denn je gibt.
Unternehmen haben die Vorteile erkannt, die das Sammeln verschiedener Informationen mit sich bringt,
und der Aufstieg des Internets und der Technologie hat es ermöglicht,
verschiedene und vielfältige Datensätze einfacher zu sammeln und für Analysen verfügbar zu machen.
Eine der wichtigsten Veränderungen in der Datenwissenschaft war die Umstellung von
strukturierten Datensätzen auf die Bearbeitung unstrukturierter Daten.
Strukturierte Daten sind das, was Sie traditionell von Daten, langen Tabellen, Tabellen
oder Datenbanken halten, mit Spalten und Zeilen mit
Informationen, die Sie
innerhalb dieser Grenzen summieren, berechnen oder analysieren können, wie Sie möchten.
Leider werden Ihnen Daten heutzutage selten auf diese Weise präsentiert.
Die Datensätze, denen wir häufig begegnen, sind viel chaotischer und es ist unsere Aufgabe,
die Informationen, die wir benötigen, zu extrahieren und zu etwas Ordentlichem und Strukturiertem zusammenzufassen.
Mit dem digitalen Zeitalter und dem Fortschritt des Internets
konnten viele Informationen, die wir traditionell gesammelt haben, plötzlich in ein Format übersetzt werden, das ein Computer aufzeichnen,
speichern, durchsuchen und analysieren konnte.
Sobald dies erkannt wurde,
gab es eine Zunahme dieser unstrukturierten Daten, die
aus all unseren digitalen Interaktionen, E-Mails,
Facebook- und anderen Interaktionen in sozialen Medien, Textnachrichten,
Einkaufsgewohnheiten, Smartphones und deren GPS-Tracking-Websites, die Sie besuchen, gesammelt wurden.
Wie lange Sie auf dieser Website sind und was Sie sich ansehen,
CCTV-Kameras und andere Videoquellen usw.
Die Datenmenge und die verschiedenen Quellen, die
Daten aufzeichnen und übertragen können, sind explosionsartig angestiegen.
Aufgrund dieser explosionsartigen Zunahme von
Datenvolumen, Geschwindigkeit und Vielfalt ist Big Data zu einem so wichtigen Begriff geworden.
Diese Datensätze sind jetzt so umfangreich und komplex, dass wir
neue Tools und Ansätze benötigen, um das Beste aus ihnen herauszuholen.
Wie Sie sich vorstellen können, werden die Daten angesichts der Vielzahl von Datentypen und Quellen
nur sehr selten in einer übersichtlichen,
geordneten Tabelle gespeichert, auf die herkömmliche
Bereinigungs- und Analysemethoden angewendet werden können.
Angesichts einiger der oben genannten Eigenschaften von Big Data
können Sie bereits einige der Herausforderungen erkennen
, die mit der Arbeit mit Big Data verbunden sein können.
Zum einen ist es groß.
Es gab eine Menge Rohdaten, die Sie speichern und analysieren müssen.
Zweitens ändert und aktualisiert es sich ständig.
Wenn Sie Ihre Analyse abgeschlossen haben,
gibt es noch mehr neue Daten, die Sie in Ihre Analyse einbeziehen könnten.
Jede Sekunde, die Sie analysieren,
ist eine weitere Sekunde an Daten, die Sie nicht verwendet haben.
Drittens kann die Vielfalt überwältigend sein.
Es gibt so viele Informationsquellen, dass es manchmal schwierig sein kann,
festzustellen, welche Datenquelle für die Beantwortung Ihrer datenwissenschaftlichen Frage am besten geeignet ist.
Endlich ist es chaotisch.
Sie haben keine übersichtlichen Datentabellen, um sie schnell zu analysieren. Sie haben unübersichtliche Daten.
Bevor Sie nach Antworten suchen können,
müssen Sie Ihre unstrukturierten Daten in ein Format umwandeln, das Sie analysieren können.
Warum also bleiben wir bei all diesen Herausforderungen nicht einfach bei der Analyse kleinerer,
besser verwaltbarer, kuratierter Datensätze und kommen auf diese Weise zu unseren Antworten?
Manchmal lassen sich Fragen am besten mit diesen kleineren Datensätzen beantworten,
aber viele Fragen profitieren davon, viele, viele
Daten zu haben und wenn diese Daten unübersichtlich oder ungenau sind.
Das schiere Volumen macht die Auswirkungen dieser kleinen Fehler zunichte.
So können wir der Wahrheit auch mit diesen chaotischeren Datensätzen näher kommen.
Wenn Sie über Daten verfügen, die ständig aktualisiert werden,
kann die Analyse zwar schwierig sein, aber
die Fähigkeit,
über aktuelle Informationen in Echtzeit zu verfügen, ermöglicht es Ihnen, Analysen durchzuführen
, die dem aktuellen Stand entsprechen, und vor Ort
schnelle, fundierte Vorhersagen und Entscheidungen zu treffen.
Einer der Vorteile all dieser neuen Informationsquellen besteht darin,
dass Fragen gestellt werden, die aufgrund fehlender Informationen bisher nicht beantwortet werden konnten.
Plötzlich stehen viel mehr Informationsquellen zur Verfügung,
und es können jetzt neue Verbindungen und Entdeckungen gemacht werden.
Fragen, auf die zuvor nicht zugegriffen werden konnte, verfügen jetzt über neuere,
unkonventionelle Datenquellen, mit denen Sie
diese früher undurchführbaren Fragen möglicherweise beantworten können.
Ein weiterer Vorteil der Verwendung von Big Data besteht
darin, dass versteckte Zusammenhänge identifiziert werden können.
Da wir Daten zu einer Vielzahl von Eigenschaften zu einem Thema sammeln können,
können wir nach Eigenschaften suchen, die möglicherweise nicht offensichtlich mit unserer Ergebnisvariablen zusammenhängen,
aber die großen Daten können dort eine Korrelation erkennen.
Anstatt zu versuchen, genau zu verstehen, warum
ein Motor ausfällt oder warum eine Arzneimittelnebenwirkung verschwindet,
können Forscher stattdessen riesige Mengen an
Informationen über solche Ereignisse und alles, was damit zusammenhängt, sammeln und nach
Mustern suchen, die helfen könnten, zukünftige Ereignisse vorherzusagen.
Big Data hilft bei der Beantwortung welcher Fragen?
Nicht warum? Oft ist das gut genug.
Big Data hat es nun ermöglicht, riesige Datenmengen
sehr schnell aus einer Vielzahl von Quellen zu sammeln, und dank
technologischer Verbesserungen ist das Sammeln, Speichern und Analysieren günstiger geworden.
Es bleibt jedoch die Frage,
wie viel von dieser Datenexplosion nützlich ist, um Fragen zu beantworten, die Ihnen wichtig sind?
Unabhängig von der Größe der Daten
benötigen Sie die richtigen Daten, um eine Frage zu beantworten.
Ein berühmter Statistiker, John Tukey, sagte 1986:
„Die Kombination einiger Daten und der sehnliche Wunsch nach einer Antwort
gewährleistet nicht, dass aus einem bestimmten Datenbestand eine vernünftige Antwort extrahiert werden kann.“
Im Wesentlichen ist ein bestimmter Datensatz möglicherweise nicht für Ihre Frage geeignet,
auch wenn Sie es wirklich wollten, und Big Data behebt dies nicht.
Selbst die größten Datensätze, die es gibt, sind möglicherweise nicht groß genug, um
Ihre Frage beantworten zu können, wenn es sich nicht um die richtigen Daten handelt.
In dieser Lektion haben wir uns mit einigen Eigenschaften befasst, die Big Data,
Volumen, Geschwindigkeit und Vielfalt charakterisieren.
Wir haben strukturierte und unstrukturierte Daten verglichen
und einige der neuen Quellen unstrukturierter Daten untersucht.
Dann schauen wir uns die Herausforderungen und
Vorteile der Arbeit mit diesen großen Datensätzen an.
Schließlich kamen wir auf die Idee zurück, dass Datenwissenschaft
fragenorientierte Wissenschaft ist und selbst die größten
Datensätze möglicherweise nicht für Ihren Fall geeignet sind.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.