Übersicht über das Google Business Intelligence-Zertifikat
Hallo und willkommen beim Google Business Intelligence-Zertifikat ! In diesem Programm erkunden Sie das wachsende Feld der Business Intelligence (BI), erfahren, wie wichtig BI für Unternehmen und die Menschen, denen sie dienen, wichtig ist, und entwickeln die relevanten Fähigkeiten für eine zukünftige Karriere in diesem Bereich. Durch den Abschluss der drei Kurse in diesem Zertifikatsprogramm bereiten Sie sich auf Einstiegspositionen im BI vor. Für den Abschluss des Programms sind keine BI-Vorkenntnisse erforderlich, grundlegende Kenntnisse in der Datenanalyse werden jedoch dringend empfohlen.
Betreten Sie ein wachsendes Feld
Unternehmen berichten darüberGrößte Qualifikationslückein der Datenanalyse, und die Nachfrage nach Datenanalysefähigkeiten wächst15-mal schnellerals die Nachfrage nach durchschnittlichen Qualifikationen in den USA. Jeder Geschäftsprozess in Organisationen aller Art und Größe erzeugt riesige Datenmengen. Diese Daten können an verschiedenen Orten und in unterschiedlichen Formaten gespeichert werden, die schwer zugänglich sind und keine nützlichen Erkenntnisse liefern. Um diese Daten effektiv für Geschäftsentscheidungen nutzen zu können, müssen sie abgerufen, strukturiert, interpretiert und in verwendbaren Formaten berichtet werden, die es den Beteiligten ermöglichen, sie zu verstehen und zu handeln. BI-Experten spielen in diesem Prozess eine äußerst wichtige Rolle: Sie verwalten den Datenabruf; Daten organisieren; Interpretieren Sie Daten auf unterschiedliche Weise, um sie an das vorliegende Problem anzupassen. und erstellen Sie Datenvisualisierungen, Dashboards und andere Tools, um Stakeholder-bereite Erkenntnisse bereitzustellen.
Während dieses Programms haben Sie mehrere Möglichkeiten, Ihre BI-Kenntnisse und -Fähigkeiten weiterzuentwickeln. Sie erkunden Konzepte und Szenarien, um zu erfahren, was ein BI-Einsteiger wissen und leisten können muss, um in diesem Bereich erfolgreich zu sein.
Kurse zum Google Business Intelligence-Zertifikat
Das Google Business Intelligence-Zertifikat besteht aus drei Kursen. Während jedes Kurses absolvieren Sie praktische Aufgaben und Projekte, die sowohl auf den täglichen Aufgaben als auch auf den praktischen Aktivitäten eines BI-Experten basieren. Sie erfahren mehr über die Rolle eines BI-Experten in einer Organisation und erfahren, wie Sie Tools und Prozesse erstellen, die den Entscheidungsprozess unterstützen. Und Sie erstellen dynamische Berichte und Dashboards, die Datentrends nahezu in Echtzeit kommunizieren. Am Ende jedes Kurses haben Sie außerdem die Möglichkeit, einen neuen Schritt in einem Portfolio-Abschlussprojekt abzuschließen, bei dem Sie Ihre neuen Fähigkeiten in die Praxis umsetzen und potenziellen Arbeitgebern demonstrieren, was Sie gelernt haben. Die Kurse des Programms sind wie folgt:
Grundlagen der Business Intelligence (aktueller Kurs)

Inhalt des Google Data Analytics-Zertifikats
Die Kurse des Google Business Intelligence-Zertifikats bauen auf vielen grundlegenden Konzepten auf, die im Google Business Intelligence-Zertifikat untersucht werdenGoogle Data Analytics-Zertifikat. Während dieses Programms werden Sie auf Links zu Inhalten des Google Data Analytics-Zertifikats stoßen. Dieses Material soll eine optionale Überprüfung bieten und als nützliche Ressource dienen.
Vorteile für Arbeitssuchende
Nach Abschluss aller drei Kurse erhalten Absolventen des Google Business Intelligence-Zertifikats Zugang zu exklusiven Ressourcen für die Jobsuche, bereitgestellt von Google. Sie haben die Möglichkeit:
Erstellen Sie Ihren Lebenslauf, nehmen Sie an Probeinterviews teil und erhalten Sie Tipps für die Jobsuche über Big Interview, eine Plattform für Berufsausbildung, die für Programmabsolventen kostenlos ist.
Verbessern Sie Ihre Interviewtechnik mit Interview Warmup, einem Tool, das von Google speziell für Absolventen von Zertifikaten entwickelt wurde. Greifen Sie auf Business-Intelligence-spezifische Übungsfragen, Transkripte Ihrer Antworten und automatische Erkenntnisse zu, die Ihnen helfen, Ihre Fähigkeiten und Ihr Selbstvertrauen zu stärken.
Greifen Sie mit Career Circle auf Tausende von Stellenausschreibungen und kostenloses Einzel-Karriere-Coaching zu. (Um beizutreten, müssen Sie berechtigt sein, in den USA zu arbeiten.)
Fordern Sie Ihr Google Business Intelligence-Zertifikatsabzeichen an und teilen Sie Ihre Erfolge auf LinkedIn, um sich bei potenziellen Arbeitgebern von anderen Kandidaten abzuheben.
Herzlichen Glückwunsch zu diesem ersten Schritt zum Aufbau Ihrer Fähigkeiten für eine Karriere im Bereich Business Intelligence. Geniesse die Reise!
Überblick über Kurs 1

Hallo und willkommen bei Foundations of Business Intelligence , dem ersten Kurs zum Google Business Intelligence-Zertifikat. Sie beginnen eine aufregende Reise!
Am Ende dieses Kurses erfahren Sie, welche Rolle Business-Intelligence-Experten (BI) in einem Unternehmen spielen, erfahren, wie Daten in Geschäftsprozessen und bei der Entscheidungsfindung verwendet werden, und untersuchen BI-Tools, die Sie bei der Arbeit verwenden können.
Kursbeschreibung
Das Google Business Intelligence-Zertifikat besteht aus drei Kursen. Der erste Kurs ist „ Grundlagen der Business Intelligence“ .

Grundlagen der Business Intelligence – ( aktueller Kurs ) Entdecken Sie die Rolle von BI-Experten innerhalb einer Organisation und die Karrierewege, die sie normalerweise einschlagen. Entdecken Sie anschließend die wichtigsten BI-Praktiken und -Tools und erfahren Sie, wie BI-Experten sie nutzen, um einen positiven Einfluss auf Unternehmen zu erzielen.
Der Weg zu Erkenntnissen: Datenmodelle und Pipelines— Entdecken Sie Datenmodellierungs- und ETL-Prozesse zum Extrahieren von Daten aus Quellsystemen, zum Umwandeln in Formate, die eine bessere Analyse ermöglichen und Geschäftsprozesse und -ziele vorantreiben.
Entscheidungen, Entscheidungen: Dashboards und Berichte— Wenden Sie Ihr Wissen über BI und Datenmodellierung an, um dynamische Dashboards zu erstellen, die wichtige Leistungsindikatoren verfolgen, um den Anforderungen der Stakeholder gerecht zu werden.
Inhalt von Kurs 1
Jeder Kurs dieses Zertifikatsprogramms ist in Module unterteilt. Sie können Kurse in Ihrem eigenen Tempo absolvieren, die Modulaufschlüsselung soll Ihnen jedoch dabei helfen, das gesamte Google Business Intelligence-Zertifikat in zwei bis vier Monaten abzuschließen.
Was kommt? Hier finden Sie einen kurzen Überblick über die Fähigkeiten, die Sie in den einzelnen Modulen dieses Kurses erlernen.

Modul 1: Datengesteuerte Ergebnisse durch Business Intelligence
Beginnen Sie Ihre Reise in die Business Intelligence! Finden Sie heraus, was Sie für Kurs 1 und das gesamte Zertifikatsprogramm erwartet. Sie lernen die Coursera-Plattform, die Verfahren und Inhaltstypen kennen und treffen andere Lernende im Programm. Anschließend lernen Sie die BI-Branche und die Rollen von BI-Analysten und -Ingenieuren kennen. Sie werden in BI-Tools und -Techniken eingeführt, um Geschäftsentscheidungen zu treffen und Prozesse zu verbessern. Abschließend lernen Sie die Gemeinsamkeiten und Unterschiede zwischen den beiden Bereichen BI und Datenanalyse kennen.
Modul 2: Business-Intelligence-Tools und -Techniken
Nachdem Sie eine solide Grundlage in den Grundlagen von BI geschaffen haben, konzentrieren Sie sich auf den eigentlichen BI-Prozess. Dabei geht es darum, zu lernen, wie man effektiv mit Stakeholdern interagiert, BI-Tools nutzt, um die verfügbaren Daten optimal zu nutzen, und die Möglichkeiten der schnellen Überwachung zu nutzen, um intelligente Geschäftsentscheidungen zu treffen. Darüber hinaus beginnen Sie mit dem Aufbau einiger Karriereressourcen, indem Sie Ihre Online-Präsenz verbessern, Strategien für Networking und Mentoring entwickeln und ein Portfolio erstellen, das zukünftige Personalmanager beeindrucken wird.
Modul 3: Der Kontext ist entscheidend für zielgerichtete Erkenntnisse
In diesem Teil des Kurses werden Sie die Datenbeschränkung des Kontexts aus BI-Perspektive erneut untersuchen. Anschließend erfahren Sie mehr über einige andere Datenbeschränkungen, einschließlich der Frage, wie Sie auf ständige Veränderungen reagieren und zeitnah auf Erkenntnisse zugreifen können. Sie erfahren außerdem Strategien, mit denen BI-Experten diese Einschränkungen vorhersehen und überwinden können. Abschließend erfahren Sie mehr über Metriken und deren Zusammenhang mit dem Kontext.
Modul 4: Abschlussprojekt von Kurs 1
In diesem Teil des Kurses schließen Sie ein BI-Portfolioprojekt auf der Grundlage einer BI-Fallstudie ab. Bei dieser erfahrungsorientierten Lernmöglichkeit können Sie entdecken, wie Unternehmen BI jeden Tag nutzen, und alles, was Sie über BI gelernt haben, auf überzeugende und lehrreiche Weise zusammenführen. Sie erfahren, wie Sie die spezifischen Arten von Branchen und Projekten identifizieren, die für Sie am interessantesten sind. Und Sie erhalten Strategien, um diese Geschäftsarten und BI-Aufgaben effektiv mit potenziellen Arbeitgebern zu besprechen.
Was zu erwarten ist
Jeder Kurs bietet viele Arten von Lernmöglichkeiten:
Von Google-Lehrern geleitete Videos vermitteln neue Konzepte, führen in die Verwendung relevanter Tools ein, bieten Karriereunterstützung und liefern inspirierende persönliche Geschichten.
Die Lesungen bauen auf den in den Videos behandelten Themen auf, stellen verwandte Konzepte vor, teilen nützliche Ressourcen und beschreiben Fallstudien.
Diskussionsaufforderungen erläutern Kursthemen zum besseren Verständnis und ermöglichen es Ihnen, mit anderen Lernenden im zu chatten und Ideen auszutauschenDiskussionsforen.
Durch Selbstüberprüfungsaktivitäten und Labore können Sie die Anwendung der erlernten Fertigkeiten praktisch üben und Ihre eigene Arbeit durch den Vergleich mit einem abgeschlossenen Beispiel bewerten.
Interaktive Plug-ins regen zum Üben konkreter Aufgaben an und unterstützen Sie bei der Integration des im Kurs erworbenen Wissens.
In-Video-Tests helfen Ihnen, Ihr Verständnis zu überprüfen, während Sie jedes Video durchgehen.
Mit Übungsquiz können Sie Ihr Verständnis wichtiger Konzepte überprüfen und wertvolles Feedback geben.
Benotete Tests zeigen Ihr Verständnis der Hauptkonzepte eines Kurses. Um ein Zertifikat zu erhalten, müssen Sie in jedem benoteten Quiz mindestens 80 % erreichen. Sie können ein benotetes Quiz auch mehrmals absolvieren, um eine bestandene Punktzahl zu erreichen.
Tipps für den Erfolg
Es wird dringend empfohlen, die Elemente in jeder Lektion in der Reihenfolge durchzugehen, in der sie erscheinen, da neue Informationen und Konzepte auf Vorkenntnissen aufbauen.
Nehmen Sie an allen Lernmöglichkeiten teil, um so viel Wissen und Erfahrung wie möglich zu sammeln.
Wenn etwas verwirrend ist, zögern Sie nicht, ein Video noch einmal abzuspielen, eine Lektüre zu wiederholen oder eine Selbstüberprüfungsaktivität zu wiederholen.
Nutzen Sie die zusätzlichen Ressourcen, auf die in diesem Kurs verwiesen wird. Sie sollen Ihr Lernen unterstützen. Alle diese Ressourcen finden Sie imRessourcenTab.
Wenn Sie in diesem Kurs auf nützliche Links stoßen, setzen Sie ein Lesezeichen darauf, damit Sie später auf die Informationen zurückgreifen können, um sie zu studieren oder zu überprüfen.
Verstehen und befolgen Sie dieCoursera-Verhaltenskodexum sicherzustellen, dass die Lerngemeinschaft für alle Mitglieder ein einladender, freundlicher und unterstützender Ort bleibt.
Business Intelligence treibt Veränderungen voran
Wie Sie erfahren haben, ist die Fähigkeit eines Unternehmens, Probleme zu erkennen, bevor sie zu Problemen werden, oder Chancen vor der Konkurrenz zu nutzen, der Schlüssel zu intelligenter Entscheidungsfindung. Wir haben heute mehr denn je Zugriff auf Daten über unseren Markt, unsere Organisationen, Kunden, Wettbewerber und Mitarbeiter. Aber um diese Daten schnell in Ergebnisse umzuwandeln, brauchen wir Business Intelligence. Bei Business Intelligence geht es um die Automatisierung von Prozessen und Informationskanälen, um relevante Daten in umsetzbare Erkenntnisse umzuwandeln, die Entscheidungsträgern leicht zur Verfügung stehen.
In dieser Lektüre werden Sie zwei Beispiele dafür untersuchen, wie BI echten Unternehmen geholfen hat, Erkenntnisse zu gewinnen, auf die richtigen Daten zuzugreifen und Wege zu finden, ihre Prozesse zu erweitern und zu verbessern, um diese Erkenntnisse in die Tat umzusetzen.
Restaurants reduzieren Abfall

Stellen Sie sich ein fiktives Szenario über eine Fast-Food-Restaurantkette vor. Führungskräfte dieses Unternehmens müssen riesige Datenmengen verwalten, wie zum Beispiel:
Kundentransaktionen
Marketingdaten im Zusammenhang mit Werbeaktionen
Kundenzufriedenheit
Mitarbeiterinformation
Und so viel mehr! Darüber hinaus muss das Unternehmen aber auch die Logistik für die einzelnen Restaurants berücksichtigen. Hier kommt das Problem ins Spiel.
Das Problem
Die Restaurants benötigen Zutaten zum Kochen und Bedienen der Kunden, aber wenn sie zu viel haben, wird der zusätzliche Vorrat oft verschwendet. Die Unternehmensleitung berät sich mit ihrem BI-Team, um zu überlegen, wie zwei Anliegen angegangen werden können:
So stellen Sie sicher, dass die zahlreichen Standorte der Restaurants über genügend Zutaten verfügen, um die Kundennachfrage zu befriedigen
So reduzieren Sie Lebensmittelverschwendung
Allerdings verfügen diese Interessengruppen derzeit nicht über Kennzahlen zur spezifischen Messung der Lebensmittelverschwendung oder über Strategien zu deren Reduzierung. Genau hier muss das BI-Team ansetzen.
Die Lösung
Um auf die Bedürfnisse der Stakeholder einzugehen, verbringt das BI-Team Zeit damit, Informationen über aktuelle Metriken und Prozesse zu sammeln. Anhand dieser Informationen ermitteln sie zunächst, über welche Daten sie verfügen und wie diese verwendet werden. Sie entdecken, dass es bereits nützliche Kennzahlen gibt, die von verschiedenen Teams im Unternehmen auf andere Weise angewendet werden, darunter:
Wie viele Zutaten werden an jeden Standort geliefert?
Wie viel wird täglich von jedem Menüpunkt zubereitet?
Wie viel von jedem Menüpunkt tatsächlich pro Tag bestellt wird
Durch den Vergleich dieser vorhandenen Kennzahlen kann das Unternehmen besser verstehen, wie viel Lebensmittel verschwendet werden. Dadurch sind die BI-Analysten in der Lage, die notwendigen Informationen zu eingehenden Lebensmittellieferungen, Kundenbestellungen und Lebensmittelverbrauch in Form eines Dashboards zu sammeln, damit Stakeholder die Lebensmittelverschwendung überwachen können. Die BI-Analysten organisieren diese Daten dann in den Datenbanksystemen und stellen sie in neuen Tabellen bereit, die die Ergebnisse melden, damit die Stakeholder sie bei der Entwicklung einer Strategie zur Reduzierung der Lebensmittelverschwendung berücksichtigen können.
Die Ergebnisse
Wenn die Beteiligten jetzt wissen, wie viele Lebensmittel tatsächlich verschwendet werden, können sie ihre Ziele besser erreichen. Die Restaurantkette stellt fest, dass die größte Quelle der Lebensmittelverschwendung Pommes Frites sind. An ihren Standorten bleiben am Monatsende 10–20 % der Pommes Frites übrig. Mit diesen Informationen sendet das zentrale Betriebsteam des Unternehmens ein Memo an alle Filialen, in dem es ihnen empfiehlt, ihre eingehenden Pommes-Frites-Lieferungen um 10 % zu reduzieren. Auf diese Weise können die BI-Analysten dem Unternehmen dabei helfen, einen Bereich mit Verbesserungspotenzial zu identifizieren und Verschwendung zu reduzieren.
Krankenhäuser fördern die Patientenversorgung

Krankenhäuser müssen außerdem viele verschiedene Arten von Daten verwalten – insbesondere Patienteninformationen. Sie verfügen außerdem über eine Vielzahl von Datenquellen, auf die sie zugreifen und die sie teilen müssen, um sicherzustellen, dass andere verbundene Benutzer – beispielsweise Ärzte, die außerhalb des Krankenhauses arbeiten – ihren Patienten die Behandlung bieten können, die sie benötigen, ohne Zeit oder Ressourcen zu verschwenden.
Das Problem
Stellen Sie sich für dieses Szenario ein Krankenhaussystem vor, das vor der Herausforderung steht, effektiv mit Ärzten zu kommunizieren, die nicht im selben Krankenhaussystem arbeiten. Administratoren haben festgestellt, dass dies zu verschiedenen Problemen führt:
Ärzte außerhalb des Systems haben keinen Zugriff auf Testergebnisse des Krankenhauses
Patienten werden mehrfach getestet
Dies ist sowohl für das Krankenhaus als auch für die Patienten teuer und ineffizient. Deshalb entscheiden sich Entscheidungsträger dafür, mit einem Team von BI-Spezialisten zusammenzuarbeiten, um Datenbanksysteme zu erstellen, die Daten in die Hände von Ärzten bringen, die sie benötigen.
Die Lösung
Grundsätzlich besteht in diesem Krankenhaussystem ein Problem im Zusammenhang mit nicht zugänglichen Patientendaten. Es strömen viele Daten aus mehreren Quellsystemen ein, die an einem Ziel konsolidiert werden müssen, das von Ärzten genutzt werden kann, einschließlich Informationen über:
Frühere Besuche
Tests
Allergien
Und andere relevante medizinische Informationen. Deshalb entwickelt das BI-Team ein Pipeline-System, das Daten aus allen wichtigen Quellen aufnimmt, verarbeitet und transformiert, sodass sie konsistent sind, und sie an ein Datenbanksystem liefert, wo Ärzte auf alle benötigten Informationen zugreifen können.
Die Ergebnisse
Durch die Zusammenführung der vielen Datenquellen des Krankenhauses in einer konsolidierten Datenbank trägt das BI-Team dazu bei, dem Krankenhaus Geld und Ressourcen zu sparen, indem es doppelte Tests eliminiert. Jetzt sind Ärzte besser in der Lage, Patienten zu behandeln, Patienten sparen Geld für überflüssige Tests und Verfahren und das Krankenhaus kann effizienter arbeiten. Dies alles ist den vom BI-Team entwickelten Tools zu verdanken!
Die zentralen Thesen
Unabhängig davon, in welcher Branche Sie tätig sind, kann BI Prozesse und Informationskanäle automatisieren, um den Menschen, die diese Daten benötigen, die Möglichkeit zu geben, Fragen zu beantworten und Entscheidungen zu treffen. Von Restaurants, die Abfall reduzieren, bis hin zu Krankenhäusern, die die Patientenversorgung verbessern – BI-Analysten erstellen Systeme und Tools, um Bedürfnisse zu antizipieren und es Unternehmen zu ermöglichen, ihre Ziele zu erreichen.
Aktivitätsbeispiel: Vervollständigen Sie die Business-Intelligence-Dokumente
Bewertung von Exemplar

In dieser Aktivität haben Sie das Ausfüllen wichtiger BI-Planungsdokumente anhand eines realistischen Szenarios geübt. In dem Szenario fehlten absichtlich wichtige Informationen. Daher bestand ein Teil Ihrer Aufgabe darin, herauszufinden, was Ihnen fehlte, und Folgefragen zu entwickeln, die Sie den Stakeholdern stellen konnten. Diese Aktivität bereitet Sie darauf vor, diese Formulare in zukünftigen Projekten im Laufe Ihrer Karriere auszufüllen.
Projektplanungsdokumente helfen Ihnen, die Bedürfnisse und Erwartungen Ihrer Stakeholder zu verstehen. Dadurch können Sie effektiv mit ihnen kommunizieren und besser verstehen, wie das Projekt abgeschlossen werden kann. Sie können ermitteln, welche Informationen Ihnen bei der Erfüllung der Projektanforderungen am meisten helfen.
Ihre Dokumente müssen nicht perfekt mit diesen Vorlagen übereinstimmen. Ziel ist es, die Informationen richtig in den richtigen Feldern zu organisieren und zu verstehen, wie Planungsdokumente Ihnen bei der Vorbereitung eines BI-Projekts helfen. Dies ist eine Gelegenheit für Sie, Ihr Verständnis zu überprüfen, sicherzustellen, dass Sie die Erwartungen der Aktivität erfüllt haben, und eine mögliche Lösung zu prüfen.
Im Beispiel des Stakeholder-Anforderungsdokuments werden Sie feststellen, dass Bereiche, in denen Ihnen Informationen fehlen, fett hervorgehoben sind. Bei Ihren eigenen Projekten kann es hilfreich sein, direkt im Dokument zu vermerken, was Ihnen fehlt. Wenn Sie dann weitere Fragen stellen, können Sie diese Notizen durch die richtigen Informationen ersetzen.
Die meisten Informationen in diesen Dokumenten stammen direkt aus den Notizen im Szenario der Aktivität. Sie können auch etwas umformulieren, um die Notizen aus der Besprechung zusammenzufassen oder zu erweitern. In den Notizen heißt es beispielsweise: „Ziel ist es zu verstehen, wie diese Käufer und Verkäufer ihre Plattform nutzen.“ Die Erkenntnisse könnten dann in das Design neuer Produkte einfließen und die Plattform verbessern.“ Sie könnten dies in den Abschnitt „Geschäftsprobleme“ des Planungsdokuments übersetzen, indem Sie es so formulieren: „Wie nutzen Käufer und Verkäufer die Plattform von MarkIt?“ Wie kann MarkIt seine Plattform verbessern?“ Dadurch wird die Sprache in den Notizen als Frage und nicht als Aussage formuliert.
Im Beispiel des Projektanforderungsdokuments müssen Sie jede Anfrage des Stakeholders als „erforderlich“, „erwünscht“ oder „nice to have“ zuweisen. Einen Hinweis darauf, was wo hingehört, finden Sie in der Sprache der Stakeholder. In den Szenarionotizen könnten einige der Anfragen „muss“ enthalten, während andere möglicherweise „können wir?“ enthalten. oder „sollte“.
Sie werden außerdem feststellen, dass dieses Dokument weitere Felder enthält, in denen Informationen fehlen. Dies kann Hinweise darauf geben, was Sie in Folgebesprechungen fragen sollten.
Das Exemplar des Strategiedokuments ist das längste Dokument und weist mehr fehlende Informationen auf. Da Sie aber in dieser Phase bestimmen können, welche Arten von Diagrammen Sie erstellen möchten, können Sie viele Ihrer Antworten Ihrem besten Ermessen überlassen. Sofern Ihnen der Stakeholder nicht sagt, welche Arten von Diagrammen er möchte, müssen Sie Ihr BI-Fachwissen nutzen, um zu entscheiden, was am besten funktioniert. In diesem Szenario haben Ihnen die Stakeholder keine Vorschläge für Diagrammtypen gemacht. Dies bedeutet, dass Sie die Entscheidungen selbst treffen oder sich dazu entschließen können, den Stakeholder um weitere Beratung zu bitten.
Im Strategiedokument können Sie auch eine Skizze eines Modells einfügen.

Dieses Modell enthält Filter für Zeitskalen, z. B. täglich, wöchentlich und monatlich. Es enthält den aktuellen Status und Verlaufsdiagramme der folgenden Kennzahlen: abgeschlossene Verkäufe, veröffentlichte Angebote, entfernte Angebote und beliebte Suchbegriffe. Es verfügt über ein Balkendiagramm, das die gesamte Site-Nutzung mit der durchschnittlichen Site-Nutzung pro Benutzer vergleicht. Außerdem gibt es ein Balkendiagramm mit der Verteilung der Kontaktmethoden, die zum Einreichen von Supportanfragen verwendet werden.
Diese Skizze stellt einen ersten Entwurf dar, wie Ihr Dashboard aussehen könnte, wenn Sie in die Visualisierungsphase eines BI-Projekts gelangen. Später in diesem Programm erfahren Sie mehr über Mockups, einschließlich der Verwendung eines Mockups zum Planen eines Dashboards.
Die zentralen Thesen
Das Ausfüllen von Planungsdokumenten ist eine hilfreiche Möglichkeit, Details aus Ihren Gesprächen mit Stakeholdern zu organisieren und sich auf ein Business-Intelligence-Projekt vorzubereiten. Sie werden diese Fähigkeiten später in diesem Kurs anwenden, wenn Sie Ihr eigenes BI-Projekt beginnen.
Fallstudie: FeatureBase, Teil 1: Feinabstimmung von Metriken für die Datenerfassung
In diesem Kurs haben Sie über die Phasen des Business Intelligence-Prozesses nachgedacht. Diese Fallstudie mit FeatureBase konzentriert sich auf die Erfassungsphase des BI-Prozesses, in der Sie statische, rückwärtsgerichtete Daten untersuchen und die nächsten beiden Phasen des Projekts planen. In zwei weiteren Fallstudien erfahren Sie, wie FeatureBase die Analyse- und Überwachungsphasen dieses Projekts angegangen ist. Zunächst müssen Sie jedoch das Problem, den Prozess und die Lösungen für diese erste Phase des Projekts verstehen.

Als BI-Experte werden Sie einen Mehrwert für die Organisationen schaffen, mit denen Sie zusammenarbeiten. Ihr Fachwissen wird Unternehmen dabei helfen, auf die richtigen Daten zuzugreifen, Daten zu nutzen, um Wachstums- und Verbesserungsmöglichkeiten zu finden, und diese Erkenntnisse in die Tat umzusetzen. Während dieses Zertifikatsprogramms haben Sie die Möglichkeit zu erfahren, wie verschiedene Unternehmen mithilfe von Business Intelligence reale Herausforderungen gemeistert haben. In dieser Lektüre werden Sie vorgestelltFeatureBase, ein operatives KI-Unternehmen in Austin, Texas. In den drei Kursen werden Sie auf drei Fallstudien stoßen, die die Herangehensweise des FeatureBase-Teams an ein tatsächliches Problem verfolgen, mit dem es konfrontiert war. Dies ist ein großartiges Beispiel dafür, wie ein echtes Unternehmen ein BI-Problem gelöst und ein ganzes Projekt abgeschlossen hat – angefangen mit der Identifizierung eines Problems und der Vorbereitung auf die Lösung!

Firmenhintergrund
FeatureBase entwickelt Technologien, die den Wert von Daten erschließen, sobald sie erstellt werden. Das in Austin, Texas, ansässige Team und die Community bestehen aus Datenbank-, verteilten System- und Cloud-Ingenieuren sowie führenden Forschern für Bitmap-Innovationen. Der CEO von FeatureBase, HO Maycotte, und die Gründungsingenieure arbeiten seit fast 20 Jahren daran, eine Lücke im Datenbankmarkt zu schließen und ein neues Datenformat zu entwickeln, das speziell darauf ausgelegt ist, schnellere Berechnungen zu ermöglichen.
Ihre Kerntechnologie, FeatureBase, ist die erste OLAP-Datenbank, die vollständig auf Bitmaps basiert und Echtzeitanalysen und Anwendungen für maschinelles Lernen ermöglicht, indem sie gleichzeitig niedrige Latenz, hohen Durchsatz und hochgradig gleichzeitige Arbeitslasten ausführt.
Die Herausforderung
Das Vertriebsteam stellte fest, dass ein erheblicher Teil der potenziellen Kunden während des Verkaufszyklus abwanderte. Als sie dieses Muster entdeckten, stellten sie fest, dass sie nicht über die Daten verfügten, die sie brauchten, um wirklich zu erkennen, wann Kunden abwanderten. Und wenn sie nicht feststellen konnten, wann die Kunden abfielen, konnten sie auch nicht herausfinden, warum. Und herauszufinden, warum, war der Schlüssel zur Entwicklung von Lösungen zur Bewältigung dieses Problems.
Die Vorgehensweise
Die erste Frage lautete: „Warum haben wir unser vierteljährliches Umsatzziel nicht erreicht?“ Um diese Frage zu beantworten, musste das FeatureBase-Team wissen, warum die Leute abgesetzt wurden und wann die Absetzung erfolgte. Aber sie verfügten nicht über die in ihre Datenbank integrierten Metriken, um das tatsächlich zu messen. Um diese Frage in ihre Datensammlung einzubauen, mussten sie experimentieren, welche Daten tatsächlich nützlich waren, neue Attribute hinzufügen und ihre Metriken verfeinern. Für dieses spezielle Projekt war die Lösung klar: den bestehenden Verkaufstrichter mit Schlüsselattributen zu jedem potenziellen Kunden in jeder Phase des Projekts neu erstellen.
Zu diesem Zweck haben der Vertriebsleiter, der Marketingleiter und der CEO gemeinsam über neue Kennzahlen und deren Implementierung im System entschieden. Es waren einige Experimente erforderlich – das Team war bestrebt, seinen Datenerfassungsprozess zu iterieren und zu optimieren, um diese Lösung zu optimieren. Tuning ist oft ein wirklich notwendiger Teil der Entwicklung zukunftsweisender Lösungen; Das erste Modell ist meist nicht das beste. Es ist ein erster Entwurf; Sie müssen es überarbeiten, um die optimalste Version der Lösung zu erhalten! Als BI-Experte müssen Sie in der Realität möglicherweise einige Iterationen durchführen, um Ihr Modell dorthin zu bringen, wo Sie es benötigen.
Der nächste Schritt
Als BI-Experte kommt es vor, dass Ihnen eine Frage gestellt wird, für deren Beantwortung Sie nicht über ausreichende Daten verfügen. Manchmal müssen Sie weiter graben, weiter recherchieren und darüber nachdenken, wie Sie eine aufschlussreiche Antwort liefern können, die Ihr Team tatsächlich nutzen kann. In diesem Fall stellte das FeatureBase-Team fest, dass es einen Trend beobachtet hatte, konnte jedoch anhand der vorhandenen Daten nicht feststellen, um welchen Trend es sich handelte und wie man darauf reagieren sollte. Der erste Schritt bestand darin, zu entscheiden, welche Metriken implementiert werden könnten, um tatsächlich nützliche Beobachtungen zu erfassen. Als Team arbeiteten sie zusammen und optimierten ihre Datenerfassungsprozesse. Im nächsten Kurs erfahren Sie mehr darüber, wie sie diese neuen Prozesse tatsächlich in ihre Datenbanksysteme implementiert haben, welche Tools sie verwendet haben und wie sie dadurch zum Erfolg geführt haben.
Wenn Sie mehr über den Ansatz von FeatureBase zur Beantwortung dieser Frage erfahren möchten, finden Sie weitere Informationen in der FeatureBaseZweiter TeilUndTeil dreiLesungen, die in kommenden Kursen vorgestellt werden.
Kennen Sie Ihre Stakeholder und deren Ziele
Zuvor haben Sie die vier verschiedenen Arten von Stakeholdern kennengelernt, denen Sie als Business-Intelligence-Experte begegnen können:
Projektsponsor: Eine Person, die Unterstützung und Ressourcen für ein Projekt bereitstellt und für dessen Erfolg verantwortlich ist.
Entwickler : Eine Person, die Programmiersprachen verwendet, um Softwareanwendungen zu erstellen, auszuführen, zu testen und Fehler zu beheben. Dazu gehören Anwendungssoftwareentwickler und Systemsoftwareentwickler.
Systemanalytiker: Eine Person, die Möglichkeiten zur Gestaltung, Implementierung und Weiterentwicklung von Informationssystemen identifiziert, um sicherzustellen, dass diese zur Erreichung von Geschäftszielen beitragen.
Geschäftsinteressenten: Zu den Geschäftsinteressenten können eine oder mehrere der folgenden Personengruppen gehören:
Das Führungsteam: Das Führungsteam übernimmt die strategische und operative Führung des Unternehmens. Sie setzen Ziele, entwickeln Strategien und stellen sicher, dass die Strategie effektiv umgesetzt wird. Das Führungsteam könnte aus Vizepräsidenten, dem Chief Marketing Officer und hochrangigen Fachleuten bestehen, die bei der Planung und Leitung der Arbeit des Unternehmens helfen.
Das kundenorientierte Team: Das kundenorientierte Team umfasst jeden in einer Organisation, der in gewissem Maße mit Kunden und potenziellen Kunden interagiert. Typischerweise sammeln sie Informationen, legen Erwartungen fest und übermitteln Kundenfeedback an andere Teile der internen Organisation.
Das Data-Science-Team : Das Data-Science-Team untersucht die bereits vorhandenen Daten und findet Muster und Erkenntnisse, die Datenwissenschaftler nutzen können, um zukünftige Trends durch maschinelles Lernen aufzudecken. Dazu gehören Datenanalysten, Datenwissenschaftler und Dateningenieure.
Nachdem Sie nun mit diesen verschiedenen Arten von Stakeholdern besser vertraut sind, erkunden Sie, wie sie in einem tatsächlichen Geschäftskontext funktionieren.

Das Geschäft
In diesem Szenario sind Sie ein BI-Experte, der für ein E-Book-Einzelhandelsunternehmen arbeitet. Das kundenorientierte Team ist daran interessiert, die über die E-Reading-App des Unternehmens gesammelten Kundendaten zu nutzen, um die Lesegewohnheiten der Benutzer besser zu verstehen und die App dann entsprechend zu optimieren. Sie haben Sie gebeten, ein System zu erstellen, das Kundendaten über Einkäufe und Lesezeiten in der App erfasst, damit die Daten für ihre Analysten zugänglich sind. Bevor Sie jedoch beginnen können, müssen Sie alle Bedürfnisse und Ziele Ihrer Stakeholder verstehen, um ihnen bei der Verwirklichung dieser Ziele zu helfen.
Die Stakeholder und ihre Ziele
Projektsponsor
Ein Projektsponsor ist die Person, die Unterstützung und Ressourcen für ein Projekt bereitstellt und für dessen Erfolg verantwortlich ist. In diesem Fall ist der Projektsponsor der Teamleiter des kundenorientierten Teams. Aus Ihren Gesprächen mit diesem Team wissen Sie, dass es an einer Optimierung der E-Reading-App interessiert ist. Dazu benötigen sie ein System, das Kundendaten über Käufe und Lesezeiten an eine Datenbank liefert, mit der ihre Analysten arbeiten können. Mithilfe dieser Daten können die Analysten dann Erkenntnisse über Kaufgewohnheiten und Lesezeiten gewinnen, um herauszufinden, welche Genres am beliebtesten sind, wie lange Leser die App nutzen und wie oft sie neue Bücher kaufen, um Empfehlungen für das UI-Design abzugeben Team.
Entwickler
Die Entwickler sind die Personen, die Programmiersprachen verwenden, um Softwareanwendungen zu erstellen, auszuführen, zu testen und Fehler zu beheben. Dazu gehören Anwendungssoftwareentwickler und Systemsoftwareentwickler. Wenn Ihr neuer BI-Workflow Softwareanwendungen und Tools umfasst oder Sie neue Tools erstellen müssen, müssen Sie mit den Entwicklern zusammenarbeiten. Ihr Ziel besteht darin, die Softwaretools Ihres Unternehmens zu erstellen und zu verwalten. Daher müssen sie verstehen, welche Tools Sie verwenden möchten und wofür Sie diese Tools benötigen. In diesem Beispiel sind die Entwickler, mit denen Sie zusammenarbeiten, für die Verwaltung der in der E-Reading-App erfassten Daten verantwortlich.
System-Analytiker
Der Systemanalytiker identifiziert Möglichkeiten zur Gestaltung, Implementierung und Weiterentwicklung von Informationssystemen, um sicherzustellen, dass sie zur Erreichung von Geschäftszielen beitragen. Ihr Hauptziel besteht darin, zu verstehen, wie das Unternehmen seine Computerhardware und -software, Cloud-Dienste und verwandte Technologien nutzt, und dann herauszufinden, wie diese Tools verbessert werden können. Der Systemanalyst sorgt also dafür, dass die von den Entwicklern erfassten Daten intern als Rohdaten abgerufen werden können.
Geschäftsinteressenten
Neben dem kundenorientierten Team, das der Projektsponsor für dieses Projekt ist, gibt es möglicherweise auch andere Geschäftsinteressenten für dieses Projekt, wie z. B. Projektmanager, leitende Fachkräfte und andere Führungskräfte. Diese Stakeholder sind daran interessiert, die Geschäftsstrategie für das gesamte Unternehmen zu steuern. Ihr Ziel ist es, Geschäftsprozesse weiter zu verbessern, den Umsatz zu steigern und die Unternehmensziele zu erreichen. So kann Ihre Arbeit sogar den Chief Technology Officer erreichen! Dabei handelt es sich im Allgemeinen um Menschen, die umfassendere Einblicke benötigen, die ihnen dabei helfen, Entscheidungen in größerem Maßstab zu treffen, im Gegensatz zu detailorientierten Einblicken in Softwaretools oder Datensysteme.
Abschluss
An BI-Projekten sind häufig viele Teams und Stakeholder beteiligt, die je nach Funktion innerhalb der Organisation unterschiedliche Ziele verfolgen. Es ist wichtig, ihre Perspektiven zu verstehen, da Sie so eine Vielzahl von Anwendungsfällen für Ihre BI-Tools berücksichtigen können. Und je nützlicher Ihre Tools sind, desto wirkungsvoller werden sie sein!
Best Practices für die Kommunikation mit Stakeholdern
Wie Sie erfahren haben, ist die Fähigkeit, effektiv mit Stakeholdern und Projektpartnern zu kommunizieren, der Schlüssel zu Ihrem Erfolg als Business-Intelligence-Experte. In diesem Bereich geht es nicht nur um die Entwicklung von BI-Tools. Es geht darum, diese Tools den Benutzern zugänglich zu machen, um ihnen die Daten zur Verfügung zu stellen, die sie für ihre Entscheidungen benötigen. In dieser Lektüre besprechen Sie wichtige Kommunikationsstrategien und entdecken neue Best Practices, die Ihnen in Zukunft helfen werden. Sie werden auch die Bedeutung von Fairness und der Vermeidung von Voreingenommenheit in BI erkunden.
Machen Sie BI für Stakeholder zugänglich
Bisher haben Sie drei Schlüsselstrategien für die Kommunikation kennengelernt:
Stellen Sie die richtigen Fragen
Definieren Sie Projektergebnisse
Teilen Sie Business Intelligence effektiv
Der Austausch von Business Intelligence kann kompliziert sein; Sie müssen in der Lage sein, technische Prozesse zu vereinfachen, damit sie für eine Vielzahl von Benutzern unkompliziert und zugänglich sind, die die Begriffe oder Konzepte möglicherweise noch nicht verstehen. Die Fähigkeit, Informationen klar und prägnant darzustellen, ist von entscheidender Bedeutung, um sicherzustellen, dass Stakeholder die von Ihnen erstellten Systeme tatsächlich nutzen und auf der Grundlage dieser Erkenntnisse handeln können.
Es gibt einige Fragen, die Sie im Hinterkopf behalten können, um Ihre Kommunikation mit Stakeholdern und Partnern zu leiten:
Wer ist Ihr Publikum? Bei der Kommunikation mit Stakeholdern und Projektpartnern ist es wichtig zu berücksichtigen, mit wem Sie zusammenarbeiten. Berücksichtigen Sie bei der Kommunikation alle Personen, die die von Ihnen erstellten BI-Tools und -Prozesse verstehen müssen. Das Vertriebs- oder Marketingteam hat andere Ziele und Fachkenntnisse als beispielsweise das Data-Science-Team.
Was wissen sie bereits? Da verschiedene Benutzer über unterschiedliche Kenntnisse und Fachkenntnisse verfügen, kann es sinnvoll sein, vor der Kommunikation mit ihnen zu prüfen, was sie bereits wissen. Dies bietet eine Grundlage für Ihre Kommunikation und verhindert, dass Sie sich zu sehr erklären oder wichtige Informationen überspringen.
Was müssen sie wissen? Unterschiedliche Stakeholder benötigen unterschiedliche Arten von Informationen. Beispielsweise möchte ein Benutzer möglicherweise verstehen, wie er auf die Daten oder die von Ihnen erstellten Dashboards zugreift und diese verwendet, ist aber wahrscheinlich nicht so sehr an den genauen Details darüber interessiert, wie die Daten bereinigt wurden.
Wie können Sie am besten kommunizieren, was sie wissen müssen? Nachdem Sie über Ihre Zielgruppe nachgedacht haben, was sie bereits weiß und was sie wissen müssen, müssen Sie entscheiden, wie Sie ihnen diese Informationen am besten mitteilen können. Dies kann ein E-Mail-Bericht, ein kleines Meeting oder eine teamübergreifende Präsentation mit einem Frage-und-Antwort-Bereich sein.
Neben diesen Fragen gibt es noch einige weitere Best Practices für die Kommunikation mit Stakeholdern.

Erstellen Sie realistische Fristen. Erstellen Sie vor Beginn eines Projekts eine Liste der Abhängigkeiten und potenziellen Hindernisse, damit Sie einschätzen können, wie viel zusätzliche Zeit Sie sich nehmen sollten, wenn Sie die Projekterwartungen und Zeitpläne mit Ihren Stakeholdern besprechen.
Kennen Sie Ihr Projekt. Wenn Sie gut verstehen, warum Sie ein neues BI-Tool entwickeln, kann es Ihnen helfen, Ihre Arbeit mit größeren Initiativen zu verknüpfen und dem Projekt Bedeutung zu verleihen. Verfolgen Sie Ihre Diskussionen über das Projekt per E-Mail oder in Besprechungsnotizen und seien Sie bereit, Fragen dazu zu beantworten, wie wichtig bestimmte Aspekte für Ihr Unternehmen sind. Kurz gesagt, es sollte leicht verständlich sein und den Wert erklären, den das Projekt für das Unternehmen bringt.
Kommunizieren Sie oft. Ihre Stakeholder möchten regelmäßige Updates. Behalten Sie den Überblick über wichtige Projektmeilensteine, Rückschläge und Änderungen. Eine weitere großartige Ressource ist ein Änderungsprotokoll, das eine chronologisch geordnete Liste der Änderungen bereitstellen kann. Anschließend erstellen Sie mithilfe Ihrer Notizen einen Bericht in einem Dokument, das Sie mit Ihren Stakeholdern teilen.
Priorisieren Sie Fairness und vermeiden Sie voreingenommene Erkenntnisse
Bei BI geht es darum, Stakeholdern die Daten und Tools zur Verfügung zu stellen, die sie benötigen, um fundierte, intelligente Geschäftsentscheidungen zu treffen. Ein Teil davon besteht darin, sicherzustellen, dass Sie ihnen helfen, faire und integrative Entscheidungen zu treffen. Fairness in der Datenanalyse bedeutet, dass die Analyse keine Voreingenommenheit erzeugt oder verstärkt (eine bewusste oder unbewusste Präferenz für oder gegen eine Person, Personengruppe oder Sache). Mit anderen Worten: Sie möchten dazu beitragen, Systeme zu schaffen, die für alle fair und inklusiv sind.
Als BI-Experte liegt es in Ihrer Verantwortung, so objektiv wie möglich zu bleiben und zu versuchen, die vielen Seiten eines Arguments zu erkennen, bevor Sie Schlussfolgerungen ziehen. Das Beste, was Sie für die Fairness und Genauigkeit Ihrer Daten tun können, besteht darin, sicherzustellen, dass Sie mit Daten beginnen, die auf die angemessenste und objektivste Weise erfasst wurden. Dann verfügen Sie über Fakten, die Sie an Ihr Team weitergeben können.
Ein großer Teil Ihrer Arbeit wird darin bestehen, Daten in einen Kontext zu bringen. Kontext ist der Zustand, in dem etwas existiert oder geschieht; Im Grunde geht es dabei um das Wer, Was, Wo, Wann, Wie und Warum der Daten. Wenn Sie Daten präsentieren, sollten Sie sicherstellen, dass Sie Informationen bereitstellen, die diese Fragen beantworten:
WER hat die Daten gesammelt?
Worum geht es? Was stellen die Daten in der Welt dar und in welcher Beziehung stehen sie zu anderen Daten?
WANN wurden die Daten erhoben?
WOHER stammen die Daten?
WIE wurde es gesammelt? Und wie wurde es für das Reiseziel verändert?
WARUM wurden diese Daten erhoben? Warum ist es für die Geschäftsaufgabe nützlich oder relevant?
Eine Möglichkeit, dies zu erreichen, besteht darin, klarzustellen, dass sich alle von Ihnen geteilten Ergebnisse auf einen bestimmten Datensatz beziehen. Dies kann dazu beitragen, unfaire oder ungenaue Verallgemeinerungen zu vermeiden, die Stakeholder möglicherweise auf der Grundlage Ihrer Erkenntnisse vornehmen möchten. Stellen Sie sich zum Beispiel vor, Sie analysieren einen Datensatz der Lieblingsaktivitäten von Menschen in einer bestimmten Stadt in Kanada. Der Datensatz wurde durch telefonische Befragungen von Haustelefonnummern während der Geschäftszeiten am Tag erhoben. Hier liegt sofort eine Voreingenommenheit vor. Nicht jeder hat ein Telefon zu Hause und nicht jeder ist tagsüber zu Hause. Daher können Erkenntnisse aus diesem Datensatz nicht so verallgemeinert werden, dass sie die Meinung der gesamten Bevölkerung dieser Stadt widerspiegeln. Es sollten weitere Untersuchungen durchgeführt werden, um die demografische Zusammensetzung dieser Personen zu bestimmen.
Sie müssen außerdem sicherstellen, dass die Art und Weise, wie Sie Ihre Daten präsentieren – sei es in Form von Visualisierungen, Dashboards oder Berichten – eine faire Interpretation durch die Stakeholder fördert. Sie haben beispielsweise gelernt, Farbschemata zu verwenden, die für farbenblinde Personen zugänglich sind. Andernfalls könnten Ihre Erkenntnisse für diese Stakeholder schwer verständlich sein
Die zentralen Thesen
Für einen BI-Experten ist es wichtig, Stakeholdern Tools zur Verfügung stellen zu können, mit denen sie jederzeit auf Daten zugreifen können, und über das Wissen zu verfügen, das sie zur Verwendung dieser Tools benötigen. Ihr vorrangiges Ziel sollte es immer sein, Stakeholdern faire, kontextualisierte Einblicke in Geschäftsprozesse und Trends zu geben. Durch effektive Kommunikation können Sie dafür sorgen, dass dies geschieht.
Warum der Kontext entscheidend ist
In dieser Lektion haben Sie etwas über die Bedeutung des Kontexts in der Business Intelligence gelernt. Zur Erinnerung: Kontext ist der Zustand, in dem etwas existiert oder geschieht. In einem früheren Video haben Sie beispielsweise diese Datenvisualisierung betrachtet:

Dieses Liniendiagramm zeigt lediglich fünf verschiedene Linien in einem Raster, wir haben jedoch keine Informationen darüber, was die Linien des Diagramms darstellen, wie sie gemessen werden oder welche Bedeutung diese Visualisierung hat. Das liegt daran, dass dieser Visualisierung der Kontext fehlt. Schauen Sie sich die fertige Version dieser Visualisierung an:

Diese Visualisierung enthält alle Informationen, die zu ihrer Interpretation erforderlich sind. Es hat einen klaren Titel, eine Legende, die angibt, was die Linien im Diagramm bedeuten, eine Skala entlang der y-Achse und den Datumsbereich, der entlang der x-Achse dargestellt wird. Die Kontextualisierung von Daten trägt dazu bei, dass sie für Ihre Stakeholder aussagekräftiger und nützlicher werden und verhindert Fehlinterpretationen der Daten, die sich auf ihre Entscheidungsfindung auswirken könnten. Und das gilt nicht nur für die Visualisierung! In dieser Lektüre untersuchen Sie einen Geschäftsfall, bei dem der Kontext der Schlüssel zum Erfolg eines BI-Projekts war.
Das Szenario
Das CloudIsCool-Supportteam bietet Support für Benutzer ihrer Cloud-Produkte. Jedes Mal, wenn ein Benutzer den Support kontaktiert, wird ein Kundensupport-Ticket erstellt. Ein First-Response-Team ist für die Bearbeitung dieser Kundensupport-Tickets zuständig. Wenn es sich jedoch um ein besonders komplexes Ticket handelt, kann ein Mitglied des ersten Reaktionsteams das zweite Reaktionsteam um Hilfe bitten. Dies wird im Ticketsystem als Beratung kategorisiert. Das Analyseteam analysiert das Ticket und konsultiert Daten, um die Kundensupportprozesse zu verbessern.
Normalerweise wird die Beratungsanfrage erfolgreich erfüllt und das Erstreaktionsteam kann das Ticket des Kunden mithilfe der Anleitung des Zweitreaktionsteams lösen. Manchmal ist jedoch selbst das zweite Reaktionsteam nicht in der Lage, die Frage vollständig zu beantworten, oder neue Details zum Fall erfordern zusätzliche Erkenntnisse. In diesem Fall bittet das Erstreaktionsteam möglicherweise um eine weitere Konsultation, die als erneute Konsultation bezeichnet wird.
Dies alles ist ein wichtiger Kontext für einen BI-Experten, der mit Stakeholdern zusammenarbeitet, die daran interessiert sind, wie gut aktuelle Supportprozesse funktionieren und wie sie verbessert werden könnten. Wenn sie Berichtstabellen und Dashboards erstellen, die nur Konsultationen und keine erneuten Konsultationen verfolgen, verpassen sie möglicherweise wichtige Erkenntnisse darüber, wie effektiv das Konsultationssystem wirklich ist. Eine hohe Wiederkonsultationsrate würde beispielsweise bedeuten, dass mehr Fälle nicht im ersten oder zweiten Versuch gelöst werden. Dies könnte dazu führen, dass Kunden länger auf die Lösung ihrer Probleme warten. Die Führung möchte diese Prozesse bewerten.
Wenn der BI-Experte, der an diesem Projekt arbeitet, diesen Kontext kennt, ist er in der Lage, geeignete Metriken, Berichtstabellen und das Dashboard zu erstellen, das diese Metrik auf eine Weise verfolgt, die den Stakeholdern hilft, fundierte Entscheidungen über diesen Prozess zu treffen. Durch das Verständnis des Geschäftskontexts können BI-Experten aussagekräftigere Berichte erstellen.
Abschluss
Der Kontext ist das Wer, Was, Wo, Wann und Warum der Daten, die sie aussagekräftig machen. Die Kenntnis dieser Hintergrundinformationen hilft uns, Daten richtig zu interpretieren und nützliche Business-Intelligence-Erkenntnisse für Stakeholder zu visualisieren. Wenn BI-Experten den Kontext verstehen, die richtigen Daten auswählen und kontextualisierte Visuals erstellen, um sie mit Stakeholdern zu teilen, können sie Unternehmen und Führungskräfte in die Lage versetzen, erfolgreiche Entscheidungen zu treffen.
Datenethik und die Bedeutung des Datenschutzes
Kürzlich haben Sie erfahren, wie wichtig der Kontext in der Business Intelligence ist. Sie haben festgestellt, dass Sie bei der Kontextualisierung etwas ins rechte Licht rücken, indem Sie seinen Ursprung und andere relevante Hintergrundinformationen berücksichtigen. die Motivation dahinter; der größere Kontext, in dem es existiert, beispielsweise ein bestimmter Zeitraum; und worauf es Auswirkungen haben könnte. Die Kontextualisierung fördert außerdem die Fairness und verringert das Risiko von Vorurteilen, wenn Ihre Benutzer nützliche Erkenntnisse aus den von Ihnen präsentierten Daten gewinnen möchten.
Ebenso haben Sie als BI-Experte die Verantwortung, Daten ethisch zu behandeln. Datenethik bezieht sich auf fundierte Standards für richtig und falsch, die vorschreiben, wie Daten gesammelt, weitergegeben und verwendet werden. Im Laufe Ihrer Karriere werden Sie mit vielen Daten arbeiten. Dazu gehören manchmal PII oder persönlich identifizierbare Informationen, die allein oder zusammen mit anderen Daten verwendet werden können, um die Identität einer Person herauszufinden. Ein Element des ethischen Umgangs mit diesen Daten besteht darin, sicherzustellen, dass die Privatsphäre und Sicherheit dieser Daten während ihrer gesamten Lebensdauer gewahrt bleibt. In dieser Lektüre erfahren Sie mehr über die Bedeutung des Datenschutzes und einige Strategien zum Schutz der Privatsphäre betroffener Personen.
Datenschutz ist wichtig
Datenschutz bedeutet, die Informationen und Aktivitäten einer betroffenen Person bei jeder Datentransaktion zu schützen. Dies wird auch als Informationsgeheimhaltung oder Datenschutz bezeichnet. Der Datenschutz befasst sich mit dem Zugriff, der Nutzung und der Erhebung personenbezogener Daten. Für die Personen, deren Daten erfasst werden, bedeutet dies, dass sie das Recht haben:
Schutz vor unbefugtem Zugriff auf Ihre privaten Daten
Freiheit von unangemessener Nutzung ihrer Daten
Das Recht, ihre Daten einzusehen, zu aktualisieren oder zu korrigieren
Möglichkeit, der Datenerfassung zuzustimmen
Gesetzliches Recht auf Zugriff auf die Daten
Um diese Rechte zu wahren, müssen Unternehmen und Organisationen Datenschutzmaßnahmen ergreifen, um die Daten einzelner Personen zu schützen. Auch das ist Vertrauenssache. Die Fähigkeit der Öffentlichkeit, Unternehmen personenbezogene Daten anzuvertrauen, ist wichtig. Es ist der Grund, warum Menschen das Produkt eines Unternehmens nutzen, ihre Informationen teilen und vieles mehr. Vertrauen ist eine wirklich große Verantwortung, die nicht auf die leichte Schulter genommen werden darf.
Schutz der Privatsphäre durch Datenanonymisierung

Organisationen nutzen viele verschiedene Maßnahmen, um die Privatsphäre ihrer Datensubjekte zu schützen, wie z. B. die Einbindung von Zugriffsberechtigungen, um sicherzustellen, dass nur die Personen, die auf diese Informationen zugreifen sollen, dies auch tun können. Eine weitere wichtige Strategie zur Wahrung der Privatsphäre ist die Datenanonymisierung.
Bei der Datenanonymisierung handelt es sich um den Prozess des Schutzes privater oder sensibler Daten von Personen durch Eliminierung personenbezogener Daten. Typischerweise umfasst die Datenanonymisierung das Ausblenden, Hashen oder Maskieren persönlicher Informationen, häufig durch die Verwendung von Codes fester Länge zur Darstellung von Datenspalten oder durch das Ausblenden von Daten mit geänderten Werten.
Datenanonymisierung wird in nahezu jeder Branche eingesetzt. Als BI-Experte werden Sie die Anonymisierung wahrscheinlich nicht persönlich durchführen, es ist jedoch hilfreich zu verstehen, welche Arten von Daten häufig anonymisiert werden, bevor Sie beginnen, damit zu arbeiten. Zu diesen Daten können gehören:
Telefonnummern
Namen
Kfz-Kennzeichen und Lizenznummern
Sozialversicherungsnummern
IP-Adressen
Krankenakten
E-mailadressen
Fotografien
Kontonummern
Stellen Sie sich eine Welt vor, in der wir alle Zugriff auf die Adressen, Kontonummern und andere identifizierbare Informationen des anderen haben. Das würde die Privatsphäre vieler Menschen verletzen und die Welt weniger sicher machen. Die Datenanonymisierung ist eine der Möglichkeiten, wie wir Daten privat und sicher halten können!
Die zentralen Thesen
Für jeden Fachmann, der mit Daten über tatsächliche Personen arbeitet, ist es wichtig, die Sicherheit und Privatsphäre dieser Personen zu berücksichtigen. Deshalb ist es so wichtig, die Bedeutung des Datenschutzes zu verstehen und zu verstehen, wie Daten, die PII enthalten, für die Analyse sicher gemacht werden können. Wir haben die Verantwortung, die Daten der Menschen und die darin enthaltenen personenbezogenen Daten zu schützen.
Wenn Sie mehr über Datenschutz und Ethik erfahren möchten, können Sie hier vorbeischauenden Abschnitt des Google Data Analytics-Zertifikatsprogramms zu Voreingenommenheit, Glaubwürdigkeit, Datenschutz, Ethik und Zugang.
Rechnen Sie mit Datenbeschränkungen
Wir leben in einer Welt, in der ständig Daten generiert werden. Es gibt so viele Informationen, aus denen man lernen kann. Aber wir leben auch in einer Welt, die sich ständig verändert, und oft weisen die Daten, auf die wir stoßen, bestimmte Einschränkungen auf, die wir berücksichtigen müssen, wenn wir Daten analysieren und daraus Erkenntnisse ziehen.

Faktoren der Datenverfügbarkeit
Zuvor haben Sie erfahren, wie wichtig die Datenverfügbarkeit ist, also der Grad oder Umfang, in dem aktuelle und relevante Informationen leicht zugänglich sind und genutzt werden können. Die Faktoren, die die Datenverfügbarkeit beeinflussen, sind:
Datenintegrität: Die Genauigkeit, Vollständigkeit, Konsistenz und Vertrauenswürdigkeit von Daten während ihres gesamten Lebenszyklus.
Datensichtbarkeit: Der Grad oder Umfang, in dem Informationen aus unterschiedlichen internen und externen Quellen identifiziert, überwacht und integriert werden können.
Aktualisierungshäufigkeit: Wie oft unterschiedliche Datenquellen mit neuen Informationen aktualisiert werden.
Änderung: Der Prozess der Änderung von Daten, entweder durch interne Prozesse oder externen Einfluss.
Als Nächstes werden Sie die Einschränkungen von Daten berücksichtigen, die sich auf die Verfügbarkeit auswirken können, und wie Sie als BI-Experte diese Einschränkungen antizipieren können.
Fehlende Daten
Wenn Sie über unvollständige oder nicht vorhandene Daten verfügen, verfügen Sie möglicherweise nicht über genügend Daten, um eine Schlussfolgerung zu ziehen. Oder Sie untersuchen möglicherweise sogar Daten zu einem völlig anderen Geschäftsproblem! Zu verstehen, welche Daten verfügbar sind, potenzielle andere Quellen zu identifizieren und Lücken zu schließen, ist ein wichtiger Teil des BI-Prozesses.
Falsch ausgerichtete Daten
Als BI-Experte nutzen Sie häufig Daten aus unterschiedlichen Quellen. Bei einigen davon handelt es sich möglicherweise um interne Quellen des Unternehmens, mit dem Sie zusammenarbeiten, es können sich aber auch externe Quellen darauf beziehen. Diese Quellen könnten Dinge auf völlig unterschiedliche Weise definieren und messen. In solchen Fällen führt eine frühzeitige Festlegung der Messmethoden zu einer umfassenden Standardisierung der Daten und sorgt so für mehr Zuverlässigkeit und Genauigkeit. Dadurch wird sichergestellt, dass Vergleiche zwischen Quellen aussagekräftig und aufschlussreich sind.
Schmutzige Daten
Unter schmutzigen Daten versteht man Daten, die Fehler enthalten. Schmutzige Daten können zu Fehlern in Ihrem System, ungenauen Berichten und schlechter Entscheidungsfindung führen. Die Implementierung von Prozessen zum Bereinigen von Daten durch Korrigieren oder Entfernen falscher, beschädigter, falsch formatierter, doppelter oder unvollständiger Daten innerhalb eines Datensatzes ist eine Möglichkeit, sich auf diese Einschränkung vorzubereiten.
Abschluss
Als BI-Experte müssen Sie verstehen, dass die Daten, mit denen Sie arbeiten, manchmal Einschränkungen unterliegen. Dies kann bedeuten, dass es nicht in einen bestimmten Zeitraum passt, nur für bestimmte Situationen gilt oder dass es schwierig ist, die benötigten Daten zu identifizieren. Wenn Sie in der Lage sind, diese Probleme vorherzusehen und sie bei der Entwicklung von Tools und Systemen für Ihr Unternehmen zu berücksichtigen, können Sie sicherstellen, dass diese Einschränkungen Ihre Stakeholder nicht davon abhalten, die Daten zu erhalten, die sie benötigen, um gute Entscheidungen zu treffen und den Projekterfolg sicherzustellen!
Fallstudie: USDM – Auswahl wichtiger Projektkennzahlen
In diesem Teil des Kurses haben Sie sich darauf konzentriert, wie Business-Intelligence-Experten effektive Kennzahlen für ein Projekt ermitteln. Ein wichtiger Teil dieses Prozesses besteht darin, mit den Stakeholdern zusammenzuarbeiten, um ihren Datenbedarf zu verstehen und herauszufinden, wie diese Interessen mit den Daten gemessen und dargestellt werden können. In dieser Fallstudie haben Sie die Möglichkeit, anhand eines Beispiels zu sehen, wie das BI-Team arbeitetUSDMarbeitete mit Stakeholdern zusammen, um Metriken zu entwickeln.
Firmenhintergrund
USDM mit Hauptsitz in Santa Barbara, Kalifornien, arbeitet mit Life-Science-Unternehmen aus einer Vielzahl von Branchen zusammen, darunter Biotechnologie, Pharmazie, Medizintechnik und Klinik. USDM hilft seinen Kunden, von großen Unternehmen bis hin zu kleinen Unternehmen, sicherzustellen, dass ihre Datenbanksysteme den Industriestandards und -vorschriften entsprechen und effektiv arbeiten, um ihre Anforderungen zu erfüllen. Die Vision von USDM besteht darin, der Welt Life-Science- und Gesundheitslösungen besser und schneller zugänglich zu machen – beginnend mit den eigenen Unternehmenswerten: Kundenzufriedenheit, Verantwortlichkeit, Integrität, Respekt, Zusammenarbeit und Innovation.

Die Herausforderung
In dieser Fallstudie werden Sie ein Beispiel für die Arbeit von USDM mit einem seiner Kunden untersuchen. Der Auftraggeber dieses Projekts erforscht und entwickelt Antikörpertherapien für Krebspatienten. Der Kunde benötigt Analysen, die die Wirksamkeit und Effizienz seiner Produkte messen. Da der Kunde jedoch über die vorhandene Datenbank verfügt, muss er auf viele Systeme zugreifen, darunter Anlagendaten, Lizenzinformationen sowie Vertriebs- und Marketingdaten, um die benötigten Berichtstypen zu erhalten. Alle diese Daten sind an verschiedenen Orten vorhanden und daher schafft die Entwicklung von Analyseberichten Probleme für die Stakeholder des Kunden. Außerdem wird es schwieriger, wichtige Kennzahlen zu vergleichen, da so viele KPIs an einem Ort zusammengeführt werden müssen.
Um besser zu verstehen, wie effektiv sein Produkt ist und welche Nachfrage es prognostiziert, bat der Kunde USDM um Hilfe bei der Entwicklung eines Datenspeichersystems, das seinen spezifischen Anforderungen gerecht werden könnte. Sie brauchten ein System, das die von ihrem Team benötigten Daten zusammenführt, Branchenvorschriften befolgt und es ihnen ermöglicht, auf einfache Weise Berichte auf der Grundlage wichtiger Kennzahlen zu erstellen, die zur Messung der Produkteffektivität und Markttrends verwendet werden können. Ein wesentlicher Teil dieser Initiative begann mit den Grundlagen: Was waren die tatsächlichen Schlüsselkennzahlen für das Team des Kunden und aus welchen Datensystemen stammten sie?
Die Vorgehensweise
Um herauszufinden, welche Kennzahlen für die Geschäftsanforderungen des Kunden am wichtigsten waren, musste das USDM-Team den Input verschiedener Personen aus dem gesamten Unternehmen einholen. Sie mussten beispielsweise wissen, welche Diagramme die Vertriebs- und Marketingteams, die diese Daten für ihre Berichte verwendeten, benötigten, wie ihre bestehenden Prozesse aussahen und wie diese Anforderungen im neuen System berücksichtigt werden konnten. Sie mussten aber auch wissen, welche Daten das Produktentwicklungsteam zur Messung der Wirksamkeit verwendete.

USDM arbeitete eng mit verschiedenen Teams zusammen, um zu ermitteln, welche Diagramme sie für Berichte benötigten, wie sie derzeit auf das Datenbanksystem zugreifen und es nutzen und was sie mit dem neuen System erreichen wollten. Als Ergebnis konnte das Team eine Auswahl wichtiger Kennzahlen ermitteln, die die Geschäftsanforderungen seines Kunden widerspiegelten. Zu diesen Kennzahlen gehörten:
Umsatzentwicklung
Produktleistung
Versicherungsansprüche
Informationen für Ärzte
Anlagendaten
Um eine Business-Intelligence-Lösung umzusetzen, muss sowohl eine geschäftliche Interaktion mit Stakeholdern als auch eine technische Interaktion mit den Architekten der Systeme anderer Teams stattfinden. Sobald diese Kennzahlen vom Kunden identifiziert wurden, arbeitete das USDM-Team mit anderen Mitgliedern des Kundenteams zusammen, um mit der Entwicklung einer neuen Lösung zu beginnen, die diese Messungen erfassen könnte.
Aber fast jedes Projekt bringt unerwartete Herausforderungen mit sich; Das Datenbanktool, das das Team zur Entwicklung des neuen Systems verwendete, verfügte nicht über alle Funktionen, die das Team zur Erfassung seiner unverzichtbaren Kennzahlen benötigte. In diesem Fall arbeitete das USDM-Team mit der Führung zusammen, um eine Liste mit Anfragen des Tool-Anbieters zu erstellen, der in der Lage war, auf die individuellen Bedürfnisse seines Teams einzugehen.
Die Ergebnisse
Am Ende des Projekts entwickelte das USDM BI-Team ein Datenspeichersystem, das alle vom Team benötigten Daten aus verschiedenen Quellen konsolidierte. Das System erfasste die wichtigsten Kennzahlen, die der Kunde benötigte, um die Wirksamkeit seines Produkts zu verstehen, die Verkaufsnachfrage vorherzusagen und Marketingstrategien zu bewerten. Die mit diesem Datenspeichersystem erstellten Reporting-Dashboards enthielten alles, was die Stakeholder benötigten. Durch die Konsolidierung aller KPIs an einem Ort könnte das System schnellere Erkenntnisse liefern, dem Kunden Zeit sparen und die Effizienz steigern, ohne dass Berichte von jedem einzelnen System ausgeführt werden müssen. Die Lösung war automatisierter und effizienter – und was noch wichtiger ist: Sie wurde speziell unter Berücksichtigung der nützlichsten Kennzahlen des Teams entwickelt.
Abschluss
Die Zusammenarbeit mit Benutzern und Stakeholdern zur frühzeitigen Auswahl von Metriken kann dabei helfen, die langfristige Ausrichtung eines Projekts, die spezifischen Bedürfnisse der Stakeholder und die Gestaltung von BI-Tools zu bestimmen, die den individuellen Geschäftsanforderungen am besten gerecht werden. Als BI-Experte wird ein wichtiger Teil Ihrer Rolle darin bestehen, wichtige Kennzahlen zu berücksichtigen und die von Ihnen erstellten Tools und Systeme so anzupassen, dass diese Messwerte für die Berichterstellung effizient erfasst werden.
Überprüfen Sie den Inhalt des Google Data Analytics-Zertifikats auf den Kontext
Kontext ist der Zustand, in dem etwas existiert oder geschieht. Der Kontext ist bei der Datenanalyse wichtig, da er Ihnen hilft, riesige Mengen unorganisierter Daten zu sichten und sie in etwas Sinnvolles umzuwandeln. Tatsache ist, dass Daten wenig Wert haben, wenn sie nicht mit dem Kontext verknüpft sind.

Wenn wir den Kontext hinter den Daten verstehen, können wir sie in jeder Phase des Datenanalyseprozesses aussagekräftiger gestalten. Beispielsweise können Sie vielleicht ein paar Vermutungen darüber anstellen, was Sie in der folgenden Tabelle sehen, ohne mehr Kontext könnten Sie sich aber nicht sicher sein.
2010 | 28000 |
2005 | 18000 |
2000 | 23000 |
1995 | 10000 |
Wenn andererseits die erste Spalte so beschriftet wäre, dass sie die Jahre darstellt, in denen eine Umfrage durchgeführt wurde, und die zweite Spalte die Anzahl der Personen anzeigt, die auf diese Umfrage geantwortet haben, würde die Tabelle viel mehr Sinn ergeben. Gehen Sie noch einen Schritt weiter und Sie werden vielleicht feststellen, dass die Umfrage alle fünf Jahre durchgeführt wird. Dieser zusätzliche Kontext hilft Ihnen zu verstehen, warum die Tabelle Lücken von fünf Jahren aufweist.
Jahre (Erhebung alle 5 Jahre) | Befragte |
|---|---|
2010 | 28000 |
2005 | 18000 |
2000 | 23000 |
1995 | 10000 |
Der Kontext kann Rohdaten in aussagekräftige Informationen verwandeln. Für Datenanalysten ist es sehr wichtig, ihre Daten zu kontextualisieren. Das bedeutet, den Daten eine Perspektive zu geben, indem man sie definiert. Dazu müssen Sie Folgendes identifizieren:
Wer: Die Person oder Organisation, die die Datenerfassung erstellt, gesammelt und/oder finanziert hat
Was: Die Dinge auf der Welt, auf die Daten einen Einfluss haben könnten
Wo: Der Ursprung der Daten
Wann: Der Zeitpunkt, zu dem die Daten erstellt oder erfasst wurden
Warum: Die Motivation hinter der Kreation oder Sammlung
Wie: Die zum Erstellen oder Sammeln verwendete Methode

Bei jedem Schritt Ihres Analyseprozesses ist es wichtig, den Kontext zu verstehen und einzubeziehen, daher ist es eine gute Idee, sich schon früh in Ihrer Karriere damit vertraut zu machen. Wenn Sie beispielsweise Daten sammeln, sollten Sie auch Fragen zum Kontext stellen, um sicherzustellen, dass Sie das Geschäft und den Geschäftsprozess verstehen. Bei der Organisation ist der Kontext wichtig für Ihre Namenskonventionen, für die Art und Weise, wie Sie Beziehungen zwischen Variablen darstellen und für das, was Sie beibehalten oder weglassen. Und schließlich ist es bei Ihrer Präsentation wichtig, kontextbezogene Informationen einzubeziehen, damit Ihre Stakeholder Ihre Analyse verstehen.
Entdecken Sie Projektszenarien am Ende des Kurses 1
Wenn Sie mit strukturiertem Denken an ein Projekt herangehen, werden Sie häufig feststellen, dass bestimmte Schritte in einer bestimmten Reihenfolge ausgeführt werden müssen. Die Abschlussprojekte im Google Business Intelligence-Zertifikat wurden unter diesem Gesichtspunkt konzipiert. Die in jedem Kurs vorgestellten Herausforderungen stellen einen einzelnen Meilenstein innerhalb eines gesamten Projekts dar, basierend auf den in diesem Kurs erlernten Fähigkeiten und Konzepten.

Das Zertifikatsprogramm ermöglicht es Ihnen, aus verschiedenen Arbeitsplatzszenarien zu wählen, um die Abschlussprojekte abzuschließen: das Fahrradverleihunternehmen Cyclistic oder Google Fiber. Jedes Szenario bietet Ihnen die Möglichkeit, Ihre Fähigkeiten zu verfeinern und Artefakte zu erstellen, die Sie in einem Online-Portfolio auf dem Arbeitsmarkt teilen können.
Unabhängig davon, für welches Szenario Sie sich entscheiden, erlernen Sie ähnliche Fähigkeiten, müssen jedoch für jeden Kurs mindestens ein Abschlussprojekt abschließen, um Ihr Google Business Intelligence-Zertifikat zu erhalten. Um ein zusammenhängendes Erlebnis zu gewährleisten, wird empfohlen, für jedes Abschlussprojekt das gleiche Szenario zu wählen. Wenn Sie sich zum Beispiel für das Radfahr-Szenario für Kurs 1 entscheiden, empfehlen wir Ihnen, dasselbe Szenario auch für Kurs 2 und 3 zu absolvieren. Wenn Sie jedoch an mehr als einem Arbeitsplatzszenario interessiert sind oder sich eine größere Herausforderung wünschen, können Sie gerne mehr als ein Abschlussprojekt durchführen. Durch den Abschluss mehrerer Projekte erhalten Sie zusätzliche Übungen und Beispiele, die Sie potenziellen Arbeitgebern mitteilen können.
Projektszenarien am Ende des Kurses 1
Fahrrad-Sharing

Hintergrund:
In diesem fiktiven Arbeitsplatzszenario hat sich das imaginäre Unternehmen Cyclistic mit der Stadt New York zusammengetan, um gemeinsam genutzte Fahrräder bereitzustellen. Derzeit gibt es in ganz Manhattan und den angrenzenden Bezirken Fahrradstationen. Kunden können an diesen Standorten Fahrräder mieten, um bequem zwischen den Stationen hin- und herzufahren.
Szenario:
Sie sind ein neu eingestellter BI-Experte bei Cyclistic. Das Kundenwachstumsteam des Unternehmens erstellt einen Geschäftsplan für das nächste Jahr. Sie möchten verstehen, wie ihre Kunden ihre Fahrräder nutzen. Ihre oberste Priorität besteht darin, die Kundennachfrage an verschiedenen Bahnhofsstandorten zu ermitteln.
Herausforderung für Kurs 1:
Sammeln Sie Informationen aus Notizen, die Sie bei der letzten Vorstandssitzung von Cyclistic gemacht haben
Identifizieren Sie relevante Stakeholder für jede Aufgabe
Organisieren Sie Aufgaben in Meilensteine
Vervollständigen Sie Projektplanungsdokumente, um sie mit den Interessengruppen abzustimmen
Hinweis: Die Geschichte sowie alle dargestellten Namen, Charaktere und Vorfälle sind frei erfunden. Eine Identifizierung mit tatsächlichen Personen (lebend oder verstorben) ist nicht beabsichtigt oder sollte abgeleitet werden. Die in diesem Projekt geteilten Daten wurden für pädagogische Zwecke erstellt.
Google Fiber

Hintergrund:
Google Fiber versorgt Menschen und Unternehmen mit Glasfaser-Internet. Derzeit beantwortet das Kundendienstteam in seinen Callcentern Anrufe von Kunden in seinen etablierten Servicegebieten. In diesem fiktiven Szenario möchte das Team Trends bei wiederholten Anrufen untersuchen, um die Anzahl der Anrufe von Kunden zu reduzieren, damit ein Problem gelöst werden kann.
Szenario:
Sie führen derzeit ein Vorstellungsgespräch für eine BI-Stelle im Callcenter-Team von Google Fibre. Im Rahmen des Interviewprozesses werden Sie gebeten, ein Dashboard-Tool zu entwickeln, das es ihnen ermöglicht, Trends bei wiederholten Anrufen zu erkunden. Das Team muss verstehen, wie oft Kunden nach ihrer ersten Anfrage den Kundendienst anrufen. Dies wird der Führung helfen, zu verstehen, wie effektiv das Team Kundenfragen beim ersten Mal beantworten kann.
Herausforderung für Kurs 1:
Sammeln Sie Informationen aus Notizen, die Sie während Ihres Interviews mit Google Fibre gemacht haben
Identifizieren Sie relevante Stakeholder für jede Aufgabe
Organisieren Sie Aufgaben in Meilensteine
Vervollständigen Sie Projektplanungsdokumente, um sie mit den Interessengruppen abzustimmen
Die zentralen Thesen
In Kurs 1, Grundlagen der Business Intelligence, haben Sie die Welt der BI-Experten erkundet und erfahren, wie BI zur Vision eines Unternehmens beiträgt.
Fähigkeiten in Kurs 1:
Üben Sie effektive Kommunikation
Verstehen Sie die funktionsübergreifende Teamdynamik
Führen Sie ein effektives Projektmanagement durch
Teilen Sie Erkenntnisse und Ideen mit Stakeholdern
Ergebnisse des Abschlussprojekts von Kurs 1:
Drei BI-Projektplanungsdokumente
Sie haben die Möglichkeit, die Szenarien detaillierter zu erkunden, indem Sie die Übersichtslesungen zu den Arbeitsplatzszenarien lesen. Nachdem Sie die Übersichten gelesen haben, wählen Sie aus, welches Arbeitsplatzszenario für Sie am interessantesten ist!
Überblick über das Arbeitsplatzszenario von Kurs 1: Radfahrer
Erfahren Sie mehr über das Arbeitsplatzszenario
Das Abschlussprojekt dient dazu, dass Sie Ihre Fähigkeiten in einem Arbeitsplatzszenario üben und anwenden. Egal für welches Szenario Sie sich entscheiden, Sie diskutieren und kommunizieren über Datenanalysethemen mit Kollegen, internen Teammitgliedern und externen Kunden. Sie müssen nur eines der Szenarios befolgen, um das Abschlussprojekt abzuschließen. Lesen Sie weiter, um mehr über das fiktive Fahrradverleihunternehmen Cyclistic zu erfahren. Wenn Sie stattdessen das Google Fibre-Projekt erkunden möchten, gehen Sie zuDie Lektüre, die einen Überblick über dieses Arbeitsplatzszenario bietet. Zur Erinnerung: Sie müssen nur eines dieser Szenarios durcharbeiten, um das Kursabschlussprojekt abzuschließen. Bei Bedarf können Sie aber auch mehrere abschließen.

Willkommen bei Cyclistic!
Herzlichen Glückwunsch zu Ihrem neuen Job im Business-Intelligence-Team von Cyclistic, einem fiktiven Bike-Sharing-Unternehmen in New York City. Um Ihrem Team sowohl BI-Geschäftswert als auch organisatorische Datenreife zu bieten, nutzen Sie Ihr Wissen über die BI-Phasen: Erfassung, Analyse und Überwachung. Wenn Sie fertig sind, verfügen Sie über ein Abschlussprojekt, das potenziellen Arbeitgebern Ihr Wissen und Ihre Fähigkeiten demonstriert.
Ihre Besprechungsnotizen
Sie haben kürzlich an einem Treffen mit wichtigen Interessenvertretern teilgenommen, um Einzelheiten zu diesem BI-Projekt zu erfahren. Bei den folgenden Angaben handelt es sich um Ihre Notizen aus der Besprechung. Verwenden Sie die darin enthaltenen Informationen, um das Stakeholder-Anforderungsdokument, das Projektanforderungsdokument und das Planungsdokument auszufüllen. Weitere Hinweise finden Sie imvorherige Lektüre der Dokumente und das Selbstüberprüfung, bei der sie abgeschlossen wurden.
Hintergrund des Projekts:
Primärer Datensatz:NYC Citi-Fahrradausflüge
Sekundärer Datensatz:US-Grenzen des Census Bureau
Cyclistic hat sich mit der Stadt New York zusammengetan, um gemeinsam genutzte Fahrräder anzubieten. Derzeit gibt es in ganz Manhattan und den angrenzenden Bezirken Fahrradstationen. Kunden können an diesen Standorten Fahrräder mieten, um bequem zwischen den Stationen zu reisen.
Das Customer Growth Team von Cyclistic erstellt einen Geschäftsplan für das nächste Jahr. Das Team möchte verstehen, wie seine Kunden ihre Fahrräder nutzen; Ihre oberste Priorität besteht darin, die Kundennachfrage an verschiedenen Bahnhofsstandorten zu ermitteln.
Cyclistic hat Datenpunkte für jede Fahrt seiner Kunden erfasst, darunter:
Startzeit und -ort der Reise (Stationsnummer sowie Breiten- und Längengrad)
Uhrzeit und Ort des Reiseendes (Stationsnummer sowie Breiten- und Längengrad)
Die Identifikationsnummer des gemieteten Fahrrads
Die Art des Kunden (entweder ein Einmalkunde oder ein Abonnent)
Der Datensatz umfasst Millionen von Fahrten, daher möchte das Team ein Dashboard, das wichtige Erkenntnisse zusammenfasst. Geschäftspläne, die auf Kundenerkenntnissen basieren, sind erfolgreicher als Pläne, die nur auf internen Beobachtungen der Mitarbeiter basieren. Die Zusammenfassung muss wichtige Datenpunkte enthalten, die zusammengefasst und aggregiert werden, damit das Führungsteam eine klare Vorstellung davon erhält, wie Kunden Cyclistic nutzen.
Stakeholder:
Sara Romero, Vizepräsidentin, Marketing
Ernest Cox, Vizepräsident, Produktentwicklung
Jamal Harris, Direktor, Kundendaten
Nina Locklear, Direktorin, Beschaffung
Teammitglieder:
Adhira Patel, API-Strategin
Megan Pirato, Data Warehousing-Spezialistin
Rick Andersson, Manager, Data Governance
Tessa Blackwell, Datenanalystin
Brianne Sand, Direktorin, IT
Shareefah Hakimi, Projektmanagerin
*Hauptkontakte sind Adhira, Megan, Rick und Tessa.
Per Sara: Das Dashboard muss zugänglich sein, mit Großdruck- und Text-to-Speech-Alternativen.
Projektgenehmigungen und Abhängigkeiten:
Die Datensätze umfassen Kundendaten (Benutzerdaten), die Jamal genehmigen muss. Außerdem muss das Projekt möglicherweise von den Teams genehmigt werden, die über bestimmte Produktdaten verfügen, einschließlich der Dauer der Radtour und der Fahrradidentifikationsnummern. Daher muss ich sicherstellen, dass die Beteiligten Datenzugriff auf alle Datensätze haben.
Projektziel: Den Kundenstamm von Cyclistic vergrößern
Details von Frau Romero:
Verstehen Sie, was Kunden wollen, was ein erfolgreiches Produkt ausmacht und wie neue Stationen die Nachfrage in verschiedenen geografischen Gebieten lindern können.
Verstehen Sie, wie die aktuelle Fahrradlinie verwendet wird.
Wie können wir Erkenntnisse über die Kundennutzung nutzen, um das Wachstum neuer Sender zu informieren?
Das Kundenwachstumsteam möchte verstehen, wie verschiedene Benutzer (Abonnenten und Nicht-Abonnenten) unsere Fahrräder nutzen. Wir möchten eine große Gruppe von Benutzern untersuchen, um eine faire Darstellung der Benutzer über Standorte hinweg und mit niedrigem bis hohem Aktivitätsniveau zu erhalten.
Bedenken Sie, dass Benutzer Cyclistic bei schlechtem Wetter möglicherweise weniger nutzen. Dies sollte im Dashboard sichtbar sein.
Die Ergebnisse und Kennzahlen:
Eine Tabellen- oder Kartenvisualisierung, die die Standorte der Start- und Endstationen erkundet, aggregiert nach Standort. Ich kann jede Ortskennung verwenden, z. B. Bahnhof, Postleitzahl, Nachbarschaft und/oder Bezirk. Hier sollte die Anzahl der Fahrten an den Startorten angezeigt werden.
Tipp: Sie können entweder eine Tabelle oder eine Karte anzeigen. Weitere Informationen zum Erstellen von Karten in Tableau finden Sie unter Erstellen Sie mit der Tableau-Hilfe einen einfachen Kartenführer. Für eine Tabelle können Sie nur Startorte oder eine Kombination aus Start- und Endorten angeben.
Eine Visualisierung, die basierend auf den Gesamtfahrminuten zeigt, welche Zielorte (Endorte) beliebt sind.
Tipp: Konzentrieren Sie sich auf die Hauptmonate.
Eine Visualisierung, die sich auf Trends aus dem Sommer 2015 konzentriert.
Eine Visualisierung, die das prozentuale Wachstum der Anzahl der Fahrten im Jahresvergleich zeigt.
Sammeln Sie Erkenntnisse über Staus an Bahnhöfen.
Tipp: Berechnen Sie für jeden Tag per Tabellenkalkulation das Netto aus Anfangs- und Endfahrten pro Station. Dies gibt einen Näherungswert dafür, ob mehr Fahrräder an einer Station ein- oder ausgehen.
Sammeln Sie Erkenntnisse über die Anzahl der Fahrten an allen Start- und Zielorten.
Sammeln Sie Erkenntnisse über die Spitzenauslastung nach Tageszeit, Jahreszeit und den Auswirkungen des Wetters.
*Dashboard muss in 6 Wochen erstellt werden!
Erfolg messen:
Analysieren Sie Daten, die sich über mindestens ein Jahr erstrecken, um zu sehen, wie sich Saisonalität auf die Nutzung auswirkt. Durch die Untersuchung von Daten, die sich über mehrere Monate erstrecken, werden Spitzen und Täler der Nutzung erfasst. Bewerten Sie jede Fahrt anhand der Anzahl der Fahrten pro Startort und pro Tag/Monat/Jahr, um Trends zu verstehen. Nutzen Kunden beispielsweise Cyclistic weniger, wenn es regnet? Oder bleibt die Bikeshare-Nachfrage konstant? Unterscheidet sich dies je nach Standort und Benutzertyp (Abonnenten vs. Nicht-Abonnenten)? Nutzen Sie diese Ergebnisse, um mehr darüber herauszufinden, welche Auswirkungen die Kundennachfrage hat.
Weitere Überlegungen:
Der Datensatz umfasst Breiten- und Längengrade von Stationen, identifiziert jedoch keine weiteren geografischen Aggregationsdetails wie Postleitzahl, Nachbarschaftsname oder Bezirk. Das Team wird eine separate Datenbank mit diesen Daten bereitstellen.
In den bereitgestellten Wetterdaten ist nicht enthalten, wann der Niederschlag eingetreten ist. Es ist möglich, dass es an manchen Tagen außerhalb der Hauptverkehrszeiten regnete. Für die Zwecke dieses Dashboards sollte ich jedoch davon ausgehen, dass jede Niederschlagsmenge, die am Tag der Reise aufgetreten ist, einen Einfluss haben könnte.
Wenn an einer Station keine Fahrräder verfügbar sind, ist es nicht möglich, Radtouren an einem Ort zu starten. Daher müssen wir möglicherweise andere Faktoren für die Nachfrage berücksichtigen.
Schließlich dürfen die Daten keine personenbezogenen Daten (Name, E-Mail, Telefonnummer, Adresse) enthalten. Persönliche Daten sind für dieses Projekt nicht erforderlich. Anonymisieren Sie Benutzer, um Voreingenommenheit zu vermeiden und ihre Privatsphäre zu schützen.
Personen mit Dashboard-Anzeigeberechtigungen:
Adhira, Brianne, Ernest, Jamal, Megan, Nina, Rick, Shareefah, Sara, Tessa
Ausrollen:
Woche 1: Datensatz zugewiesen. Ursprüngliches Design für Felder und BikeIDs, validiert, um den Anforderungen zu entsprechen.
Wochen 2–3: SQL- und ETL-Entwicklung
Woche 3–4: SQL abschließen. Dashboard-Design. Überprüfung des ersten Entwurfs mit Kollegen.
Wochen 5–6: Dashboard-Entwicklung und -Tests
Fragen:
Wie wurden Fahrräder von unseren Kunden genutzt?
Wie können wir Erkenntnisse aus den durch Reisedaten generierten Daten nutzen?
Nächste Schritte
Nehmen Sie sich beim Vervollständigen der wichtigsten BI-Dokumente mithilfe dieser Notizen die Zeit, Folgendes zu bedenken:
So organisieren Sie die verschiedenen Punkte und Schritte
So gruppieren Sie ähnliche Themen
Ob die Informationen für das Projekt relevant sind
Ob die Metriken effektiv sind oder nicht
Bedenken Sie schließlich, dass dieses Projekt nicht benotet wird. Ein überzeugendes Projekt ermöglicht es Ihnen jedoch, potenziellen Arbeitgebern grundlegende BI-Kenntnisse zu demonstrieren. Nachdem Sie die Dokumente ausgefüllt haben, vergleichen Sie sie unbedingt mit den Beispielleistungen. Sie können auch die Schritte aufzeichnen, die Sie zum Abschluss jeder Phase dieses Projekts unternommen haben, damit Sie die Zusammenfassung vervollständigen können. Dies ist wichtig, wenn Sie in den folgenden Kursen weiter an dem Projekt arbeiten.
Überblick über Kurs 2

Hallo und willkommen bei „ The Path to Insights: Data Models and Pipelines“ , dem zweiten Kurs im Google Business Intelligence-Zertifikat. Du befindest dich auf einer spannenden Reise!
Am Ende dieses Kurses sind Sie in der Lage, Datenmodellierung und ETL-Prozesse zu nutzen, um Daten aus Quellsystemen zu extrahieren, sie in Formate umzuwandeln, die eine bessere Analyse ermöglichen und Geschäftsprozesse und -ziele vorantreiben.
Kursbeschreibung
Das Google Business Intelligence-Zertifikat besteht aus drei Kursen. Der Weg zu Erkenntnissen: Datenmodelle und Pipelines ist der zweite Kurs.

Grundlagen der Business Intelligence — Entdecken Sie die Rolle von BI-Experten innerhalb einer Organisation und die Karrierewege, die sie normalerweise einschlagen. Entdecken Sie anschließend die wichtigsten BI-Praktiken und -Tools und erfahren Sie, wie BI-Experten sie nutzen, um einen positiven Einfluss auf Unternehmen zu erzielen.
Der Weg zu Erkenntnissen: Datenmodelle und Pipelines– ( aktueller Kurs ) Erkunden Sie Datenmodellierung und ETL-Prozesse zum Extrahieren von Daten aus Quellsystemen, deren Umwandlung in Formate, die eine bessere Analyse ermöglichen, und zur Förderung von Geschäftsprozessen und -zielen.
Entscheidungen, Entscheidungen: Dashboards und Berichte— Wenden Sie Ihr Wissen über BI und Datenmodellierung an, um dynamische Dashboards zu erstellen, die wichtige Leistungsindikatoren verfolgen, um den Anforderungen der Stakeholder gerecht zu werden.
Inhalt von Kurs 2
Jeder Kurs dieses Zertifikatsprogramms ist in Module unterteilt. Sie können Kurse in Ihrem eigenen Tempo absolvieren, die Modulaufschlüsselung soll Ihnen jedoch dabei helfen, das gesamte Google Business Intelligence-Zertifikat in zwei bis vier Monaten abzuschließen.
Was kommt? Hier finden Sie einen kurzen Überblick über die Fähigkeiten, die Sie in den einzelnen Modulen dieses Kurses erlernen.

Modul 1: Datenmodelle und Pipelines
Zu Beginn dieses Kurses erkunden Sie die Grundlagen der Datenmodellierung sowie gängige Schemata und wichtige Datenbankelemente. Sie werden auch darüber nachdenken, wie Geschäftsanforderungen die Art von Datenbanksystemen bestimmen, die ein BI-Experte implementieren könnte. Anschließend lernen Sie mehr über Pipelines und ETL-Prozesse, die Tools, die Daten durch das System bewegen und sicherstellen, dass sie zugänglich und nützlich sind. Nebenbei erweitern Sie Ihre BI-Toolbox um viele weitere wichtige Tools.
Modul 2: Dynamisches Datenbankdesign
In diesem Teil des Kurses erfahren Sie mehr über Datenbanksysteme, einschließlich Data Marts, Data Lakes, Data Warehouses und ETL-Prozesse. Sie untersuchen außerdem die fünf Faktoren der Datenbankleistung: Arbeitslast, Durchsatz, Ressourcen, Optimierung und Konflikt. Abschließend beginnen Sie darüber nachzudenken, wie Sie effiziente Abfragen entwerfen können, die Ihr System optimal nutzen.
Modul 3: ETL-Prozesse optimieren
In diesem Abschnitt des Kurses erfahren Sie mehr über ETL-Qualitätstests, Datenschemavalidierung, Überprüfung von Geschäftsregeln und allgemeine Leistungstests. Sie befassen sich außerdem mit der Datenintegrität und erfahren, wie integrierte Qualitätsprüfungen Ihnen dabei helfen, Datenfehler aufzudecken. Abschließend erfahren Sie, wie Sie Geschäftsregeln überprüfen und allgemeine Leistungstests durchführen, um sicherzustellen, dass Pipelines die beabsichtigten Geschäftsanforderungen erfüllen.
Modul 4: Abschlussprojekt von Kurs 2
Im zweiten Abschlussprojekt erstellen Sie einen Pipeline-Prozess, um die erforderlichen Daten an eine Zieltabelle zu liefern. Anschließend verwenden Sie diese Zieltabelle, um Berichte basierend auf den Projektanforderungen zu entwickeln. Nachdem Sie die Pipeline erstellt haben, stellen Sie außerdem sicher, dass sie ordnungsgemäß funktioniert und dass integrierte Abwehrmaßnahmen gegen Datenqualitätsprobleme vorhanden sind.
Was zu erwarten ist
Jeder Kurs bietet viele Arten von Lernmöglichkeiten:
Von Google-Lehrern geleitete Videos vermitteln neue Konzepte, führen in die Verwendung relevanter Tools ein, bieten Karriereunterstützung und liefern inspirierende persönliche Geschichten.
Die Lesungen bauen auf den in den Videos behandelten Themen auf, stellen verwandte Konzepte vor, teilen nützliche Ressourcen und beschreiben Fallstudien.
Diskussionsaufforderungen erläutern Kursthemen zum besseren Verständnis und ermöglichen es Ihnen, mit anderen Lernenden im zu chatten und Ideen auszutauschenDiskussionsforen.
Durch Selbstüberprüfungsaktivitäten und Labore können Sie die Anwendung der erlernten Fertigkeiten praktisch üben und Ihre eigene Arbeit durch den Vergleich mit einem abgeschlossenen Beispiel bewerten.
Interaktive Plug-ins regen zum Üben konkreter Aufgaben an und unterstützen Sie bei der Integration des im Kurs erworbenen Wissens.
In-Video-Tests helfen Ihnen, Ihr Verständnis zu überprüfen, während Sie jedes Video durchgehen.
Mit Übungsquiz können Sie Ihr Verständnis wichtiger Konzepte überprüfen und wertvolles Feedback geben.
Benotete Tests zeigen Ihr Verständnis der Hauptkonzepte eines Kurses. Um ein Zertifikat zu erhalten, müssen Sie in jedem benoteten Quiz mindestens 80 % erreichen. Sie können ein benotetes Quiz auch mehrmals absolvieren, um eine bestandene Punktzahl zu erreichen.
Tipps für den Erfolg
Es wird dringend empfohlen, dass Sie die Elemente in jeder Lektion in der Reihenfolge durchgehen, in der sie erscheinen, da neue Informationen und Konzepte auf Vorkenntnissen aufbauen.
Nehmen Sie an allen Lernmöglichkeiten teil, um so viel Wissen und Erfahrung wie möglich zu sammeln.
Wenn etwas verwirrend ist, zögern Sie nicht, ein Video noch einmal abzuspielen, eine Lektüre zu wiederholen oder eine Selbstüberprüfungsaktivität zu wiederholen.
Nutzen Sie die zusätzlichen Ressourcen, auf die in diesem Kurs verwiesen wird. Sie sollen Ihr Lernen unterstützen. Alle diese Ressourcen finden Sie imRessourcenTab.
Wenn Sie in diesem Kurs auf nützliche Links stoßen, setzen Sie ein Lesezeichen darauf, damit Sie später auf die Informationen zurückgreifen können, um sie zu studieren oder zu überprüfen.
Verstehen und befolgen Sie dieCoursera-Verhaltenskodexum sicherzustellen, dass die Lerngemeinschaft für alle Mitglieder ein einladender, freundlicher und unterstützender Ort bleibt.
Entwerfen Sie effiziente Datenbanksysteme mit Schemata
Sie haben gelernt, wie Business-Intelligence-Experten Datenmodelle und Schemata verwenden, um Datenbanken zu organisieren und zu optimieren. Zur Erinnerung: Ein Schema ist eine Möglichkeit, die Art und Weise zu beschreiben, wie etwas organisiert ist. Stellen Sie sich Datenschemata wie Blaupausen für den Aufbau einer Datenbank vor. Dies ist sehr nützlich, wenn Sie einen neuen Datensatz erkunden oder eine relationale Datenbank entwerfen. Ein Datenbankschema stellt jede Art von Struktur dar, die rund um die Daten definiert ist. Auf der einfachsten Ebene gibt es an, welche Tabellen oder Beziehungen die Datenbank bilden, sowie die in jeder Tabelle enthaltenen Felder.
In dieser Lektüre werden gängige Schematypen erläutert, denen Sie bei der Arbeit begegnen können.
Arten von Schemata
Stern und Schneeflocke
Sie haben bereits etwas über die relationalen Modelle von Stern- und Schneeflockenschemata gelernt. Stern- und Schneeflockenschemata haben einige Gemeinsamkeiten, weisen aber auch einige Unterschiede auf. Obwohl beide Dimensionstabellen gemeinsam nutzen, sind die Dimensionstabellen in Snowflake-Schemas beispielsweise normalisiert. Dadurch werden Daten in zusätzliche Tabellen aufgeteilt, was die Schemata etwas komplexer macht.
Ein Sternschema ist ein Schema, das aus einer oder mehreren Faktentabellen besteht, die auf eine beliebige Anzahl von Dimensionstabellen verweisen. Wie der Name schon sagt, hat dieses Schema die Form eines Sterns. Diese Art von Schema ist ideal für die Bereitstellung umfangreicher Informationen und sorgt für eine effizientere Leseausgabe. Außerdem werden Attribute in Fakten und beschreibende Dimensionsattribute (Produkt-ID, Kundenname, Verkaufsdatum) klassifiziert.
Hier ist ein Beispiel für ein Sternschema:

In diesem Beispiel verwendet dieses Unternehmen ein Sternschema, um die Verkaufsinformationen in seinen Tabellen zu verfolgen. Das beinhaltet:
Kundeninformation
Produktinformation
Der Zeitpunkt, zu dem der Verkauf erfolgt
Mitarbeiterinformation
Alle Dimensionstabellen verweisen auf die Tabelle „sales_fact“ in der Mitte, was bestätigt, dass es sich um ein Sternschema handelt.
Ein Schneeflockenschema ist eine Erweiterung eines Sternschemas mit zusätzlichen Dimensionen und häufig auch Unterdimensionen. Diese Dimensionen und Unterdimensionen erzeugen ein Schneeflockenmuster. Wie Schneeflocken in der Natur kann ein Schneeflockenschema – und die Beziehungen darin – komplex sein. Snowflake-Schemas sind ein Organisationstyp, der für eine blitzschnelle Datenverarbeitung entwickelt wurde.
Unten finden Sie ein Beispiel für ein Schneeflockenschema:

Vielleicht möchte ein Datenexperte ein Schneeflockenschema entwerfen, das Informationen zu Sportlern/Vereinen enthält. Beginnen Sie in der Mitte mit der Faktentabelle, die Folgendes enthält:
PLAYER_ID
LEAGUE_ID
MATCH_TYPE
CLUB_ID
Diese Faktentabelle verzweigt sich in mehrere Dimensionstabellen und sogar Unterdimensionen. In den Dimensionstabellen werden zahlreiche Details aufgeführt, z. B. Statistiken zu Spielernationalspielern und Spielerclubs, Transferhistorie und mehr.
Flaches Modell
Bei abgeflachten Schemata handelt es sich um äußerst einfache Datenbanksysteme mit einer einzelnen Tabelle, in der jeder Datensatz durch eine einzelne Datenzeile dargestellt wird. Die Zeilen werden wie eine Spalte durch ein Trennzeichen getrennt, um die Trennung zwischen Datensätzen anzuzeigen. Flache Modelle sind nicht relational; Sie können keine Beziehungen zwischen Tabellen oder Datenelementen erfassen. Aus diesem Grund werden flache Modelle häufiger als potenzielle Quelle innerhalb eines Datensystems verwendet, um weniger komplexe Daten zu erfassen, die nicht aktualisiert werden müssen.
Hier ist eine flache Tabelle mit Läufern und Zeiten für einen 100-Meter-Lauf:

Diese Daten werden sich nicht ändern, da das Rennen bereits stattgefunden hat. Und da es so einfach ist, lohnt es sich nicht wirklich, es in eine komplexe relationale Datenbank zu integrieren, wenn ein einfaches flaches Modell ausreicht.
Als BI-Experte stoßen Sie möglicherweise auf flache Modelle in Datenquellen, die Sie in Ihre eigenen Systeme integrieren möchten. Wenn Sie überlegen, wie Sie die Daten am besten in Ihre Zieltabellen integrieren, ist es hilfreich zu wissen, dass es sich hierbei nicht bereits um relationale Modelle handelt.
Halbstrukturierte Schemata
Neben herkömmlichen relationalen Schemata gibt es auch halbstrukturierte Datenbankschemata, die über weitaus flexiblere Regeln verfügen, aber dennoch eine gewisse Organisation beibehalten. Da diese Datenbanken weniger strenge Organisationsregeln haben, sind sie äußerst flexibel und auf den schnellen Zugriff auf Daten ausgelegt.
Es gibt vier gängige halbstrukturierte Schemata:
Dokumentschemata speichern Daten als Dokumente, ähnlich wie JSON-Dateien . Diese Dokumente speichern Paare von Feldern und Werten unterschiedlicher Datentypen.
Schlüsselwertschemata koppeln eine Zeichenfolge mit einer Beziehung zu den Daten, etwa einem Dateinamen oder einer URL, die dann als Schlüssel verwendet wird. Dieser Schlüssel ist mit den Daten verknüpft, die in einer einzigen Sammlung gespeichert werden. Benutzer fordern Daten direkt an, indem sie den Schlüssel verwenden, um sie abzurufen.
Breitspaltige Schemata verwenden flexible, skalierbare Tabellen. Jede Zeile enthält einen Schlüssel und zugehörige Spalten, die in einem breiten Format gespeichert sind.
Diagrammschemata speichern Datenelemente in Sammlungen, die als Knoten bezeichnet werden. Diese Knoten sind durch Kanten verbunden, die Informationen darüber speichern, wie die Knoten miteinander verbunden sind. Im Gegensatz zu relationalen Datenbanken ändern sich diese Beziehungen jedoch, wenn neue Daten in die Knoten eingegeben werden.
Abschluss
Als BI-Experte arbeiten Sie häufig mit Daten, die auf unterschiedliche Weise organisiert und gespeichert wurden. Verschiedene Datenbankmodelle und -schemata sind für unterschiedliche Zwecke nützlich, und wenn Sie das wissen, können Sie ein effizientes Datenbanksystem entwerfen!
Vier Schlüsselelemente von Datenbankschemata
Unabhängig davon, ob Sie ein neues Datenbankmodell erstellen oder ein bereits vorhandenes System erkunden, ist es wichtig sicherzustellen, dass alle Elemente im Schema vorhanden sind. Mit dem Datenbankschema können Sie eingehende Daten validieren, die an Ihre Zieldatenbank übermittelt werden, um Fehler zu vermeiden und sicherzustellen, dass die Daten für Benutzer sofort nützlich sind.

Hier ist eine Checkliste allgemeiner Elemente, die ein Datenbankschema enthalten sollte:
Die relevanten Daten: Das Schema beschreibt, wie die Daten in der Datenbank modelliert und geformt werden, und muss alle beschriebenen Daten umfassen.
Namen und Datentypen für jede Spalte: Geben Sie Namen und Datentypen für jede Spalte in jeder Tabelle innerhalb der Datenbank an.
Konsistente Formatierung: Stellen Sie eine konsistente Formatierung aller Dateneinträge sicher. Jeder Eintrag ist eine Instanz des Schemas und muss daher konsistent sein.
Eindeutige Schlüssel: Das Schema muss für jeden Eintrag in der Datenbank eindeutige Schlüssel verwenden. Diese Schlüssel stellen Verbindungen zwischen den Tabellen her und ermöglichen es Benutzern, relevante Daten aus der gesamten Datenbank zu kombinieren.
Die zentralen Thesen
Wenn Sie mehr Daten erhalten oder sich die Geschäftsanforderungen ändern, müssen möglicherweise auch Datenbanken und Schemata geändert werden. Die Datenbankoptimierung ist ein iterativer Prozess, was bedeutet, dass Sie das Schema während der Nutzungsdauer der Datenbank möglicherweise mehrmals überprüfen müssen. Mithilfe dieser Checkliste können Sie sicherstellen, dass Ihr Datenbankschema funktionsfähig bleibt.
Überprüfen Sie ein Datenbankschema
Bisher haben Sie die Unterschiede zwischen verschiedenen Arten von Datenbankschemata kennengelernt, die Faktoren, die die Wahl der Datenbankschemata beeinflussen, und wie Sie mithilfe von Best Practices ein Datenbankschema für ein Data Warehouse entwerfen.
In dieser Lektüre überprüfen Sie ein Datenbankschema, das für ein fiktives Szenario erstellt wurde, und erkunden die Gründe für seinen Entwurf. In Ihrer Rolle als BI-Experte müssen Sie verstehen, warum eine Datenbank auf eine bestimmte Weise erstellt wurde.
Datenbankschema
Francisco’s Electronics eröffnet einen E-Commerce-Shop für seine neue Home-Office-Produktlinie. Im Erfolgsfall planen Unternehmensentscheider, auch die restlichen Produkte online zu stellen. Das Unternehmen engagierte Mia, eine leitende BI-Ingenieurin, um bei der Gestaltung seines Data Warehouse zu helfen. Die Datenbank musste Auftragsdaten für Analysen und Berichte speichern, und der Vertriebsleiter musste schnell Berichte erstellen, um die Verkäufe zu verfolgen, damit der Erfolg der Website bestimmt werden konnte.
Unten finden Sie ein Diagramm des Schemas der sales_warehouse -Datenbank, die Mia entworfen hat. Es enthält verschiedene Symbole und Anschlüsse, die zwei wichtige Informationen darstellen: die Haupttabellen innerhalb des Systems und die Beziehungen zwischen diesen Tabellen.

Das Datenbankschema sales_warehouse enthält fünf Tabellen: Sales, Products, Users, Locations und Orders, die über Schlüssel verbunden sind. Die Tabellen enthalten fünf bis acht Spalten (oder Attribute) unterschiedlicher Datentypen. Zu den Datentypen gehören varchar oder char (oder Zeichen), Ganzzahl, Dezimalzahl, Datum, Text (oder Zeichenfolge), Zeitstempel, Bit und andere Typen, abhängig vom gewählten Datenbanksystem.
Überprüfen Sie das Datenbankschema
Um ein Datenbankschema zu verstehen, ist es hilfreich, den Zweck der Verwendung bestimmter Datentypen und die Beziehungen zwischen Feldern zu verstehen. Die Antworten auf die folgenden Fragen rechtfertigen, warum Mia das Schema von Franciscos Elektronik auf diese Weise entworfen hat:
Was für ein Datenbankschema ist das? Warum wurde dieser Datenbanktyp ausgewählt?
Mia hat die Datenbank mit einem Sternschema entworfen , da Francisco’s Electronics diese Datenbank für Berichte und Analysen verwendet. Zu den Vorteilen des Star-Schemas gehören einfachere Abfragen, vereinfachte Geschäftsberichtslogik, höhere Abfrageleistung und schnelle Aggregationen.
Welche Namenskonventionen werden für die Tabellen und Felder verwendet? Gibt es Vorteile bei der Verwendung dieser Namenskonventionen?
Dieses Schema verwendet eine Namenskonvention für Groß- und Kleinschreibung. Im Schlangenfall ersetzen Unterstriche Leerzeichen und der erste Buchstabe jedes Wortes ist ein Kleinbuchstabe. Die Verwendung einer Namenskonvention trägt zur Wahrung der Konsistenz bei und verbessert die Lesbarkeit der Datenbank. Da „Snake Case“ für Tabellen und Felder ein Industriestandard ist, hat Mia ihn in der Datenbank verwendet.
Was ist der Zweck der Verwendung der Dezimalfelder in Datenelementen?
Bei Feldern, die sich auf Geld beziehen, kann es bei der Berechnung von Preisen, Steuern und Gebühren zu Fehlern kommen. Möglicherweise haben Sie Werte, die technisch unmöglich sind, z. B. einen Wert von 0,001 US-Dollar, während der kleinste Wert für den US-Dollar einen Cent oder 0,01 US-Dollar beträgt. Um die Werte konsistent zu halten und akkumulierte Fehler zu vermeiden, verwendete Mia einen Datentyp „decimal(10,2)“ , der nur die letzten beiden Ziffern nach dem Dezimalpunkt behält.
Hinweis: Andere numerische Werte wie Wechselkurse und Mengen benötigen möglicherweise zusätzliche Dezimalstellen, um Rundungsdifferenzen bei Berechnungen zu minimieren. Außerdem sind andere Datentypen möglicherweise besser für andere Felder geeignet. Um zu verfolgen, wann eine Bestellung erstellt wird ( created_at ), können Sie einen Zeitstempel-Datentyp verwenden. Für andere Felder mit unterschiedlichen Textgrößen können Sie Varchar verwenden.
Welchen Zweck haben die einzelnen Fremd- und Primärschlüssel in der Datenbank?
Mia entwarf die Sales-Tabelle mit einer Primärschlüssel-ID und fügte Fremdschlüssel in die anderen Tabellen ein, um auf die Primärschlüssel zu verweisen. Die Fremdschlüssel müssen vom gleichen Datentyp sein wie die entsprechenden Primärschlüssel. Wie Sie erfahren haben, identifizieren Primärschlüssel eindeutig genau einen Datensatz in einer Tabelle, und Fremdschlüssel stellen Integritätsreferenzen von diesem Primärschlüssel zu Datensätzen in anderen Tabellen her.
Verkaufstabellenschlüssel-ID und Fremdschlüssel | Zugehöriger Tisch |
|---|---|
Auftragsnummer | Bestelltabelle |
Produkt ID | Produkttabelle |
Benutzer-ID | Benutzertabelle |
Versandadresse_ID | Standorttabelle |
billing_address_id | Standorttabelle |
Die zentralen Thesen
In dieser Lektüre haben Sie untersucht, warum ein Datenbankschema auf eine bestimmte Weise entworfen wurde. In der Welt der Business Intelligence verbringen Sie viel Zeit damit, Geschäftsabläufe anhand von Daten zu modellieren, Daten zu untersuchen und Datenbanken zu entwerfen. Sie können Ihr Wissen über den Entwurf dieses Datenbankschemas anwenden, um in Zukunft Ihre eigenen Datenbanken zu erstellen. Dadurch können Sie in Ihrer Karriere als BI-Experte Daten effizienter nutzen und speichern.
Leitfaden zum Datenfluss
Wie Sie erfahren haben, ist Dataflow ein serverloser Datenverarbeitungsdienst, der Daten aus der Quelle liest, sie umwandelt und am Zielort schreibt. Dataflow erstellt Pipelines mit Open-Source-Bibliotheken, mit denen Sie in verschiedenen Sprachen, einschließlich Python und SQL, interagieren können. Diese Lektüre enthält Informationen zum Zugriff auf Dataflow und seiner Funktionalität.
Navigieren Sie auf der Homepage
Wenn Sie das optionale abgeschlossen habenErstellen Sie ein Google Cloud-Konto Aktivität können Sie die Schritte dieser Lektüre in Ihrer Dataflow-Konsole verfolgen. Gehe zumDatenfluss Google CloudStartseite und melden Sie sich bei Ihrem Konto an, um auf Dataflow zuzugreifen. Klicken Sie dann auf die Schaltfläche „Zur Konsole gehen“ oder die Schaltfläche „Konsole“ . Hier können Sie neue Jobs erstellen und auf Dataflow-Tools zugreifen.

Arbeitsplätze
Wenn Sie die Konsole zum ersten Mal öffnen, finden Sie die Seite „Jobs“ . Auf der Seite „Jobs“ befinden sich Ihre aktuellen Jobs in Ihrem Projektbereich. Auf dieser Seite gibt es auch die Optionen JOB AUS VORLAGE ERSTELLEN oder VERWALTETE DATEN-PIPELINE ERSTELLEN, sodass Sie in Ihrer Dataflow-Konsole mit einem neuen Projekt beginnen können. Hierher kommen Sie jederzeit, wenn Sie etwas Neues beginnen möchten.

Pipelines
Öffnen Sie den Menübereich, um durch die Konsole zu navigieren und die anderen Seiten in Dataflow zu finden. Das Menü „Pipelines“ enthält eine Liste aller von Ihnen erstellten Pipelines. Wenn Sie Dataflow zum ersten Mal verwenden, werden auch die Prozesse angezeigt, die Sie aktivieren müssen, bevor Sie mit dem Aufbau von Pipelines beginnen können. Wenn Sie die APIs noch nicht aktiviert haben, klicken Sie auf „Alle reparieren“ , um die API-Funktionen zu aktivieren und Ihren Standort festzulegen.

Werkbank
Im Workbench- Bereich können Sie gemeinsam nutzbare Jupyter-Notebooks mit Live-Code erstellen und speichern. Dies ist hilfreich für Erstbenutzer des ETL-Tools, um Beispiele auszuprobieren und die Transformationen zu visualisieren.

Schnappschüsse
Snapshots speichern den aktuellen Status einer Pipeline, um neue Versionen zu erstellen, ohne den aktuellen Status zu verlieren. Dies ist nützlich, wenn Sie aktuelle Pipelines testen oder aktualisieren, damit das System nicht gestört wird. Mit dieser Funktion können Sie auch alte Projektversionen sichern und wiederherstellen. Möglicherweise müssen Sie APIs aktivieren, um die Seite „Snapshots“ anzuzeigen. In einer kommenden Aktivität erfahren Sie mehr über APIs.

SQL-Arbeitsbereich
Im SQL-Arbeitsbereich schließlich interagieren Sie mit Ihren Dataflow-Jobs, stellen eine Verbindung zur BigQuery-Funktionalität her und schreiben notwendige SQL-Abfragen für Ihre Pipelines.

Dataflow bietet Ihnen auch die Möglichkeit, mit Ihren Datenbanken mithilfe anderer Programmiersprachen zu interagieren. Für diese Kurse werden Sie jedoch hauptsächlich SQL verwenden.
Dataflow ist eine wertvolle Möglichkeit, mit dem Aufbau von Pipelines zu beginnen und einige der Fähigkeiten zu üben, die Sie in diesem Kurs erlernt haben. Demnächst werden Sie mehr Möglichkeiten haben, mit Dataflow zu arbeiten, also ist jetzt ein guter Zeitpunkt, sich mit der Benutzeroberfläche vertraut zu machen!
Fallstudie: Wayfair – Zusammenarbeit mit Stakeholdern zur Erstellung einer Pipeline
Die Zusammenarbeit mit Stakeholdern beim Entwerfen und Iterieren eines Pipeline-Systems ist eine wichtige Strategie, um sicherzustellen, dass die von Ihnen eingerichteten BI-Systeme ihren Geschäftsanforderungen entsprechen. In dieser Fallstudie erfahren Sie, wie das BI-Team eines E-Commerce-Einzelhändlers arbeitetWayfairmit Hauptsitz in Boston, Massachusetts, arbeitet während eines Projekts mit seinen Stakeholdern zusammen, um ein Pipelinesystem zu schaffen, das für sie funktioniert.

Firmenhintergrund
Die langjährigen Freunde Niraj Shah und Steve Conine gründeten das reine Online-Unternehmen im Jahr 2002, nachdem sie beschlossen hatten, ihren Kunden eine größere Auswahl an Auswahlmöglichkeiten bieten zu wollen – mehr, als in einen stationären Raum passen würde. Sie gründeten das Unternehmen als eine Ansammlung von mehr als 200 E-Commerce-Shops, die jeweils unterschiedliche Produktkategorien verkauften. Im Jahr 2011 führte das Unternehmen diese Websites zusammen, um wayfair.com zu gründen.

Wayfair ist heute einer der weltweit größten Einzelhändler für Wohnimmobilien. Das Ziel des Unternehmens ist es, allen Menschen überall dabei zu helfen, ihr Heimatgefühl zu schaffen. Es ermöglicht Kunden, Räume zu schaffen, die widerspiegeln, wer sie sind, was sie brauchen und was sie wertschätzen.

Die Herausforderung
Das Wayfair-Preis-Ökosystem umfasst Tausende verschiedener Ein- und Ausgaben für einen vollständigen Produktkatalog, die sich mehrmals täglich ändern. Alle diese Ein- und Ausgänge werden auf unterschiedliche Weise aus unterschiedlichen Quellen generiert. Aus diesem Grund hatten das BI-Team und andere Datenexperten, die auf Preisdaten zugreifen mussten, Schwierigkeiten, den gesamten Datensatz zu finden, abzufragen und zu interpretieren. Dies führte zu unvollständigen und oft ungenauen Erkenntnissen, die für Entscheidungsträger nicht nützlich waren.
Um dieses Problem anzugehen, beschloss das BI-Team, ein neues Pipeline-System zu entwerfen und zu implementieren, um alle benötigten Datenbeteiligten zu konsolidieren. Außerdem mussten sie einige zusätzliche Herausforderungen bei ihrem Pipelinesystem berücksichtigen:
Überwachung und Berichterstattung rund um diese Prozesse müssten in den Entwurf einbezogen werden, um Fehler zu verfolgen und zu verwalten.
Die Daten müssten sauber sein, bevor sie mit nachgeschalteten Benutzern geteilt werden könnten.
Aufgrund der Vielzahl der zusammenzuführenden Datentypen musste das BI-Team auch die Datenbeziehungen besser verstehen, damit es die Daten genau konsolidieren konnte.
Es wären Schulungen erforderlich, um den Benutzern beizubringen, wie sie am besten auf die neuen Datensätze zugreifen und diese nutzen können.
Aufgrund dieser einzigartigen Herausforderungen war es für das BI-Team besonders wichtig, bei der Entwicklung des neuen Systems eng mit den Stakeholdern zusammenzuarbeiten, um deren Anforderungen zu erfüllen und etwas zu schaffen, das über mehrere Teams hinweg funktioniert.
Die Vorgehensweise
Angesichts der riesigen Datenmenge im System war es für das BI-Team wichtig, einen Schritt zurückzutreten und mit den Stakeholdern zusammenzuarbeiten, um wirklich zu verstehen, wie sie die Daten derzeit nutzen. Dazu gehörte das Verständnis der Geschäftsprobleme, die sie zu lösen versuchten, der Daten, die sie bereits verwendeten und wie sie darauf zugegriffen haben, sowie der Daten, die sie verwenden wollten, auf die sie aber noch nicht zugreifen konnten.
Nach der Kommunikation mit den Stakeholdern konnte das Team eine Pipeline entwerfen, mit der drei Hauptziele erreicht wurden:
Alle erforderlichen Daten könnten verfügbar und leicht verständlich und nutzbar gemacht werden
Das System war effizienter und konnte Daten ohne Verzögerungen zur Verfügung stellen
Das System wurde so konzipiert, dass es mit der vertikalen und horizontalen Erweiterung des Datensatzes skaliert werden kann, um zukünftiges Wachstum zu unterstützen
Nachdem dieser erste Entwurf fertiggestellt war, wurde das System den Stakeholdern zur Überprüfung vorgelegt, um sicherzustellen, dass sie das System verstanden und alle ihre Anforderungen erfüllten. Dieses Projekt erforderte die Zusammenarbeit verschiedener Interessengruppen und Teams:
Software-Ingenieure : Das Team der Software-Ingenieure war der Haupteigentümer und Erzeuger der Daten. Daher waren sie von entscheidender Bedeutung für das Verständnis des aktuellen Zustands der Daten und halfen dabei, diese für das BI-Team zugänglich zu machen, damit sie damit arbeiten konnten.
Datenarchitekten : Das BI-Team hat sich mit Datenarchitekten beraten, um sicherzustellen, dass das Pipeline-Design allumfassend, effizient und skalierbar ist, damit das BI-Team die vom System erfasste Datenmenge bewältigen und sicherstellen kann, dass nachgeschaltete Benutzer Zugriff darauf haben Daten, während das System skaliert wurde.
Datenexperten: Als Hauptbenutzer stellten diese Teams die Anwendungsfälle und Anforderungen für das System bereit, damit das BI-Team sicherstellen konnte, dass die Pipeline ihren Anforderungen entsprach. Da die Anforderungen der jeweiligen Teams unterschiedlich waren, war es wichtig sicherzustellen, dass das Systemdesign und die enthaltenen Daten umfassend genug waren, um alle diese Anforderungen zu berücksichtigen.
Geschäftsinteressenvertreter: Als Endnutzer der durch die gesamte Pipeline generierten Erkenntnisse stellten die Geschäftsinteressenvertreter sicher, dass alle Entwicklungsarbeiten und Anwendungsfälle auf klaren Geschäftsproblemen beruhten, um sicherzustellen, dass das, was das BI-Team erstellt hatte, sofort auf ihre Arbeit angewendet werden konnte.
Die Kommunikation mit allen Beteiligten während des gesamten Designprozesses stellte sicher, dass das Wayfair BI-Team etwas Nützliches und Langlebiges für sein Unternehmen geschaffen hat.
Die Ergebnisse
Die endgültige Pipeline, die das BI-Team implementierte, erreichte eine Reihe wichtiger Ziele für die gesamte Organisation:
Es ermöglichte Softwareentwicklungsteams, Daten in Echtzeit zu veröffentlichen, damit das BI-Team sie nutzen kann.
Die verschiedenen Datenkomponenten wurden in einem einheitlichen Datensatz zusammengefasst, um den Zugriff und die Verwendung zu erleichtern.
Dadurch konnte das BI-Team verschiedene Datenkomponenten in ihren eigenen Staging-Ebenen speichern.
Es umfasste zusätzliche Prozesse zur Überwachung und Berichterstattung über die Systemleistung, um Benutzer über aufgetretene Fehler zu informieren und schnelle Lösungen zu ermöglichen.
Es wurde ein einheitlicher Datensatz erstellt, den Benutzer nutzen konnten, um Metriken zu erstellen und Datenberichte zu erstellen.
Der größte Vorteil dieser Pipeline-Lösung bestand darin, dass Wayfair nun in der Lage war, den Benutzern präzise Informationen an einem Ort bereitzustellen, wodurch die Notwendigkeit entfiel, selbst verschiedene Quellen zusammenzuführen. Dies bedeutete, dass das Team den Stakeholdern genauere Erkenntnisse liefern und kostspielige Ad-hoc-Prozesse vermeiden konnte.
Die Resonanz war teamübergreifend sehr positiv. Der Analytics-Direktor bei Wayfair sagte, dass dies für die tägliche Arbeit seines Teams revolutionär sei, da es zum ersten Mal Informationen zu Einzelhandelspreisen, Kosteneingaben und Produktstatus an derselben Stelle habe. Dies war ein großer Vorteil für ihre Prozesse und half ihnen, ihre Daten intelligenter zu verwalten.
Abschluss
Ein wesentlicher Vorteil, den Business Intelligence einem Unternehmen bietet, besteht darin, dass es die Systeme und Prozesse für Benutzer im gesamten Unternehmen effizienter und effektiver macht. Grundsätzlich erleichtert BI die Arbeit aller ein wenig. Für den Erfolg ist es von entscheidender Bedeutung, dass das BI-Team eng mit den Geschäftsinteressenten und anderen Teams zusammenarbeitet. Ohne gute Partnerschaft können Probleme nicht richtig gelöst werden.
Sehen Sie sich den Inhalt des Google Data Analytics-Zertifikats zu bewährten SQL-Methoden an
Zu diesen Best Practices gehören Richtlinien zum Schreiben von SQL-Abfragen, zum Entwickeln von Dokumentationen und Beispiele, die diese Praktiken veranschaulichen. Dies ist eine großartige Ressource, die Sie zur Hand haben sollten, wenn Sie selbst SQL verwenden; Sie können einfach direkt zum entsprechenden Abschnitt gehen, um diese Praktiken zu überprüfen. Betrachten Sie es wie einen SQL-Feldführer!
Groß- und Kleinschreibung beachten
Bei SQL spielt die Groß- und Kleinschreibung normalerweise keine Rolle. Sie könnten SELECT oder select oder SeLeCT schreiben. Sie funktionieren alle! Wenn Sie jedoch die Groß- und Kleinschreibung als Teil eines konsistenten Stils verwenden, sehen Ihre Abfragen professioneller aus.
Um SQL-Abfragen wie ein Profi zu schreiben, ist es immer eine gute Idee, für Klauselstarter Großbuchstaben zu verwenden (z. B. SELECT, FROM, WHERE usw.). Funktionen sollten auch in Großbuchstaben geschrieben werden (z. B. SUM()). Spaltennamen sollten ausschließlich in Kleinbuchstaben geschrieben sein (siehe Abschnitt über „snake_case“ weiter unten in diesem Handbuch). Tabellennamen sollten in CamelCase vorliegen (siehe Abschnitt über CamelCase weiter unten in diesem Handbuch). Dies trägt dazu bei, dass Ihre Abfragen konsistent und leichter lesbar bleiben, ohne dass dies Auswirkungen auf die Daten hat, die bei der Ausführung abgerufen werden. Die Groß- und Kleinschreibung spielt nur dann eine Rolle, wenn sie in Anführungszeichen steht (mehr zu Anführungszeichen weiter unten).
Anbieter von SQL-Datenbanken verwenden möglicherweise leicht unterschiedliche SQL-Varianten. Diese Variationen werden SQL-Dialekte genannt . Bei einigen SQL-Dialekten muss die Groß-/Kleinschreibung beachtet werden. BigQuery ist einer davon. Vertica ist eine andere. Aber die meisten, wie MySQL, PostgreSQL und SQL Server, berücksichtigen nicht die Groß-/Kleinschreibung. Das heißt, wenn Sie nach „country_code = „us““ gesucht haben, werden alle Einträge zurückgegeben, die „us“, „uS“, „Us“ und „US“ enthalten. Dies ist bei BigQuery nicht der Fall. Bei BigQuery wird die Groß-/Kleinschreibung beachtet, sodass dieselbe Suche nur Einträge zurückgibt, bei denen der Ländercode genau „us“ lautet. Wenn der Ländercode „US“ lautet, würde BigQuery diese Einträge nicht als Teil Ihres Ergebnisses zurückgeben.
Einfache oder doppelte Anführungszeichen: “ oder “ „
In den meisten Fällen spielt es auch keine Rolle, ob Sie bei der Bezugnahme auf Zeichenfolgen einfache Anführungszeichen „ “ oder doppelte Anführungszeichen „ “ verwenden. Beispielsweise ist SELECT ein Klauselstarter. Wenn Sie SELECT in Anführungszeichen wie „SELECT“ oder „SELECT“ setzen, behandelt SQL es als Textzeichenfolge. Ihre Abfrage gibt einen Fehler zurück, da Ihre Abfrage eine SELECT-Klausel benötigt.
Es gibt jedoch zwei Situationen, in denen es wichtig ist, welche Art von Anführungszeichen Sie verwenden:
Wenn Sie möchten, dass Zeichenfolgen in jedem SQL-Dialekt identifizierbar sind
Wenn Ihre Zeichenfolge ein Apostroph oder Anführungszeichen enthält
In jedem SQL-Dialekt gibt es Regeln dafür, was akzeptiert wird und was nicht. Eine allgemeine Regel in fast allen SQL-Dialekten besteht jedoch darin, einfache Anführungszeichen für Zeichenfolgen zu verwenden. Dies hilft, eine Menge Verwirrung zu beseitigen. Wenn wir also in einer WHERE-Klausel auf das Land US verweisen möchten (z. B. Country_code = ‚US‘), dann verwenden Sie einfache Anführungszeichen um die Zeichenfolge ‚US‘.
Die zweite Situation ist, wenn Ihre Zeichenfolge Anführungszeichen enthält. Angenommen, Sie haben eine Spalte mit Lieblingsspeisen in einer Tabelle namens FavoriteFoods und die andere Spalte entspricht jedem Freund.
Freund | Lieblingsessen |
|---|---|
Rachel DeSantos | Hirtenkuchen |
Sujin Lee | Tacos |
Najil Okoro | Spanische Paella |
Möglicherweise fällt Ihnen auf, dass Rachels Lieblingsessen ein Apostroph enthält. Wenn Sie in einer WHERE-Klausel einfache Anführungszeichen verwenden würden, um den Freund zu finden, der dieses Lieblingsessen hat, würde das so aussehen:

Das wird nicht funktionieren. Wenn Sie diese Abfrage ausführen, erhalten Sie als Antwort eine Fehlermeldung. Dies liegt daran, dass SQL eine Textzeichenfolge als etwas erkennt, das mit einem Anführungszeichen beginnt und mit einem weiteren Anführungszeichen endet. In der obigen fehlerhaften Abfrage geht SQL also davon aus, dass das gesuchte Lieblingsessen „Shepherd“ ist. Nur „Shepherd“, weil das Apostroph in Shepherd die Zeichenfolge beendet.
Im Allgemeinen sollte dies das einzige Mal sein, dass Sie doppelte Anführungszeichen anstelle von einfachen Anführungszeichen verwenden. Ihre Abfrage würde also stattdessen so aussehen:

SQL versteht Textzeichenfolgen so, dass sie entweder mit einem einfachen Anführungszeichen ‚ oder einem doppelten Anführungszeichen beginnen. Da diese Zeichenfolge mit doppelten Anführungszeichen beginnt, erwartet SQL ein weiteres doppeltes Anführungszeichen, um das Ende der Zeichenfolge anzuzeigen. Dadurch bleibt das Apostroph geschützt, sodass es „ zurückgibt. „Shepherd’s Pie“ und nicht „Shepherd“.
Kommentare als Erinnerung
Je vertrauter Sie mit SQL werden, desto besser können Sie Abfragen auf einen Blick lesen und verstehen. Aber es schadet nie, Kommentare in die Abfrage einzufügen, um sich daran zu erinnern, was Sie tun möchten. Und wenn Sie Ihre Anfrage teilen, hilft es auch anderen, sie zu verstehen.
Zum Beispiel:

Sie können in der obigen Abfrage # anstelle der beiden Bindestriche — verwenden. Beachten Sie jedoch, dass # nicht in allen SQL-Dialekten erkannt wird (MySQL erkennt # nicht). Daher ist es am besten, es zu verwenden – und konsequent dabei zu bleiben. Wenn Sie mit — einen Kommentar zu einer Abfrage hinzufügen, ignoriert die Datenbankabfrage-Engine alles in derselben Zeile nach –. Die Verarbeitung der Abfrage wird ab der nächsten Zeile fortgesetzt.
Snake_case-Namen für Spalten
Es ist wichtig, immer sicherzustellen, dass die Ausgabe Ihrer Abfrage leicht verständliche Namen hat. Wenn Sie eine neue Spalte erstellen (z. B. aus einer Berechnung oder aus der Verkettung neuer Felder), erhält die neue Spalte einen generischen Standardnamen (z. B. f0). Zum Beispiel:

Ergebnisse sind:
f0 | f1 | total_tickets | number_of_purchases |
|---|---|---|---|
8 | 4 | 8 | 4 |
Die ersten beiden Spalten heißen f0 und f1, da sie in der obigen Abfrage nicht benannt wurden. SQL verwendet standardmäßig f0, f1, f2, f3 usw. Wir haben die letzten beiden Spalten „total_tickets“ und „number_of_purchases“ benannt, damit diese Spaltennamen in den Abfrageergebnissen angezeigt werden. Aus diesem Grund ist es immer sinnvoll, Ihren Spalten sinnvolle Namen zu geben, insbesondere wenn Sie Funktionen verwenden. Nachdem Sie Ihre Abfrage ausgeführt haben, möchten Sie Ihre Ergebnisse, wie die letzten beiden Spalten, die wir im Beispiel beschrieben haben, schnell verstehen.
Darüber hinaus fällt Ihnen möglicherweise auf, dass zwischen den Wörtern in den Spaltennamen ein Unterstrich steht. Namen sollten niemals Leerzeichen enthalten. Wenn „total_tickets“ ein Leerzeichen hätte und wie „totaltickets“ aussehen würde, würde SQL SUM(tickets) einfach in „total“ umbenennen. Aufgrund des Platzes verwendet SQL „total“ als Namen und versteht nicht, was Sie mit „Tickets“ meinen. Daher sind Leerzeichen in SQL-Namen schlecht. Verwenden Sie niemals Leerzeichen.
Die beste Vorgehensweise ist die Verwendung von „snake_case“. Das bedeutet, dass „totaltickets“, bei dem zwischen den beiden Wörtern ein Leerzeichen steht, als „total_tickets“ mit einem Unterstrich anstelle eines Leerzeichens geschrieben werden sollte.
CamelCase-Namen für Tabellen
Sie können bei der Benennung Ihrer Tabelle auch die CamelCase-Großschreibung verwenden. CamelCase-Großschreibung bedeutet, dass Sie den Anfang jedes Wortes groß schreiben, wie bei einem zweihöckrigen (baktrischen) Kamel. Daher verwendet die Tabelle TicketsByOccasion die CamelCase-Großschreibung. Bitte beachten Sie, dass die Großschreibung des ersten Wortes in CamelCase optional ist; CamelCase wird ebenfalls verwendet. Manche Leute unterscheiden zwischen den beiden Stilen, indem sie CamelCase, PascalCase nennen und camelCase für den Fall reservieren, dass das erste Wort nicht großgeschrieben wird, wie bei einem einhöckrigen Kamel (Dromedar); zum Beispiel „ticketsByOccasion“.
Letztendlich ist CamelCase eine Stilwahl. Es gibt andere Möglichkeiten, Ihre Tabellen zu benennen, darunter:
Alles in Klein- oder Großschreibung, z. B. „ticketsbyoccasion“ oder „TICKETSBYOCCASION“.
Mit Snake_case, wie Tickets_by_occasion
Beachten Sie, dass die Option mit ausschließlich Klein- oder Großbuchstaben das Lesen Ihres Tabellennamens erschweren kann und daher nicht für den professionellen Gebrauch empfohlen wird.
Die zweite Option, „snake_case“, ist technisch in Ordnung. Wenn die Wörter durch Unterstriche getrennt sind, ist Ihr Tabellenname gut lesbar, kann aber durch das Hinzufügen der Unterstriche sehr lang werden. Außerdem nimmt das Schreiben mehr Zeit in Anspruch. Wenn Sie diesen Tisch häufig benutzen, kann es zu einer lästigen Pflicht werden.
Zusammenfassend lässt sich sagen, dass es Ihnen überlassen bleibt, beim Erstellen von Tabellennamen „snake_case“ oder „CamelCase“ zu verwenden. Stellen Sie einfach sicher, dass Ihr Tabellenname leicht lesbar und konsistent ist. Stellen Sie außerdem sicher, dass Sie herausfinden, ob Ihr Unternehmen eine bevorzugte Art der Tabellenbenennung hat. Wenn dies der Fall ist, halten Sie sich aus Konsistenzgründen immer an die Namenskonvention.
Vertiefung
Als allgemeine Regel gilt, dass die Länge jeder Zeile in einer Abfrage <= 100 Zeichen betragen soll. Dadurch sind Ihre Abfragen leicht lesbar. Sehen Sie sich zum Beispiel diese Abfrage mit einer Zeile mit mehr als 100 Zeichen an:

Diese Abfrage ist schwer zu lesen und ebenso schwer zu beheben oder zu bearbeiten. Hier ist nun eine Abfrage, bei der wir uns an die <= 100-Zeichen-Regel halten:

Jetzt ist es viel einfacher zu verstehen, was Sie mit der SELECT-Klausel tun möchten. Natürlich werden beide Abfragen problemlos ausgeführt, da Einrückungen in SQL keine Rolle spielen. Dennoch ist die richtige Einrückung wichtig, um die Zeilen kurz zu halten. Und jeder, der Ihre Anfrage liest, wird es zu schätzen wissen, auch Sie selbst!
Mehrzeilige Kommentare
Wenn Sie Kommentare verfassen, die mehrere Zeilen umfassen, können Sie — für jede Zeile verwenden. Wenn Sie mehr als zwei Kommentarzeilen haben, ist es möglicherweise sauberer und einfacher, /* zum Starten des Kommentars und */ zum Schließen des Kommentars zu verwenden. Beispielsweise können Sie die Methode — wie folgt verwenden:

Oder Sie können die /* */-Methode wie folgt verwenden:

In SQL spielt es keine Rolle, welche Methode Sie verwenden. SQL ignoriert Kommentare unabhängig davon, was Sie verwenden: #, — oder /* und */. Es liegt also an Ihnen und Ihren persönlichen Vorlieben. Die Methoden /* und */ für mehrzeilige Kommentare sehen normalerweise sauberer aus und helfen dabei, die Kommentare von der Abfrage zu trennen. Aber es gibt nicht die eine richtige oder falsche Methode.
SQL-Texteditoren
Wenn Sie einem Unternehmen beitreten, können Sie davon ausgehen, dass jedes Unternehmen seine eigene SQL-Plattform und seinen eigenen SQL-Dialekt verwendet. Auf der von ihnen verwendeten SQL-Plattform (z. B. BigQuery, MySQL oder SQL Server) schreiben Sie Ihre SQL-Abfragen und führen sie aus. Beachten Sie jedoch, dass nicht alle SQL-Plattformen native Skripteditoren zum Schreiben von SQL-Code bereitstellen. SQL-Texteditoren bieten Ihnen eine Schnittstelle, über die Sie Ihre SQL-Abfragen einfacher und farbcodiert schreiben können. Tatsächlich wurde der gesamte Code, mit dem wir bisher gearbeitet haben, mit einem SQL-Texteditor geschrieben!
Beispiele mit erhabenem Text
Wenn Ihre SQL-Plattform nicht über eine Farbcodierung verfügt, sollten Sie über die Verwendung eines Texteditors wie z. B. nachdenkenErhabener TextoderAtom. In diesem Abschnitt wird gezeigt, wie SQL in Sublime Text angezeigt wird. Hier ist eine Abfrage in Sublime Text:

Mit Sublime Text können Sie auch erweiterte Bearbeitungen durchführen, wie etwa das gleichzeitige Löschen von Einzügen über mehrere Zeilen hinweg. Angenommen, Ihre Abfrage hatte irgendwie Einzüge an den falschen Stellen und sah so aus:

Das ist wirklich schwer zu lesen, deshalb sollten Sie diese Einrückungen entfernen und von vorne beginnen. Auf einer normalen SQL-Plattform müssten Sie in jede Zeile gehen und die RÜCKTASTE drücken, um jeden Einzug pro Zeile zu löschen. Aber in Sublime können Sie alle Einrückungen gleichzeitig entfernen, indem Sie alle Zeilen auswählen und Befehl (oder STRG in Windows) + [ drücken. Dadurch werden Einzüge in jeder Zeile vermieden. Anschließend können Sie die Zeilen auswählen, die Sie einrücken möchten (z. B. Zeilen 2, 4 und 6), indem Sie die Befehlstaste (oder die STRG-Taste in Windows) drücken und diese Zeilen auswählen. Halten Sie dann weiterhin die Befehlstaste (oder die STRG-Taste in Windows) gedrückt und drücken Sie ], um die Zeilen 2, 4 und 6 gleichzeitig einzurücken. Dadurch wird Ihre Abfrage bereinigt und sie sieht stattdessen wie folgt aus:

Sublime Text unterstützt auch reguläre Ausdrücke. Mit regulären Ausdrücken (oder Regex ) können Sie in Abfragen nach Zeichenfolgenmustern suchen und diese ersetzen. Wir gehen hier nicht auf reguläre Ausdrücke ein, aber vielleicht möchten Sie selbst mehr darüber erfahren, da sie ein sehr leistungsfähiges Werkzeug sind.
Sie können mit diesen Ressourcen beginnen:
Regex-Tutorial (Wenn Sie nicht wissen, was reguläre Ausdrücke sind)
Indizes, Partitionen und andere Möglichkeiten zur Optimierung
Optimierung für das Datenlesen
Eine der ständigen Aufgaben einer Datenbank ist das Auslesen von Daten. Beim Lesen handelt es sich um den Prozess der Interpretation und Verarbeitung von Daten, um sie für Benutzer verfügbar und nützlich zu machen. Wie Sie erfahren haben, ist die Datenbankoptimierung der Schlüssel zur Maximierung der Geschwindigkeit und Effizienz beim Datenabruf, um eine hohe Datenbankleistung sicherzustellen. Die Optimierung des Lesevorgangs ist eine der wichtigsten Möglichkeiten, die Datenbankleistung für Benutzer zu verbessern. Als Nächstes erfahren Sie mehr über verschiedene Möglichkeiten, wie Sie Ihre Datenbank zum Lesen von Daten optimieren können, einschließlich Indizierung und Partitionierung, Abfragen und Caching.
Indizes
Manchmal, wenn Sie ein Buch mit vielen Informationen lesen, wird am Ende des Buches ein Index eingefügt, in dem die Informationen nach Themen geordnet sind und für jede Referenz die Seitenzahlen aufgeführt sind. Das spart Ihnen Zeit, wenn Sie wissen, was Sie finden möchten – anstatt das gesamte Buch durchzublättern, können Sie direkt zum Index gehen, der Sie zu den benötigten Informationen führt.
Indizes in Datenbanken sind im Grunde dasselbe – sie verwenden die Schlüssel aus den Datenbanktabellen, um sehr schnell bestimmte Stellen in der Datenbank zu durchsuchen, anstatt die gesamte Sache. Aus diesem Grund sind sie für die Datenbankoptimierung so wichtig: Wenn Benutzer eine Suche in einer vollständig indizierten Datenbank durchführen, können die Informationen viel schneller zurückgegeben werden. Beispielsweise könnte eine Tabelle mit den Spalten „ID“, „Name“ und „Abteilung“ einen Index mit den entsprechenden Namen und IDs verwenden.

Jetzt kann die Datenbank die Namen in der größeren Tabelle für Suchvorgänge mithilfe dieser IDs aus dem Index schnell und einfach finden.
Partitionen
Die Datenpartitionierung ist eine weitere Möglichkeit, den Datenbankabruf zu beschleunigen. Es gibt zwei Arten der Partitionierung: vertikal und horizontal. Am gebräuchlichsten ist die horizontale Partitionierung. Dabei wird die Datenbank so gestaltet, dass Zeilen durch logische Gruppierungen organisiert und nicht in Spalten gespeichert werden. Die verschiedenen Zeilen werden in verschiedenen Tabellen gespeichert – dies reduziert die Indexgröße und erleichtert das Schreiben und Abrufen von Daten aus der Datenbank.
Anstatt eine Indextabelle zu erstellen, damit die Datenbank die Daten schneller durchsuchen kann, teilen Partitionen größere, unhandliche Tabellen in viel besser verwaltbare, kleinere Tabellen auf.

In diesem Beispiel wird die größere Verkaufstabelle in kleinere Tabellen unterteilt. Diese kleineren Tabellen lassen sich leichter abfragen, da die Datenbank nicht so viele Daten auf einmal durchsuchen muss.
Andere Optimierungsmethoden
Sie können Ihre Datenbank nicht nur einfacher durchsuchen, indem Sie Indizes und Partitionen verwenden, sondern auch Ihre tatsächlichen Suchvorgänge hinsichtlich der Lesbarkeit optimieren oder den zwischengespeicherten Speicher Ihres Systems nutzen, um beim Abrufen häufig verwendeter Daten Zeit zu sparen.
Abfragen
Abfragen sind Anfragen nach Daten oder Informationen aus einer Datenbank. In vielen Fällen verfügen Sie möglicherweise über eine Sammlung von Abfragen, die Sie regelmäßig ausführen. Dies können automatisierte Abfragen sein, die Berichte generieren, oder regelmäßige Suchvorgänge von Benutzern.
Wenn diese Abfragen nicht optimiert sind, kann es lange dauern, bis sie Ergebnisse an Benutzer zurückgeben, und im Allgemeinen Datenbankressourcen beanspruchen. Es gibt ein paar Dinge, die Sie tun können, um Abfragen zu optimieren:
Berücksichtigen Sie die Geschäftsanforderungen: Wenn Sie die Geschäftsanforderungen verstehen, können Sie feststellen, welche Informationen Sie wirklich aus der Datenbank abrufen müssen, und das System nicht unnötig belasten, indem Sie nach Daten fragen, die Sie eigentlich nicht benötigen.
Vermeiden Sie die Verwendung von SELECT* und SELECT DISTINCT: Die Verwendung von SELECT* und SELECT DISTINCT führt dazu, dass die Datenbank viele unnötige Daten analysieren muss. Stattdessen können Sie Abfragen optimieren, indem Sie nach Möglichkeit bestimmte Felder auswählen.
Verwenden Sie INNER JOIN anstelle von Unterabfragen: Die Verwendung von Unterabfragen führt dazu, dass die Datenbank eine große Anzahl von Ergebnissen analysiert und diese dann filtert, was mehr Zeit in Anspruch nehmen kann als das einfache JOIN-Verknüpfen von Tabellen.
Darüber hinaus können Sie voraggregierte Abfragen verwenden, um die Lesefunktionalität der Datenbank zu erhöhen. Grundsätzlich bedeutet das Voraggregieren von Daten, dass die Daten, die zum Messen bestimmter Metriken erforderlich sind, in Tabellen zusammengestellt werden, sodass die Daten nicht jedes Mal neu erfasst werden müssen, wenn Sie eine Abfrage darauf ausführen.
Wenn Sie mehr über die Optimierung von Abfragen erfahren möchten, können Sie hier vorbeischauenDevarts Artikel zur SQL-Abfrageoptimierung.
Caching
Schließlich kann der Cache eine nützliche Möglichkeit sein, die Lesbarkeit Ihrer Datenbank zu optimieren. Im Wesentlichen handelt es sich beim Cache um eine Schicht des Kurzzeitgedächtnisses, in der Tabellen und Abfragen gespeichert werden können. Indem Sie den Cache anstelle des Datenbanksystems selbst abfragen, können Sie tatsächlich Ressourcen sparen. Sie können einfach aus der Erinnerung nehmen, was Sie brauchen.
Wenn Sie beispielsweise häufig auf die Datenbank für jährliche Verkaufsberichte zugreifen, können Sie diese Berichte im Cache speichern und direkt aus dem Speicher abrufen, anstatt die Datenbank immer wieder auffordern zu müssen, sie zu generieren.
Die zentralen Thesen
Dieser Kurs hat sich stark auf die Datenbankoptimierung konzentriert und darauf, wie Sie als BI-Experte sicherstellen können, dass die Systeme und Lösungen, die Sie für Ihr Team erstellen, weiterhin so effizient wie möglich funktionieren. Die Verwendung dieser Methoden kann für Sie eine wichtige Möglichkeit sein, die Datenbankgeschwindigkeit und -verfügbarkeit zu verbessern, wenn Teammitglieder auf das Datenbanksystem zugreifen. Und bald werden Sie Gelegenheit haben, selbst mit diesen Konzepten zu arbeiten!
Aktivitätsbeispiel: Daten partitionieren und Indizes in BigQuery erstellen
Hier ist ein fertiges Exemplar zusammen mit einer Erklärung, wie das Exemplar die Erwartungen an die Aktivität erfüllt.
Bewertung von Exemplar

Vergleichen Sie das Exemplar mit Ihrer abgeschlossenen Tätigkeit. Überprüfen Sie Ihre Arbeit anhand der einzelnen Kriterien im Beispiel. Was hast du gut gemacht? Wo können Sie sich verbessern? Nutzen Sie Ihre Antworten auf diese Fragen als Leitfaden für den weiteren Verlauf des Kurses.
In der vorherigen Aktivität haben Sie SQL-Code ausgeführt, der Tabellen mit Partitionen und Indizes erstellt hat. Mithilfe von Partitionen und Indizes können Sie Verknüpfungen zu bestimmten Zeilen erstellen und große Datensätze in kleinere, besser verwaltbare Tabellen aufteilen. Durch die Erstellung von Partitionen und Indizes können Sie schnellere und effizientere Datenbanken erstellen und so das Abrufen von Daten erleichtern, wenn Sie diese analysieren oder visualisieren müssen.
Nach dem Erstellen der Tabellen haben Sie Abfragen für diese Tabellen ausgeführt, um deren Leistung zu vergleichen und zu demonstrieren, wie nützlich Partitionen und Indizes sein können.
Bei jedem Schritt haben Sie Screenshots des Bereichs „Details“ oder „Ausführungsdetails“ gemacht , um sie mit den folgenden Beispielbildern zu vergleichen. Dadurch können Sie sicherstellen, dass Sie die Aktivität ordnungsgemäß abgeschlossen haben. Außerdem wird erläutert, warum sich die von Ihnen erstellten Tabellen und die von Ihnen ausgeführten Abfragen voneinander unterscheiden. Am Ende dieser Lektüre werden Sie verstehen, wie diese Aktivität zeigt, dass Partitionen und Cluster Abfragen beschleunigen und die Datenbankleistung optimieren.
Beachten Sie, dass die Antworten auf diese Fragen unterschiedlich sein können, je nachdem, ob Sie die Sandbox oder die kostenlose Testversion/Vollversion von BigQuery verwenden. Die Sandbox-Version liest möglicherweise nicht den vollständigen Datensatz, sodass die Tabellengröße, die Sie erhalten, möglicherweise nicht mit den Ergebnissen übereinstimmt, die Sie aus der Abfrage in der Vollversion erhalten würden. In dieser Lektüre werden die Ergebnisse sowohl für die Sandbox als auch für die Vollversion erläutert, sodass Sie Ihre Arbeit unabhängig davon überprüfen können, wie Sie BigQuery verwenden.
Entdecken Sie das Exemplar
Tabellendetails
Dies ist der Detailbereich für die Tabelle, die Sie ohne Partitionen oder Indizes erstellt haben. Es beschreibt lediglich die Tabellengröße (4,37 MB logische und aktive Bytes) und die Anzahl der Zeilen (41.025).

Dies ist der Detailbereich für die Tabelle, die Sie mit einer Partition erstellt haben. Es enthält die gleichen Details wie der erste Detailbereich, enthält jedoch auch Details zum Tabellentyp (partitioniert) sowie zum Feld, in dem die Partition erstellt wurde (Jahr).
Die Sandbox-Einschränkungen bedeuten, dass diese Tabelle keine Größe hat, aber trotzdem mit der Abfrage erstellt wird. Die Tabellengröße beträgt 0B und es gibt einen Abschnitt, der „Tabellentyp: Partitioniert“, „Partitioniert nach: Ganzzahlbereich“, „Partitioniert nach Feld: Jahr“ und „Partitionsfilter: Nicht erforderlich“ enthält. Der Beginn des Partitionsbereichs (2015), das Ende (2022) und das Intervall werden ebenfalls angezeigt. Die Vollversion hat eine Tabellengröße von 4,37 MB, verfügt aber über den gleichen zusätzlichen Partitionsabschnitt.

Dies ist der Detailbereich für die Tabelle, die Sie mit einer Partition und Clustern erstellt haben. Es enthält die gleichen Details wie die beiden vorherigen Bilder, enthält aber auch die Information, dass Sie die Daten nach der Typspalte gruppiert haben . Die Sandbox-Version der Tabelle hat möglicherweise keine Tabellengröße, aber die Vollversion verfügt über insgesamt 4,37 MB logische und aktive Bytes.

Ausführungsdetails
Anschließend vergleichen die Bereiche „Ausführungsdetails“ die Abfrageleistung für jede Tabelle. In der Sandbox werden diese Details für Abfragen zu den partitionierten und den partitionierten und geclusterten Tabellen nicht angezeigt. Wenn Sie die Sandbox verwenden, beachten Sie die Screenshots im Abschnitt.
Hinweis : Der Abschnitt „Arbeitszeit“ auf Ihrem Bildschirm kann in Farbe oder Dauer variieren. Abhängig von den unterschiedlichen Servergeschwindigkeiten der BigQuery-Engine kann die Ausführung Ihrer SQL-Abfrage länger oder kürzer dauern. Ihr Bildschirm stimmt möglicherweise nicht mit dem folgenden Screenshot überein, aber die gelesenen und geschriebenen Datensätze sollten mit dem Abschnitt „Zeilen“ übereinstimmen.
Dies ist der Bereich „Ausführungsdetails“ für die Abfrage der Tabelle, die Sie ohne Partitionen oder Cluster erstellt haben. Die Anzahl der gelesenen Zeilen ist die Gesamtzahl der Zeilen in der Tabelle. Sie finden dies im Abschnitt S00:Input, wo Datensätze lauten: 41.025 und Datensätze geschrieben: 3.

Dies ist der Bereich „Ausführungsdetails“ für die Abfrage der von Ihnen erstellten Tabelle, partitioniert durch einen Ganzzahlbereich . Sie werden feststellen, dass die Anzahl der gelesenen Datensätze geringer ist. Jetzt sind die gelesenen Datensätze 16.953 und die geschriebenen Datensätze 3. In dieser Abfrage verarbeitet die Datenbank nur die Datensätze aus den Partitionen, die durch die Where-Klausel (Typ) gefiltert wurden. Bei der Auswahl einer Spalte zur Partitionierung ist es am effektivsten, eine Spalte auszuwählen, die häufig in der where-Klausel verwendet wird.

Dies ist der Bereich „Ausführungsdetails“ für die Abfrage der von Ihnen erstellten Tabelle, die nach der Typspalte gruppiert ist . Gelesene Datensätze: 16.953 und geschriebene Datensätze: 3. Normalerweise verarbeitet eine Abfrage in der gruppierten Tabelle weniger Datensätze als in der partitionierten Tabelle. Allerdings ist der Datensatz, den Sie in dieser Aktivität verwenden, zu klein, um diesen Unterschied richtig darzustellen. In anderen Projekten stellen Sie möglicherweise fest, dass das Clustering einer Tabelle zu einem erheblichen Rückgang der gelesenen Datensätze führt.

Die zentralen Thesen
Diese Aktivität demonstriert die Auswirkungen der Verwendung von Partitionen und Indizes (in BigQuery als Cluster bezeichnet) in Datenbanktabellen. Mit ihnen können Sie die Abfrageleistung optimieren und die Verarbeitungskosten minimieren. In dieser Übung bedeutet die Anwendung von Partitionen und Clustering, dass BigQuery alle 41.025 Datensätze zum Lesen in kleinere, besser verwaltbare Tabellen aufteilen kann. Die Vorteile der Partitionierung werden bei größeren Datensätzen noch deutlicher. Nutzen Sie diese Technik, um die Datenbankleistung in Ihren zukünftigen Projekten zu optimieren.
Fallstudie: Deloitte – Optimierung veralteter Datenbanksysteme
In diesem Teil des Kurses haben Sie die Bedeutung der Datenbankoptimierung kennengelernt. Dies bedeutet im Wesentlichen, die Geschwindigkeit und Effizienz des Datenabrufs zu maximieren, um eine hohe Datenbankleistung sicherzustellen. Zu den Aufgaben eines BI-Experten gehört es, die Ressourcennutzung zu untersuchen und bessere Datenquellen und -strukturen zu identifizieren. In dieser Fallstudie haben Sie die Möglichkeit, anhand eines Beispiels zu sehen, wie das BI-Team arbeitetDeloitteDie Optimierung wurde durchgeführt, als sie feststellten, dass die Abfrage ihrer aktuellen Datenbank für Benutzer schwierig war.
Firmenhintergrund
Deloitte arbeitet mit unabhängigen Unternehmen zusammen, um ausgewählten Kunden Prüfungs- und Assurance-, Beratungs-, Risiko- und Finanzberatungs-, Risikomanagement-, Steuer- und damit verbundene Dienstleistungen anzubieten. Die Markenvision von Deloitte besteht darin, ein Maßstab für Exzellenz in der Branche zu sein und ihre Markenwerte aufrechtzuerhalten, während sie führende Strategien und modernste Tools für Kunden entwickeln, um ihr Geschäft zu erleichtern. Zu diesen Werten gehören Integrität, die Bereitstellung eines herausragenden Mehrwerts für Kunden, Engagement für die Gemeinschaft und Stärke durch kulturelle Vielfalt.
Die Herausforderung
Aufgrund der Größe des Unternehmens und seines sich ständig weiterentwickelnden Datenbedarfs wuchs und veränderte sich die Datenbank, um aktuellen Problemen gerecht zu werden, ohne Zeit für die Betrachtung der langfristigen Leistung zu haben. Aus diesem Grund wuchs die Datenbank schließlich zu einer Sammlung nicht verwalteter Tabellen ohne eindeutige Verknüpfungen oder konsistente Formatierung. Dies machte es schwierig, die Daten abzufragen und in Informationen umzuwandeln, die eine wirksame Entscheidungsfindung ermöglichen könnten.
Der Optimierungsbedarf zeigte sich nach und nach, da das Team die Daten kontinuierlich verfolgen und die Gültigkeit der Daten wiederholt testen und nachweisen musste. Mit einer neu optimierten Datenbank könnten die Daten leichter verstanden, vertrauenswürdiger und für effektive Geschäftsentscheidungen genutzt werden.
In erster Linie enthielt diese Datenbank Marketing- und Finanzdaten, die idealerweise zur Verbindung von Marketingkampagnen und Vertriebskontakten verwendet werden sollten, um zu bewerten, welche Kampagnen erfolgreich waren. Aufgrund des aktuellen Stands der Datenbank gab es jedoch keine eindeutige Möglichkeit, Erfolge bestimmten Marketingkampagnen zuzuordnen und deren finanzielle Leistung zu bewerten. Die größte Herausforderung bei dieser Initiative bestand darin, die externen Datenquellen so zu programmieren, dass sie Daten direkt in die neue Datenbank einspeisen und nicht in die vorherigen Tabellen, deren veraltete Tabelle geplant war. Darüber hinaus musste das Datenbankdesign Tabellen berücksichtigen, die den Lebenszyklus der Daten darstellen und mit Verknüpfungen ausgestattet sind, die verschiedene Datenabfragen und -anforderungen einfach und logisch unterstützen können.
Die Vorgehensweise
Aufgrund des Umfangs des Projekts und der spezifischen Anforderungen der Organisation beschloss das BI-Team, ein eigenes Datenbanksystem zu entwerfen, das es in der gesamten Organisation implementieren konnte. Auf diese Weise würde die Architektur der Datenbank ihre Datenanforderungen wirklich erfassen und Tabellen sorgfältig verbinden, sodass sie einfacher abzufragen und zu verwenden wären.
Das Team wollte beispielsweise in der Lage sein, die anfängliche Schätzung des finanziellen Erfolgs einer Marketingkampagne einfach mit ihrem Endwert in Verbindung zu bringen und herauszufinden, wie gut interne Prozesse den Erfolg einer Kampagne vorhersagen können. Die Steigerungen gegenüber der ursprünglichen Schätzung waren gut, aber wenn die Schätzungen häufig viel höher ausfielen als die tatsächlichen Ergebnisse, könnte dies auf ein Problem mit den zur Entwicklung dieser Schätzungen verwendeten Tools hinweisen. Im aktuellen Zustand der Datenbank gab es jedoch Dutzende von Tabellen in allen Buchhaltungsgruppen, die Zugriffsprobleme verursachten, die die Gewinnung dieser Erkenntnisse verhinderten. Außerdem gab es zwischen den verschiedenen Buchhaltungsgruppen viele Überschneidungen, die das Team für eine langfristigere Nutzung besser strukturieren wollte.
Um diese Ziele zu erreichen, entwickelte das Team eine Strategie für die Architektur, entwickelte Prüfpunkte, um festzustellen, ob die erforderliche Funktionalität entwickelt und schließlich skaliert werden konnte, und erstellte ein iteratives System, in dem regelmäßige Aktualisierungen des Datenbanksystems vorgenommen werden konnten, um es in Zukunft weiter zu verfeinern.
Um das Datenbankoptimierungsprojekt als Erfolg zu betrachten, wollte das BI-Team die folgenden Probleme angehen:
Wurden die notwendigen Tabellen und Spalten sinnvoller konsolidiert?
Entsprachen das neue Schema und die neuen Schlüssel den Anforderungen der Analystenteams?
Welche Tabellen wurden wiederholt abgefragt und waren sie zugänglich und logisch?
Welche Beispielabfragen könnten das Vertrauen der Benutzer in das System stärken?
In das Optimierungsprojekt mussten eine Vielzahl von Partnern und Stakeholdern einbezogen werden, da so viele Benutzer im gesamten Unternehmen betroffen wären. Die Datenbankadministratoren und -ingenieure, die mit dem BI-Team zusammenarbeiteten, waren für dieses Projekt besonders wichtig, da sie den Entwurf und die Erstellung der Datenbank leiteten, den Lebenszyklus der Daten während ihrer Reifung und Veränderung im Laufe der Zeit abbildeten und diesen als Rahmen für die Erstellung einer Datenbank nutzten logisches Datenflussdesign.
Anschließend führten diese Ingenieure Interviews mit verschiedenen Interessengruppen, um die Geschäftsanforderungen für Teams im gesamten Unternehmen zu verstehen, schulten ein Team von Analysten für das neue System und stellten die alten Tabellen, die nicht funktionierten, außer Dienst.
Die Ergebnisse
Das BI-Team von Deloitte erkannte, dass die Datenbank zwar kontinuierlich aktualisiert wurde, um den sich ändernden Geschäftsanforderungen gerecht zu werden, dass die Verwaltung jedoch mit der Zeit immer schwieriger geworden war. Um eine höhere Datenbankleistung zu fördern und sicherzustellen, dass die Datenbank ihre Anforderungen erfüllt, arbeitete das BI-Team mit Datenbankingenieuren und Administratoren zusammen, um eine benutzerdefinierte Datenbankarchitektur zu entwerfen, die sorgfältig auf die Geschäftsanforderungen des Unternehmens eingeht. Die neue Datenbankstruktur half beispielsweise beim Aufbau von Verbindungen zwischen Tabellen, die Marketingkampagnen im Zeitverlauf und deren Erfolge verfolgen, einschließlich Umsatzdaten und regionaler Standorte.
Diese Bemühungen zur Datenbankoptimierung hatten viele Vorteile. Der größte Vorteil bestand darin, dass das Unternehmen seinen Daten vertrauen konnte – das Analystenteam musste nicht so viel Zeit mit der Validierung der Daten vor der Verwendung verbringen, da die Tabellen nun logischer organisiert und verknüpft waren. Die neue Architektur förderte auch einfachere Abfragen. Anstatt Hunderte Zeilen komplizierten Codes schreiben zu müssen, um einfache Antworten zurückzugeben, wurde die neue Datenbank für einfachere, kürzere Abfragen optimiert, deren Ausführung weniger Zeit in Anspruch nahm.
Dies bot den Teams im gesamten Unternehmen Vorteile:
Das Marketingteam konnte ein besseres Feedback zum Mehrwert bestimmter Kampagnen erhalten.
Das Vertriebsteam könnte auf spezifische Informationen über seine Regionen und Territorien zugreifen und so Einblicke in mögliche Schwachstellen und Expansionsmöglichkeiten erhalten.
Das Strategieteam konnte die Lücke zwischen den Marketing- und Vertriebsteams schließen und letztendlich umsetzbare OKRs (Objectives and Key Results) für die Zukunft erstellen.
Wie Sie jedoch erfahren haben, ist die Datenbankoptimierung ein iterativer Prozess. Die Arbeit des BI-Teams endete nicht mit der Implementierung des neuen Datenbankdesigns. Sie haben außerdem ein Team benannt, das die Datenverwaltung überwacht, um die Qualität der Daten sicherzustellen und zu verhindern, dass dieselben Probleme erneut auftreten. Auf diese Weise bleiben die Daten organisiert und auch dieses Team kann die entwickelten Datenbanken basierend auf sich entwickelnden Geschäftsanforderungen weiter verfeinern.
Abschluss
Die Datenbanken, in denen Ihr Unternehmen seine Daten speichert, sind ein wichtiger Bestandteil der von Ihnen erstellten BI-Prozesse und -Tools. Wenn die Datenbank nicht gut funktioniert, wirkt sich das auf Ihr gesamtes Unternehmen aus und macht es schwieriger, Stakeholder mit den benötigten Daten zu versorgen Treffen Sie intelligente Geschäftsentscheidungen. Die Optimierung Ihrer Datenbank fördert eine hohe Leistung und ein besseres Benutzererlebnis für alle Mitglieder Ihres Teams.
Bestimmen Sie die effizienteste Abfrage
Bisher haben Sie die Faktoren kennengelernt, die die Datenbankleistung und die Optimierung von Datenbankabfragen beeinflussen. Dies ist ein wichtiger Teil der Arbeit eines BI-Experten, da er so sicherstellen kann, dass die von seinem Team verwendeten Tools und Systeme so effizient wie möglich sind. Da Sie nun mit diesen Konzepten besser vertraut sind, sehen Sie sich ein Beispiel an.
Das Szenario
Francisco’s Electronics hat kürzlich seine Home-Office-Produktlinie auf seiner E-Commerce-Website eingeführt. Nachdem sie eine positive Resonanz von den Kunden erhalten hatten, entschieden sich die Entscheidungsträger des Unternehmens, den Rest ihrer Produkte auf der Website hinzuzufügen. Seit ihrer Einführung wurden mehr als 10.000.000 Exemplare verkauft. Das ist zwar großartig für das Unternehmen, aber ein derart umfangreicher Katalog an Verkaufsunterlagen hat sich auf die Geschwindigkeit der Datenbank ausgewirkt. Der Vertriebsleiter Ed wollte eine Abfrage nach der Anzahl der nach dem 1. November 2021 getätigten Verkäufe in der Kategorie „Elektronik“ durchführen, konnte dies jedoch nicht, da die Datenbank zu langsam war. Er bat Xavier, einen BI-Analysten, mit der Datenbank zu arbeiten und eine Abfrage zu optimieren, um die Erstellung des Verkaufsberichts zu beschleunigen.
Zunächst untersuchte Xavier das unten gezeigte Datenbankschema „ sales_warehouse“ . Das Schema enthält verschiedene Symbole und Konnektoren, die zwei wichtige Informationen darstellen: die Haupttabellen innerhalb des Systems und die Beziehungen zwischen diesen Tabellen.

Das Datenbankschema „ sales_warehouse“ enthält fünf Tabellen – „Sales“, „Products“, „Users“, „Locations“ und „Orders“ –, die über Schlüssel verbunden sind. Die Tabellen enthalten fünf bis acht Spalten (oder Attribute) unterschiedlicher Datentypen. Zu den Datentypen gehören Varchar oder Char (oder Zeichen), Ganzzahl, Dezimalzahl, Datum, Text (oder Zeichenfolge), Zeitstempel und Bit.
Die Fremdschlüssel in der Sales-Tabelle sind mit jeder der anderen Tabellen verknüpft. Der Fremdschlüssel „product_id“ ist mit der Tabelle „Products“ verknüpft, der Fremdschlüssel „user_id“ ist mit der Tabelle „Users“ verknüpft, der Fremdschlüssel „order_id“ ist mit der Tabelle „Orders“ verknüpft und die Fremdschlüssel „shipping_address_id“ und „billing_address_id“ sind mit der Tabelle verknüpft Standorttabelle.
Untersuchen der SQL-Abfrage
Nach Prüfung der Details stellte Xavier fest, dass die folgende Anfrage optimiert werden musste:

Optimierung der Abfrage
Um diese Abfrage effizienter zu gestalten, prüfte Xavier zunächst, ob die Felder „Datum“ und „Kategorie“ indiziert waren. Er tat dies, indem er die folgenden Abfragen ausführte:

Ohne Indizes in den für Abfragebeschränkungen verwendeten Spalten führte die Engine einen vollständigen Tabellenscan durch, der alle mehreren Millionen Datensätze verarbeitete und überprüfte, welche das Datum >= „2021-11-01“ und die Kategorie = „Elektronik“ hatten.
Anschließend indizierte er das Feld „Datum“ in der Tabelle „Verkäufe“ und das Feld „Kategorie“ in der Tabelle „Produkte“ mithilfe des folgenden SQL-Codes:

Leider war die Abfrage auch nach dem Hinzufügen der Indizes immer noch langsam. Unter der Annahme, dass nach dem „01.11.2021“ nur ein paar Tausend Verkäufe getätigt wurden, erstellte die Abfrage immer noch eine sehr große virtuelle Tabelle (die Verkäufe und Produkte verbindet). Es verfügte über Millionen von Datensätzen, bevor Verkäufe mit einem Datum nach dem „01.11.2021“ und Verkäufe mit Produkten in der Kategorie „Elektronik“ herausgefiltert wurden. Dies führte zu einer ineffizienten und langsamen Abfrage.
Um die Abfrage schneller und effizienter zu gestalten, hat Xavier sie so geändert, dass zunächst die Verkäufe herausgefiltert werden, deren Datum nach dem „01.11.2021“ liegt. Die Abfrage „( SELECT product_id FROM Sales WHERE date > ‚2021-11-01‘) AS oi“ lieferte nur ein paar tausend Datensätze und nicht Millionen von Datensätzen. Anschließend verknüpfte er diese Datensätze mit der Tabelle „Products“.
Xaviers letzte optimierte Abfrage war:

Die zentralen Thesen
Durch die Optimierung von Abfragen werden Ihre Pipeline-Abläufe schneller und effizienter. In Ihrer Rolle als BI-Experte arbeiten Sie möglicherweise an Projekten mit extrem großen Datenmengen. Für diese Projekte ist es wichtig, SQL-Abfragen so schnell und effizient wie möglich zu schreiben. Andernfalls könnten Ihre Datenpipelines langsam und schwierig zu handhaben sein.
Sieben Elemente der Qualitätsprüfung
In diesem Teil des Kurses haben Sie die Bedeutung von Qualitätstests in Ihrem ETL-System kennengelernt. Hierbei werden Daten auf Fehler überprüft, um Systemausfällen vorzubeugen. Idealerweise sollte Ihre Pipeline über integrierte Prüfpunkte verfügen, die etwaige Fehler identifizieren, bevor sie im Zieldatenbanksystem ankommen. Diese Prüfpunkte stellen sicher, dass die eingehenden Daten bereits sauber und nützlich sind! In dieser Lektüre erhalten Sie eine Checkliste dafür, was bei Ihren ETL-Qualitätstests berücksichtigt werden sollte.

Bei der Überprüfung der Datenqualität geht es darum, sicherzustellen, dass die Daten vertrauenswürdig sind, bevor sie ihr Ziel erreichen. Bei der Überlegung, welche Prüfungen Sie benötigen, um die Qualität Ihrer Daten auf ihrem Weg durch die Pipeline sicherzustellen, sollten Sie sieben Elemente berücksichtigen:
Vollständigkeit: Enthalten die Daten alle gewünschten Komponenten oder Maßnahmen?
Konsistenz: Sind die Daten systemübergreifend kompatibel und übereinstimmend?
Konformität: Passen die Daten zum erforderlichen Zielformat?
Genauigkeit: Entsprechen die Daten dem tatsächlich gemessenen oder beschriebenen Objekt?
Redundanz: Werden nur die notwendigen Daten zur Verwendung verschoben, umgewandelt und gespeichert?
Aktualität: Sind die Daten aktuell?
Integrität: Sind die Daten korrekt, vollständig, konsistent und vertrauenswürdig? (Die Integrität wird durch die zuvor genannten Qualitäten beeinflusst.) Quantitative Validierungen, einschließlich der Prüfung auf Duplikate, der Anzahl der Datensätze und der aufgelisteten Mengen, tragen dazu bei, die Integrität der Daten sicherzustellen.
Häufige Probleme
Es gibt auch einige allgemeine Probleme, vor denen Sie sich in Ihrem System schützen können, um sicherzustellen, dass die eingehenden Daten keine Fehler oder andere große Probleme in Ihrem Datenbanksystem verursachen:
Datenzuordnung prüfen: Stimmen die Daten aus der Quelle mit den Daten in der Zieldatenbank überein?
Auf Inkonsistenzen prüfen: Gibt es Inkonsistenzen zwischen Quellsystem und Zielsystem?
Auf ungenaue Daten prüfen: Sind die Daten korrekt und spiegeln sie das tatsächlich gemessene Objekt wider?
Auf doppelte Daten prüfen: Existieren diese Daten bereits im Zielsystem?
Um diese Probleme anzugehen und sicherzustellen, dass Ihre Daten alle sieben Elemente der Qualitätsprüfung erfüllen, können Sie Zwischenschritte in Ihre Pipeline einbauen, die die geladenen Daten anhand bekannter Parameter prüfen. Um beispielsweise die Aktualität der Daten sicherzustellen, können Sie einen Prüfpunkt hinzufügen, der feststellt, ob diese Daten mit dem aktuellen Datum übereinstimmen. Wenn die eingehenden Daten diese Prüfung nicht bestehen, liegt im Upstream ein Problem vor, das gemeldet werden muss. Wenn Sie diese Prüfungen in Ihrem Designprozess berücksichtigen, stellen Sie sicher, dass Ihre Pipeline qualitativ hochwertige Daten liefert und im Laufe der Zeit weniger Wartung benötigt.
Die zentralen Thesen
Eines der großartigen Dinge an BI ist, dass es uns die Werkzeuge an die Hand gibt, um bestimmte Prozesse zu automatisieren, die dabei helfen, Zeit und Ressourcen bei der Datenanalyse zu sparen – die Integration von Qualitätsprüfungen in Ihr ETL-Pipeline-System ist eine der Möglichkeiten, dies zu erreichen! Wenn Sie sicherstellen, dass Sie bereits die Vollständigkeit, Konsistenz, Konformität, Genauigkeit, Redundanz, Integrität und Aktualität der Daten berücksichtigen, wenn diese von einem System in ein anderes übertragen werden, bedeutet dies, dass Sie und Ihr Team die Daten später nicht manuell überprüfen müssen.
Überwachen Sie die Datenqualität mit SQL
Wie Sie gelernt haben, ist es wichtig, die Datenqualität zu überwachen. Durch die Überwachung Ihrer Daten werden Sie auf Probleme aufmerksam, die innerhalb der ETL-Pipeline und des Data Warehouse-Designs auftreten können. Dies kann Ihnen helfen, Probleme so früh wie möglich anzugehen und zukünftige Probleme zu vermeiden.
In dieser Lektüre verfolgen Sie ein fiktives Szenario, in dem ein BI-Ingenieur Qualitätstests für seine Pipeline durchführt und SQL-Abfragen vorschlägt, die man für jeden Testschritt verwenden könnte.
Das Szenario
Bei Francisco’s Electronics, einem Elektronikhersteller, entwarf ein BI-Ingenieur namens Sage ein Data Warehouse für Analysen und Berichte. Nach dem ETL-Prozessdesign erstellte Sage ein Diagramm des Schemas.

Das Diagramm des Schemas der sales_warehouse- Datenbank enthält verschiedene Symbole und Konnektoren, die zwei wichtige Informationen darstellen: die Haupttabellen innerhalb des Systems und die Beziehungen zwischen diesen Tabellen.
Das Datenbankschema „sales_warehouse“ enthält fünf Tabellen:
Verkäufe
Produkte
Benutzer
Standorte
Aufträge
Diese Tabellen sind über Schlüssel verbunden. Die Tabellen enthalten fünf bis acht Spalten (oder Attribute) unterschiedlicher Datentypen. Zu den Datentypen gehören Varchar oder Char (oder Zeichen), Ganzzahl, Dezimalzahl, Datum, Text (oder Zeichenfolge), Zeitstempel und Bit.
Die Fremdschlüssel in der Tabelle „Sales“ sind mit jeder der anderen Tabellen verknüpft:
Der Fremdschlüssel „product_id“ ist mit der Tabelle „Products“ verknüpft
Der Fremdschlüssel „user_id“ ist mit der Benutzertabelle verknüpft
Der Fremdschlüssel „order_id“ ist mit der Orders-Tabelle verknüpft
Die Fremdschlüssel „shipping_address_id“ und „billing_address_id“ sind mit der Tabelle „Locations“ verknüpft
Nachdem Sage die sales_warehouse- Datenbank erstellt hatte, nahm das Entwicklungsteam Änderungen an der Vertriebsseite vor. Dadurch wurde die ursprüngliche OLTP-Datenbank geändert. Jetzt muss Sage sicherstellen, dass die ETL-Pipeline ordnungsgemäß funktioniert und dass die Warehouse-Daten mit der ursprünglichen OLTP-Datenbank übereinstimmen.
Sage verwendete das ursprüngliche OLTP-Schema aus der Filialdatenbank , um das Lager zu entwerfen.

Das Filialdatenbankschema enthält außerdem fünf Tabellen – Verkäufe, Produkte, Benutzer, Standorte und Bestellungen – die über Schlüssel verbunden sind. Die Tabellen enthalten vier bis acht Spalten unterschiedlicher Datentypen. Zu den Datentypen gehören Varchar oder Char, Integer, Dezimalzahl, Datum, Text, Zeitstempel, Bit, Tinyint und Datetime.
Jede Tabelle in der Geschäftsdatenbank verfügt über ein ID- Feld als Primärschlüssel. Die Datenbank enthält die folgenden Tabellen:
Die Verkaufstabelle enthält Preis-, Mengen- und Datumsspalten. Es verweist auf einen Benutzer, der einen Verkauf getätigt hat ( UserId ), ein Produkt gekauft hat ( ProductId ) und eine zugehörige Bestellung durchgeführt hat ( OrderId ). Außerdem verweist es auf die Tabelle „Standorte“ für Versand- und Rechnungsadressen ( ShippingAddressId bzw. BillingAddressId ).
Die Benutzertabelle enthält FirstName , LastName , Email , Password und andere benutzerbezogene Spalten.
Die Standorttabelle enthält Adressinformationen ( Address1 , Address2 , City , State und Postcode ).
Die Produkttabelle enthält Name , Preis , Inventarnummer und Kategorie der Produkte.
Die Orders- Tabelle enthält OrderNumber und Kaufinformationen ( Subtotal , ShippingFee , Tax , Total und Status ).
Mit SQL Probleme finden
Sage verglich die sales_warehouse- Datenbank mit der ursprünglichen Filialdatenbank , um Vollständigkeit, Konsistenz, Konformität, Genauigkeit, Redundanz, Integrität und Aktualität zu prüfen. Sage führte SQL-Abfragen durch, um die Daten zu untersuchen und Qualitätsprobleme zu identifizieren. Anschließend erstellte Sage die folgende Listentabelle, die die Arten der gefundenen Qualitätsprobleme, die verletzten Qualitätsstrategien, die zum Auffinden der Probleme verwendeten SQL-Codes und spezifische Beschreibungen der Probleme enthält.
Qualitätsprüfung sales_warehouse
Geprüfte Qualität | Qualitätsstrategie | SQL-Abfrage | Sages Beobachtung |
|---|---|---|---|
Integrität | Sind die Daten korrekt, vollständig, konsistent und vertrauenswürdig? | WÄHLEN Sie * AUS Bestellungen | In der Datenbank sales_warehouse weist die Bestellung mit der ID 7 den falschen Gesamtwert auf. |
Vollständigkeit | Enthalten die Daten alle gewünschten Komponenten oder Maßnahmen? | WÄHLEN SIE COUNT(*) FROM Locations | Die Tabelle „Locations“ der Datenbank „sales_warehouse“ verfügt über eine zusätzliche Adresse. In der Filialdatenbank gibt es 60 Datensätze, während die Datenbanktabelle sales_warehouse 61 enthält. |
Konsistenz | Sind die Daten systemübergreifend kompatibel und übereinstimmend? | Wählen Sie „Telefon unter Benutzern“ aus | Mehrere Benutzer in der sales_warehouse -Datenbank haben Telefone ohne das Präfix „+“. |
Konformität | Passen die Daten in das erforderliche Zielformat? | WÄHLEN Sie ID und Postleitzahl AUS sales_warehouse.Locations | Die Postleitzahl des Standorts für den Datensatz mit der ID 6 in der Datenbank sales_warehouse lautet 722434213, was falsch ist. Die Postleitzahl der Vereinigten Staaten besteht entweder aus fünf Ziffern oder aus fünf Ziffern, gefolgt von einem Bindestrich (Bindestrich) und weiteren vier Ziffern (z. B. 12345-1234). |
Laden für Qualitätsprüfungen
Besonderheit | Qualitätsstrategie | SQL-Abfrage | Beobachtung des Weisen |
|---|---|---|---|
Integrität | Sind die Daten korrekt, vollständig, konsistent und vertrauenswürdig? | BESCHREIBEN Sie Benutzer | Users.Status aus der Store -Datenbank und Users.is_active aus der sales_warehouse -Datenbank scheinen verwandte Felder zu sein. Es ist jedoch nicht offensichtlich, wie die Spalte „Status“ in die boolesche Spalte „is_active“ umgewandelt wird . Ist es möglich, dass die ETL-Pipeline bei einem neuen Statuswert ausfällt? |
Konsistenz | Sind die Daten systemübergreifend kompatibel und übereinstimmend? | Produkte BESCHREIBEN | Products.Inventory aus der Filialdatenbank hat den Typ varchar anstelle von int(10) im Feld Products.inventory der sales_warehouse -Datenbank . Dies kann ein Problem sein, wenn ein Wert mit Zeichen vorhanden ist. |
Genauigkeit | Entsprechen die Daten dem tatsächlich gemessenen oder beschriebenen Objekt? | BESCHREIBEN Sie Verkäufe | Der Datentyp von Sales.Date in der Filialdatenbank unterscheidet sich von seinem Datentyp in sales_warehouse ( date vs. datetime ). Es stellt möglicherweise kein Problem dar, wenn die Zeit für die Faktentabelle der Datenbank „sales_warehouse“ keine Rolle spielt. |
Redundanz | Werden nur die notwendigen Daten zur Verwendung verschoben, umgewandelt und gespeichert? | BESCHREIBEN Sie Verkäufe | Die Tabelle „ Sales“ aus der Datenbank „sales_warehouse“ weist eine eindeutige Indexbeschränkung für die Spalten „OrderId “ , „ProductId“ und „UserId“ auf . Es kann dem Warehouse-Schema hinzugefügt werden. |
Die zentralen Thesen
Das Testen der Datenqualität ist eine wesentliche Fähigkeit eines BI-Experten, die gute Analysen und Berichte gewährleistet. Genau wie Sage in diesem Beispiel können Sie SQL-Befehle verwenden, um BI-Datenbanken zu untersuchen und potenzielle Probleme zu finden. Je früher Sie die Probleme in Ihrem System kennen, desto eher können Sie diese beheben und Ihre Datenqualität verbessern.
Beispieldatenwörterbuch und Datenherkunft
Wie Sie in diesem Kurs erfahren haben, verfügen Business-Intelligence-Experten über drei Haupttools, mit denen sie die Konformität von der Quelle bis zum Ziel sicherstellen können: Schemavalidierung, Datenwörterbücher und Datenherkunft. In dieser Lektüre werden Sie einige Beispiele für Datenwörterbücher und -linien untersuchen, um besser zu verstehen, wie diese Elemente funktionieren.
Datenwörterbücher
Ein Datenwörterbuch ist eine Sammlung von Informationen, die den Inhalt, das Format und die Struktur von Datenobjekten innerhalb einer Datenbank sowie deren Beziehungen beschreiben. Dies kann auch als Metadaten-Repository bezeichnet werden, da Datenwörterbücher Metadaten verwenden, um die Verwendung und Herkunft anderer Datenelemente zu definieren. Hier ist ein Beispiel für eine Produkttabelle, die in einer Verkaufsdatenbank vorhanden ist:
Produkttabelle
Artikel Identifikationsnummer | Preis | Abteilung | Anzahl_der_Verkäufe | Number_in_Stock | Saisonal |
|---|---|---|---|---|---|
47257 | 33,00 $ | Gartenarbeit | 744 | 598 | Ja |
39496 | 82,00 $ | Wohnkultur | 383 | 729 | Ja |
73302 | 56,00 $ | Möbel | 874 | 193 | NEIN |
16507 | 100,00 $ | Heimbüro | 310 | 559 | Ja |
1232 | 125,00 $ | Partyzubehör | 351 | 517 | NEIN |
3412 | 45,00 $ | Gartenarbeit | 901 | 942 | NEIN |
54228 | 60,00 $ | Partyzubehör | 139 | 520 | NEIN |
66415 | 38,00 $ | Wohnkultur | 615 | 433 | Ja |
78736 | 12,00 $ | Lebensmittelgeschäft | 739 | 648 | NEIN |
34369 | 28,00 $ | Gartenarbeit | 555 | 389 | Ja |
Diese Tabelle ist eigentlich die endgültige Zieltabelle für Daten, die aus mehreren Quellen gesammelt wurden. Es ist wichtig, die Konsistenz von den Quellen bis zum Ziel sicherzustellen, da diese Daten von verschiedenen Stellen im System stammen. Hier kommt das Datenwörterbuch ins Spiel:
Datenwörterbuch
Name | Definition | Datentyp |
|---|---|---|
Artikel Identifikationsnummer | ID-Nummer, die allen Produktartikeln im Geschäft zugewiesen wird | Ganze Zahl |
Preis | Aktueller Preis des Produktartikels | Ganze Zahl |
Abteilung | Zu welcher Abteilung der Produktartikel gehört | Charakter |
Anzahl_der_Verkäufe | Die aktuelle Anzahl der verkauften Produktartikel | Ganze Zahl |
Number_in_Stock | Die aktuelle Anzahl der Produktartikel auf Lager | Ganze Zahl |
Saisonal | Ob der Produktartikel nur saisonal verfügbar ist oder nicht | Boolescher Wert |
Sie können die im Wörterbuch beschriebenen Eigenschaften verwenden, um eingehende Daten mit der Zieltabelle zu vergleichen. Wenn Datenobjekte nicht mit den Einträgen im Wörterbuch übereinstimmen, wird die Datenvalidierung den Fehler melden, bevor die falschen Daten erfasst werden.
Wenn beispielsweise eingehende Daten, die an die Spalte „Abteilung“ übermittelt werden, numerische Daten enthalten, können Sie vor der Zustellung schnell erkennen, dass ein Fehler aufgetreten ist, da im Datenwörterbuch angegeben ist, dass die Abteilungsdaten zeichenartig sein sollten.
Datenherkunft
Eine Datenherkunft beschreibt den Prozess der Identifizierung des Ursprungs von Daten, ihres Verlaufs im System und der Art und Weise, wie sie sich im Laufe der Zeit verändert haben. Dies kann für BI-Experten sehr hilfreich sein, denn wenn sie auf einen Fehler stoßen, können sie ihn mithilfe der Herkunft tatsächlich bis zur Quelle zurückverfolgen. Anschließend können sie Kontrollen durchführen, um zu verhindern, dass dasselbe Problem erneut auftritt.
Stellen Sie sich beispielsweise vor, dass Ihr System bei eingehenden Daten über die Anzahl der Verkäufe für einen bestimmten Artikel einen Fehler gemeldet hat. Es kann schwierig sein, herauszufinden, wo dieser Fehler aufgetreten ist, wenn Sie die Herkunft dieses bestimmten Datenelements nicht kennen. Wenn Sie jedoch den Pfad dieser Daten durch Ihr System verfolgen, können Sie herausfinden, wo eine Überprüfung erstellt werden muss.

Indem Sie die Verkaufsdaten über ihren gesamten Lebenszyklus im System verfolgen, stellen Sie fest, dass ein Problem mit der ursprünglichen Datenbank vorliegt, aus der sie stammen, und dass die Daten transformiert werden müssen, bevor sie in spätere Tabellen aufgenommen werden.
Die zentralen Thesen
Tools wie Datenwörterbücher und Datenherkunftsverzeichnisse sind nützlich, um Inkonsistenzen zu verhindern, wenn Daten von Quellsystemen zu ihrem endgültigen Ziel verschoben werden. Es ist wichtig, dass Benutzer, die auf diese Daten zugreifen und sie verwenden, darauf vertrauen können, dass diese korrekt und konsistent sind. Diese Tools verfolgen und validieren Daten während ihrer gesamten Reise aktiv und stellen so sicher, dass sie für die Analyse und Entscheidungsfindung zuverlässig sind. Dies ist der Schlüssel zum Aufbau vertrauenswürdiger Berichte und Dashboards als BI-Experte!
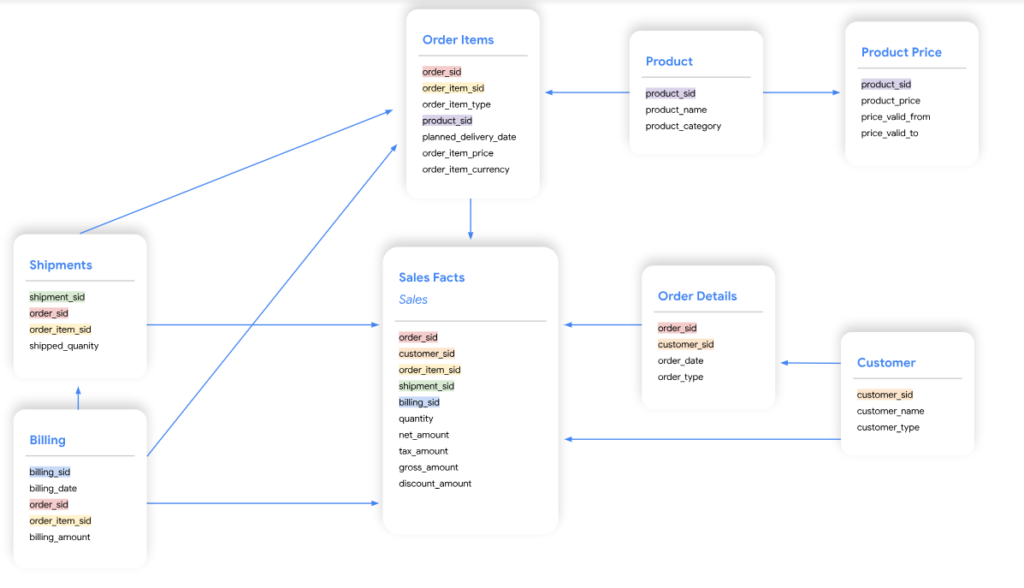
Geschäftsregeln
Wie Sie gelernt haben, ist eine Geschäftsregel eine Anweisung, die eine Einschränkung für bestimmte Teile einer Datenbank erstellt. Diese Regeln werden entsprechend der Art und Weise entwickelt, wie eine Organisation Daten verwendet. Darüber hinaus sorgen die Regeln für Effizienzsteigerungen, ermöglichen wichtige Kontrollen und veranschaulichen manchmal auch die Werte eines Unternehmens in der Praxis. Wenn ein Unternehmen beispielsweise Wert auf funktionsübergreifende Zusammenarbeit legt, kann es Regeln geben, wonach mindestens zwei Vertreter zweier Teams die Fertigstellung eines Datensatzes abhaken müssen. Sie beeinflussen, welche Daten erfasst und gespeichert werden, wie Beziehungen definiert werden, welche Art von Informationen die Datenbank bereitstellt und wie sicher die Daten sind. In dieser Lektüre erfahren Sie mehr über die Entwicklung von Geschäftsregeln und sehen ein Beispiel für die Implementierung von Geschäftsregeln in einem Datenbanksystem.
Durchsetzung von Geschäftsregeln
Geschäftsregeln hängen stark von der Organisation und ihren Datenanforderungen ab. Das bedeutet, dass die Geschäftsregeln für jede Organisation unterschiedlich sind. Dies ist einer der Gründe, warum die Überprüfung von Geschäftsregeln so wichtig ist; Diese Prüfungen helfen sicherzustellen, dass die Datenbank tatsächlich die von ihr benötigte Aufgabe erfüllt. Aber bevor Sie Geschäftsregeln überprüfen können, müssen Sie sie implementieren.
Angenommen, das Unternehmen, für das Sie arbeiten, verfügt über eine Datenbank, in der die von Mitarbeitern eingegebenen Bestellanfragen verwaltet werden. Bestellungen über 1.000 US-Dollar bedürfen der Genehmigung durch den Manager. Um diesen Prozess zu automatisieren, können Sie der Datenbank einen Regelsatz auferlegen, der Anfragen über 1.000 US-Dollar automatisch an eine Berichtstabelle übermittelt, bis die Genehmigung durch den Manager vorliegt. Weitere Geschäftsregeln, die in diesem Beispiel gelten können, sind: Preise müssen numerische Werte sein (der Datentyp sollte eine Ganzzahl sein); Damit eine Anfrage existiert, ist ein Grund zwingend erforderlich (das Tabellenfeld darf nicht null sein).

Um diese Geschäftsanforderung zu erfüllen, gibt es in diesem System drei Regeln:
Bestellanfragen unter 1.000 US-Dollar werden automatisch an die Tabelle mit den genehmigten Produktbestellanfragen übermittelt
Anfragen über 1.000 US-Dollar werden automatisch an die Tabelle „Anfragen mit ausstehender Genehmigung“ übermittelt
Genehmigte Anfragen werden automatisch an die Tabelle mit den genehmigten Produktbestellanfragen übermittelt
Diese Regeln wirken sich grundsätzlich auf die Form dieses Datenbanksystems aus, um den Anforderungen dieser bestimmten Organisation gerecht zu werden.
Geschäftsregeln überprüfen
Sobald die Geschäftsregeln implementiert wurden, ist es wichtig, weiterhin zu überprüfen, ob sie ordnungsgemäß funktionieren und ob die in die Zielsysteme importierten Daten diesen Regeln entsprechen. Diese Prüfungen sind wichtig, da sie testen, ob das System die Aufgabe erfüllt, die es erfüllen muss, d. h. in diesem Fall die Zustellung von Produktbestellanfragen, die einer Genehmigung bedürfen, an die richtigen Beteiligten.
Die zentralen Thesen
Geschäftsregeln legen fest, welche Daten erfasst und gespeichert werden, wie Beziehungen definiert werden, welche Art von Informationen die Datenbank bereitstellt und wie sicher die Daten sind. Diese Regeln haben großen Einfluss darauf, wie eine Datenbank gestaltet ist und wie sie nach der Einrichtung funktioniert. Als BI-Experte ist es hilfreich, Geschäftsregeln zu verstehen und zu verstehen, warum sie wichtig sind, da dies Ihnen helfen kann, die Funktionsweise bestehender Datenbanksysteme zu verstehen, neue Systeme entsprechend den Geschäftsanforderungen zu entwerfen und sie so zu warten, dass sie in Zukunft nützlich sind.
Schützen Sie sich vor bekannten Problemen
In dieser Lektüre erfahren Sie mehr über eine Abwehrprüfung, die auf eine Datenpipeline angewendet wird. Defensive Checks helfen Ihnen, Probleme in Ihrer Datenpipeline zu verhindern. Sie ähneln Leistungsprüfungen, konzentrieren sich jedoch auf andere Arten von Problemen. Das folgende Szenario ist ein Beispiel dafür, wie Sie verschiedene Arten von Abwehrprüfungen für eine Datenpipeline implementieren können.
Szenario
Arsha, Business Intelligence Analyst bei einem Telekommunikationsunternehmen, baute eine Datenpipeline auf, die Daten aus sechs Quellen in einer einzigen Datenbank zusammenführt. Beim Aufbau ihrer Pipeline integrierte sie mehrere Abwehrkontrollen, die sicherstellten, dass die Daten ordnungsgemäß verschoben und transformiert wurden.
Ihre Datenpipeline nutzte die folgenden Quellsysteme:
Kundendetails
Mobilfunkverträge
Internet- und Kabelverträge
Geräteverfolgung und -aktivierung
Abrechnung
Buchhaltung
Alle diese Datensätze mussten harmonisiert und in einem Zielsystem für Business-Intelligence-Analysen zusammengeführt werden. Dieser Prozess erforderte mehrere Ebenen der Datenharmonisierung, Validierung, Abstimmung und Fehlerbehandlung.
Pipeline-Schichten
Pipelines können viele verschiedene Verarbeitungsstufen haben. Diese Stufen oder Schichten tragen dazu bei, dass die Daten auf die effektivste und effizienteste Weise gesammelt, aggregiert, transformiert und bereitgestellt werden. Es ist beispielsweise wichtig, sicherzustellen, dass Sie alle benötigten Daten an einem Ort haben, bevor Sie mit der Bereinigung beginnen, um sicherzustellen, dass Ihnen nichts entgeht. Dieser Prozess besteht normalerweise aus vier Ebenen: Inszenierung, Harmonisierung, Validierung und Versöhnung. Nach diesen vier Schichten werden die Daten in ihre Zieldatenbank übertragen und ein Fehlerbehandlungsbericht fasst jeden Schritt des Prozesses zusammen.

Staging-Ebene
Zunächst werden die Originaldaten aus den Quellsystemen geholt und im Staging-Layer gespeichert . In dieser Schicht führte Arsha die folgenden Verteidigungskontrollen durch:
Verglichen wird die Anzahl der empfangenen und gespeicherten Datensätze
Verglichene Zeilen, um festzustellen, ob zusätzliche Datensätze erstellt wurden oder Datensätze verloren gingen
Wichtige Felder wie Beträge, Daten und IDs überprüft
Arsha hat die nicht übereinstimmenden Datensätze in den Fehlerbehandlungsbericht verschoben. Sie fügte für jeden nicht konvertierten Quelldatensatz das Datum und die Uhrzeit seiner ersten Verarbeitung, das Datum und die Uhrzeit seines letzten Wiederholungsversuchs, die Ebene, auf der der Fehler aufgetreten ist, und eine Meldung mit einer Beschreibung des Fehlers hinzu. Durch das Sammeln dieser Aufzeichnungen konnte Arsha den Ursprung der Probleme finden und beheben. Sie markierte alle Datensätze, die in die nächste Ebene verschoben wurden, als „verarbeitet“.
Harmonisierungsschicht
Auf der Harmonisierungsschicht werden Datennormalisierungsroutinen und Datensatzanreicherung durchgeführt. Dadurch wird sichergestellt, dass die Datenformatierung in allen Quellen konsistent ist. Um die Daten zu harmonisieren, führte Arsha die folgenden Abwehrprüfungen durch:
Das Datumsformat wurde standardisiert
Die Währung wurde standardisiert
Standardisierte Groß- und Kleinschreibung
Formatierte IDs mit führenden Nullen
Teilen Sie Datumswerte auf, um Jahr, Monat und Tag in separaten Spalten zu speichern
Angewandte Konvertierungs- und Prioritätsregeln aus den Quellsystemen
Wenn ein Datensatz nicht harmonisiert werden konnte, verschob sie ihn in die Fehlerbehandlung. Sie markierte alle Datensätze, die in die nächste Ebene verschoben wurden, als „verarbeitet“.
Validierungsschicht
Auf der Validierungsebene werden Geschäftsregeln validiert. Zur Erinnerung: Eine Geschäftsregel ist eine Anweisung, die eine Einschränkung für bestimmte Teile einer Datenbank erstellt. Diese Regeln werden entsprechend der Art und Weise entwickelt, wie eine Organisation Daten verwendet. Arsha führte die folgenden Defensivchecks durch:
Es wurde sichergestellt, dass die Werte in der Spalte „Abteilung“ nicht null sind, da „Abteilung“ eine entscheidende Dimension ist
Es wurde sichergestellt, dass die Werte in der Spalte „Diensttyp“ innerhalb der zulässigen Werte zur Verarbeitung liegen
Es wurde sichergestellt, dass jeder Abrechnungsdatensatz einem gültigen verarbeiteten Vertrag entsprach
Wenn ein Datensatz erneut nicht validiert werden konnte, verschob sie ihn in die Fehlerbehandlung. Sie markierte alle Datensätze, die in die nächste Ebene verschoben wurden, als „verarbeitet“.
Versöhnungsschicht
Auf der Abgleichsebene werden doppelte oder unzulässige Datensätze gefunden. Hier führte Arsha defensive Überprüfungen durch, um die folgenden Arten von Datensätzen zu finden:
Sich langsam ändernde Dimensionen
Historische Aufzeichnungen
Aggregationen
Wie bei den vorherigen Ebenen hat Arsha die Datensätze, die die Abgleichsregeln nicht bestanden haben, in die Fehlerbehandlung verschoben. Nach dieser Runde defensiver Kontrollen brachte sie die verarbeiteten Datensätze in die BI- und Analytics-Datenbank (OLAP).
Fehlerbehandlung, Berichterstattung und Analyse
Nachdem die Pipeline fertiggestellt und die Abwehrprüfungen durchgeführt worden waren, erstellte Arsha einen Fehlerbehandlungsbericht, um den Prozess zusammenzufassen. Der Bericht listete die Anzahl der Datensätze aus den Quellsystemen sowie die Anzahl der Datensätze auf, die in jeder Ebene als Fehler markiert oder ignoriert wurden. Am Ende des Berichts ist die endgültige Anzahl der verarbeiteten Datensätze aufgeführt.

Die zentralen Thesen
Defensive Kontrollen stellen sicher, dass eine Datenpipeline ihre Daten ordnungsgemäß verarbeitet. Defensive Kontrollen sind ein wesentlicher Bestandteil der Wahrung der Datenintegrität. Sobald die Staging-, Harmonisierungs-, Validierungs- und Abstimmungsebenen überprüft wurden, können die in die Zieldatenbank übernommenen Daten in einer Visualisierung verwendet werden.
Fallstudie: FeatureBase, Teil 2: Alternative Lösungen für Pipelinesysteme
Diese Fallstudie mit FeatureBase konzentriert sich auf die Analysephase des BI-Prozesses, in der Sie Beziehungen in den Daten untersuchen, Schlussfolgerungen ziehen, Vorhersagen treffen und fundierte Entscheidungen treffen. Dies folgt einer früheren Fallstudie, in der Sie die Capture-Phase des FeatureBase-Projekts untersucht haben. In einer anschließenden Fallstudie erfahren Sie, wie FeatureBase die Monitor-Phasen dieses Projekts angegangen ist, um sein Geschäftsproblem zu lösen. Wie in der vorherigen FeatureBase-Fallstudie betrachten Sie das Problem, den Prozess und die Lösung für diese Phase des Projekts.

In einer früheren Lektüre wurde Ihnen FeatureBase, das OLAP-Datenbankunternehmen, vorgestellt. Für eine schnelle Auffrischung können Sie eine Rezension lesenTeil eins dieser Fallstudie. Ihre Kerntechnologie, FeatureBase, ist die erste OLAP-Datenbank, die vollständig auf Bitmaps basiert und Echtzeitanalysen und Anwendungen für maschinelles Lernen ermöglicht, indem sie gleichzeitig niedrige Latenz, hohen Durchsatz und hochgradig gleichzeitige Arbeitslasten ausführt. Letztes Mal haben Sie von einem geschäftlichen Problem erfahren, mit dem das FeatureBase-Team konfrontiert war: Es stellte fest, dass die Zahl der Kunden während des Verkaufszyklus zurückging, dass ihre Datenerfassung jedoch nicht über die erforderlichen Messungen verfügte, um zu untersuchen, wann und warum dies geschah. Der erste Schritt zur Bewältigung dieses Problems bestand in der Zusammenarbeit zwischen Vertriebs-, Marketing- und Führungsteams, um zu ermitteln, welche Daten sie benötigen, um zu verstehen, wann Kunden zurückgehen. Anschließend könnten sie diese Erkenntnisse nutzen, um diese Probleme für zukünftige Verkäufe zu untersuchen und anzugehen. In dieser Lektüre konzentrieren Sie sich auf die Datenbanktools, die FeatureBase zum Sammeln von Daten zur Überwachung und Berichterstellung verwendet.

Feature-orientierte Datenbanken
Während dieses Programms haben Sie verschiedene Datenbanktechnologien kennengelernt, die Pipelinesysteme verwenden, um Daten aufzunehmen, umzuwandeln und an Zieldatenbanken zu liefern. Dieses Setup ist in vielen verschiedenen Organisationen recht verbreitet, und als BI-Experte arbeiten Sie häufig mit Pipelines. Es gibt jedoch auch andere Arten von Datenbanksystemen, die unterschiedliche Technologien verwenden, um Daten für Benutzer zugänglich und nutzbar zu machen.
FeatureBase ist ein Beispiel für eine alternative Lösung zu herkömmlichen Datenbanken – es basiert auf Bitmaps, einem Format, das Daten als Rohmerkmale speichert. Um Vorhersagemodelle zu erstellen, ist die KI auf die merkmalsorientierte Datenbank angewiesen (und nicht umgekehrt), um Muster zu finden, die als Entscheidungshilfe dienen können. Diese Modelle werden mit messbaren Datenpunkten oder Funktionen gefüttert, die dabei helfen, zu lernen, wie die Daten im Laufe der Zeit effektiver analysiert werden können. Merkmalsorientierte Datenbanken bieten einen alternativen Ansatz zur Datenvorbereitung, indem sie im ersten Schritt die Merkmalsextraktion automatisieren. Der funktionsorientierte Ansatz ermöglicht Echtzeitanalysen und KI-Initiativen, da die Daten oder „Funktionen“ bereits in einem modellbereiten Datenformat vorliegen, das im gesamten Unternehmen sofort zugänglich und wiederverwendbar ist, ohne dass ein erneutes Kopieren oder Vorbereiten erforderlich ist -Verfahren.
Hier ist ein Beispiel für dieses System: Stellen Sie sich vor, Sie würden versuchen, eine Tierart anhand von Merkmalen vorherzusagen. Menschen hätten eine Liste von Merkmalen, über die sie nachdenken könnten: zum Beispiel Flügel, Schnauzen oder die Anzahl der Beine. Aber diese Merkmale sind auf diese Weise nicht umsetzbar – aber wenn sie in Features wie „has_wings“ oder „has_4_legs“ mit Ja- oder Nein-Werten, die als 1 oder 0 codiert sind, umgewandelt werden, können sie in ein Modell eingespeist und schneller verarbeitet werden. Aus diesem Grund basiert FeatureBase auf Bitmaps. Die Arrays aus Einsen und Nullen können von Maschinen und Modellen leicht verarbeitet werden.

Feinabstimmungsfunktionen
In der letzten Lektüre haben Sie mitverfolgt, wie die FeatureBase-Führung darüber nachdachte, wie sie ihre ultimative Frage angehen sollte: Warum brechen Kunden während des Verkaufszyklus ab?
Zu diesem Zeitpunkt im Projektzyklus verfügte das Team nicht über integrierte Kennzahlen in seinem System, um herauszufinden, wann Kunden den Verkaufsprozess nicht abschlossen, was für die Untersuchung der Gründe, warum Kunden abwanderten, von entscheidender Bedeutung war. Nachdem das Team festgestellt hatte, was seinem System fehlte, kodierte es diese neuen Funktionen in den Erfassungsprozess – es stellte seinen ursprünglichen Verkaufstrichter mit neuen Attributen über Kunden in jeder Phase des Verkaufszyklus wieder her. Diese neuen Funktionen wurden in ihr Datenbankmodell eingespeist, das mit dem Training zur Erkennung von Mustern begann, sodass sie sofort Erkenntnisse aus ihrem Datenpool ziehen konnten.
Eines der Attribute, die sie dem Datenerfassungsprozess hinzufügten, verfolgte genau, wann Kunden abstiegen. Sie stellten fest, dass die meisten Kunden, die den Verkauf nicht abgeschlossen hatten, während der technischen Validierungsphase abbrachen. An diesem Punkt würde das FeatureBase-Team FeatureBase im System des Kunden einrichten, damit dieser das Produkt selbst ausprobieren kann. Das Team erkannte, dass dies die kritische Phase war, die es für weitere Untersuchungen brauchte. Sie stellten die Theorie auf, dass die Kunden die technische Validierungsphase nicht zuversichtlich verließen, ob sie diese neue Technologie übernehmen könnten. Sie fragten sich auch, ob Kunden Bedenken hinsichtlich der Zuverlässigkeit und Stabilität des Produkts hätten, da FeatureBase ihr aktuelles, noch funktionierendes Datenbanksystem ersetzen würde. Um dies besser zu verstehen, müssten sie die zu diesem Zeitpunkt gesammelten Kundendaten in ihrem Dashboard untersuchen.
Der nächste Schritt
Als BI-Experte arbeiten Sie möglicherweise mit einer Vielzahl von Datenbanktechnologien, die mit Pipeline-Systemen verbunden sind, wie etwa traditionellere zeilenbasierte Technologien und neuere Alternativen wie FeatureBase. Wenn Sie Ihre Tools und deren Funktionsweise verstehen, können Sie sich auf das Wesentliche konzentrieren: Ihrem Team Zugriff auf die benötigten Antworten zu geben. Während sie ihr Problem weiter untersuchten, stellte das FeatureBase-Team fest, dass die meisten Kunden, die den Verkaufsprozess nicht abgeschlossen hatten, in der technischen Validierungsphase abfielen.
Dies ist der Punkt, an dem FeatureBase in der Datenumgebung des Kunden implementiert wurde, um festzustellen, ob es für ihn tatsächlich funktionsfähig war. Auf diese Weise kann das FeatureBase-Team den Nutzen von FeatureBase demonstrieren und beweisen, dass es sich um eine praktikable Lösung für die Anforderungen eines Kunden handelt.
Das Team ging davon aus, dass viele Kunden zwar von den Möglichkeiten des Dienstes begeistert waren, sie jedoch Bedenken hinsichtlich der Akzeptanz und Zuverlässigkeit des Dienstes für ihr Unternehmen hatten. Doch bevor das Team diese Theorie bestätigen oder auf der Grundlage dieser möglichen Antwort Entscheidungen treffen kann, müsste es in der Lage sein, Dashboard-Berichte zu untersuchen und ihre Metriken eingehend zu untersuchen. Darauf werden Sie sich konzentrieren, wenn Sie das nächste Mal zu dieser Fallstudie zurückkehren!
Entdecken Sie Projektszenarien am Ende des Kurses 2
Überblick
Wenn Sie mit strukturiertem Denken an ein Projekt herangehen, werden Sie häufig feststellen, dass bestimmte Schritte in einer bestimmten Reihenfolge ausgeführt werden müssen. Die Abschlussprojekte im Google Business Intelligence-Zertifikat wurden unter diesem Gesichtspunkt konzipiert. Die in jedem Kurs vorgestellten Herausforderungen stellen einen einzelnen Meilenstein innerhalb eines gesamten Projekts dar, basierend auf den in diesem Kurs erlernten Fähigkeiten und Konzepten.

Das Zertifikatsprogramm ermöglicht es Ihnen, aus verschiedenen Arbeitsplatzszenarien zu wählen, um die Abschlussprojekte abzuschließen: das Fahrradverleihunternehmen Cyclistic oder Google Fiber. Jedes Szenario bietet Ihnen die Möglichkeit, Ihre Fähigkeiten zu verfeinern und Artefakte zu erstellen, die Sie in einem Online-Portfolio auf dem Arbeitsmarkt teilen können.
Unabhängig davon, für welches Szenario Sie sich entscheiden, erlernen Sie ähnliche Fähigkeiten, müssen jedoch für jeden Kurs mindestens ein Abschlussprojekt abschließen, um Ihr Google Business Intelligence-Zertifikat zu erhalten. Um ein zusammenhängendes Erlebnis zu gewährleisten, wird empfohlen, für jedes Abschlussprojekt das gleiche Szenario zu wählen. Wenn Sie beispielsweise das Szenario „Radfahren“ für Kurs 1 ausgewählt haben, empfehlen wir, dasselbe Szenario auch in Kurs 2 und 3 abzuschließen. Wenn Sie jedoch an mehr als einem Arbeitsplatzszenario interessiert sind oder sich eine größere Herausforderung wünschen, können Sie gerne mehr als ein Abschlussprojekt durchführen. Durch den Abschluss mehrerer Projekte erhalten Sie zusätzliche Übungen und Beispiele, die Sie potenziellen Arbeitgebern mitteilen können.
Kurs 2 Projektszenarien am Ende des Kurses
Fahrrad-Sharing

Hintergrund:
In diesem fiktiven Arbeitsplatzszenario hat sich das imaginäre Unternehmen Cyclistic mit der Stadt New York zusammengetan, um gemeinsam genutzte Fahrräder bereitzustellen. Derzeit gibt es in ganz Manhattan und den angrenzenden Bezirken Fahrradstationen. Kunden können an diesen Standorten Fahrräder mieten, um bequem zwischen den Stationen hin- und herzufahren.
Szenario:
Sie sind ein neu eingestellter BI-Experte bei Cyclistic. Das Kundenwachstumsteam des Unternehmens erstellt einen Geschäftsplan für das nächste Jahr. Sie möchten verstehen, wie ihre Kunden ihre Fahrräder nutzen. Ihre oberste Priorität besteht darin, die Kundennachfrage an verschiedenen Bahnhofsstandorten zu ermitteln. Zuvor haben Sie Informationen aus Ihren Besprechungsnotizen gesammelt und wichtige Projektplanungsdokumente ausgefüllt. Jetzt sind Sie bereit für den nächsten Teil Ihres Projekts!
Herausforderung für Kurs 2:
Verwenden Sie Projektplanungsdokumente, um wichtige Kennzahlen und Dashboard-Anforderungen zu identifizieren
Beobachten Sie Stakeholder in Aktion, um besser zu verstehen, wie sie Daten nutzen
Sammeln und kombinieren Sie die erforderlichen Daten
Entwerfen Sie Berichtstabellen, die auf Tableau hochgeladen werden können, um das endgültige Dashboard zu erstellen
Hinweis: Die Geschichte sowie alle dargestellten Namen, Charaktere und Vorfälle sind frei erfunden. Eine Identifizierung mit tatsächlichen Personen (lebend oder verstorben) ist nicht beabsichtigt oder sollte abgeleitet werden. Die in diesem Projekt geteilten Daten wurden für pädagogische Zwecke erstellt.
Google Fiber

Hintergrund:
Google Fiber versorgt Menschen und Unternehmen mit Glasfaser-Internet. Derzeit beantwortet das Kundendienstteam in seinen Callcentern Anrufe von Kunden in seinen etablierten Servicegebieten. In diesem fiktiven Szenario möchte das Team Trends bei wiederholten Anrufen untersuchen, um die Anzahl der Anrufe von Kunden zu reduzieren, damit ein Problem gelöst werden kann.
Szenario:
Sie führen derzeit ein Vorstellungsgespräch für eine BI-Stelle im Callcenter-Team von Google Fibre. Im Rahmen des Interviewprozesses werden Sie gebeten, ein Dashboard-Tool zu entwickeln, das es ihnen ermöglicht, Trends bei wiederholten Anrufen zu erkunden. Das Team muss verstehen, wie oft Kunden nach ihrer ersten Anfrage den Kundendienst anrufen. Dies wird der Führung helfen, zu verstehen, wie effektiv das Team Kundenfragen beim ersten Mal beantworten kann. Zuvor haben Sie Informationen aus Ihren Besprechungsnotizen gesammelt und wichtige Projektplanungsdokumente ausgefüllt. Jetzt sind Sie bereit für den nächsten Teil Ihres Projekts!
Herausforderung für Kurs 2:
Verwenden Sie Projektplanungsdokumente, um wichtige Kennzahlen und Dashboard-Anforderungen zu identifizieren
Erwägen Sie die besten Tools zur Ausführung Ihres Projekts
Sammeln und kombinieren Sie die erforderlichen Daten
Entwerfen Sie Berichtstabellen, die auf Tableau hochgeladen werden können, um das endgültige Dashboard zu erstellen
Die zentralen Thesen
In Kurs 2, „Der Weg zu Erkenntnissen: Datenmodelle und Pipelines“, haben Sie sich darauf konzentriert, zu verstehen, wie Daten in einer BI-Umgebung gespeichert, transformiert und bereitgestellt werden.
Fähigkeiten in Kurs 2:
Daten kombinieren und transformieren
Identifizieren Sie wichtige Kennzahlen
Erstellen Sie Zieltabellen
Üben Sie den Umgang mit BI-Tools
Ergebnisse des Abschlussprojekts von Kurs 2:
Die notwendigen Zieltabellen
Nachdem Sie nun diesen Schritt Ihres Projekts abgeschlossen und die Zieltabellen entwickelt haben, können Sie im nächsten Kurs an Ihrem endgültigen Dashboard arbeiten!
Überblick über das Arbeitsplatzszenario von Kurs 2: Radfahrer

Zuvor haben Sie begonnen, mit einem fiktiven Fahrradverleihunternehmen, Cyclistic, zusammenzuarbeiten, um dessen Team wichtige Business-Intelligence-Erkenntnisse bereitzustellen. Am Ende des letzten Kurses haben Sie sich mit Stakeholdern beraten, um Projektplanungsdokumente zu entwickeln, die ihre Bedürfnisse und Erwartungen darlegen. Die Strategie- und Planungsdokumente sind der Schlüssel zum Verständnis wichtiger Details dieses Projekts. Sie sollten daher sicherstellen, dass Sie diesen Schritt abgeschlossen haben, bevor Sie fortfahren. Die Musterdokumente finden Sie hier:Aktivitätsbeispiel: Vervollständigen Sie die Business-Intelligence-Projektdokumente für Cyclistic.
Nutzen Sie diese Beispiele, um sicherzustellen, dass Ihre eigenen Projektplanungsdokumente ausreichend detailliert sind, um mit dem nächsten Teil des Projekts fortfahren zu können.
Als Nächstes werden Sie auf früheren Arbeiten aufbauen und Daten aus den Tabellen, die Sie für dieses Projekt erhalten haben, in einer Berichtstabelle zusammenfassen, die Sie zur Entwicklung eines Dashboards verwenden, das Sie mit Stakeholdern teilen können. Die Aktivitäten führen Sie durch das Hochladen der Daten in Ihren eigenen Projektbereich, die Verwendung von SQL-Code in Dataflow oder BigQuery, die Beobachtung, wie Stakeholder mit Daten interagieren, und die Fertigstellung einer Berichtstabelle zur Verwendung für das Dashboard. Sie erhalten ein Musterprojekt zur Überprüfung, damit Sie Ihre Arbeit überprüfen und mit der Iteration Ihres eigenen Projekts fortfahren können.
Dieser nächste Schritt in Ihrem Projekt bietet mehr Möglichkeiten, zusätzliche Arbeitsplatzbeispiele zu erstellen, die Sie mit potenziellen Arbeitgebern teilen können, um Ihre BI-Fähigkeiten und -Kenntnisse zu demonstrieren. Dies ist auch eine großartige Gelegenheit, die Fähigkeiten, die Sie bisher erlernt haben, zu üben.
Die zentralen Thesen
Das Abschlussprojekt dient dazu, dass Sie die Kurskompetenzen in einem fiktiven Arbeitsplatzszenario üben und anwenden. Wenn Sie das Abschlussprojekt jedes Kurses abschließen, erhalten Sie Arbeitsbeispiele, die Ihr Portfolio erweitern und Ihre Fähigkeiten für zukünftige Arbeitgeber präsentieren.
Zyklische Datensätze
Jetzt bereiten Sie sich darauf vor, die nächsten Schritte mit Ihrem Abschlussprojekt für Kurs 2 zu unternehmen. Um mit den Cyclistic-Projektdaten arbeiten zu können, müssen Sie die entsprechenden öffentlichen Datensätze suchen und die Postleitzahlentabelle, die Ihr Kollege freigegeben hat, in Ihren BigQuery-Projektbereich hochladen. Diese Lektüre wird Sie durch diesen Prozess führen. Sobald Sie diese Lektüre abgeschlossen haben, sind Sie bereit für die bevorstehenden Aktivitäten und die Bereitstellung wichtiger Erkenntnisse für Ihre Stakeholder.
Für dieses Abschlussprojekt verwenden Sie zwei öffentliche Datensätze, die in den öffentlichen Daten vorhanden sind, die im Explorer-Bereich Ihrer Konsole verfügbar sind:
Darüber hinaus müssen Sie die Datei hochladenPostleitzahlen-TabelleIhr Kollege hat es Ihnen mitgeteilt.
Auf BigQuery hochladen
Navigieren Sie zunächst zu Ihrer BigQuery-Konsole. Gehen Sie zur BigQuery-Startseite oder navigieren Sie zudie Konsole.

Durchsuchen Sie die öffentlichen Datensätze und zeigen Sie sie in der Vorschau an, indem Sie die Suchleiste im Bereich „Erkunden“ Ihrer Konsole verwenden:

Diese Datensätze stehen Ihnen bereits zum Abfragen zur Verfügung, es kann jedoch hilfreich sein, sich die Tabellen anzusehen, bevor Sie mit der Arbeit damit beginnen. Finden Sie alle drei Datensätze, indem Sie in der Suchleiste nach dem entsprechenden Datensatznamen suchen:
new_york_citibike
geo_us_boundaries
noaa_gsod
Nachdem Sie sich mit den öffentlichen Daten vertraut gemacht haben, laden Sie den Postleitzahlendatensatz hoch. Speichern Sie das Google Sheet entweder als CSV-Datei auf Ihrem Gerät oder laden Sie es in Ihren eigenen Drive-Bereich herunter.
Klicken Sie im Explorer-Menübereich auf die Schaltfläche + DATEN HINZUFÜGEN. Dadurch wird das Menü „Daten hinzufügen“ geöffnet.

Wählen Sie hier „Lokale Datei“ aus, um die CSV-Datei hochzuladen, oder „Google Cloud Storage“, um das Blatt aus Ihrem persönlichen Drive auszuwählen. Wie auch immer Sie die Datei hinzufügen, Sie müssen die erforderlichen Felder im Menü „Tabelle erstellen“ ausfüllen. Falls Sie dies noch nicht getan haben, werden Sie im Menü „Tabelle erstellen“ auch aufgefordert, einen Datensatz für diese Tabelle zu erstellen.

Wählen Sie NEUEN DATENSATZ ERSTELLEN und benennen Sie den Datensatz entsprechend für dieses Projekt. Sie können den Datenspeicherort auf dem Standardwert belassen. Wenn Sie diese Informationen vollständig ausgefüllt haben, klicken Sie auf Datensatz erstellen.
Füllen Sie nun die Informationen für Ihren Tisch aus. Benennen Sie Ihre Tabelle entsprechend Ihrem Projekt und wählen Sie unter Dateityp CSV aus. Wählen Sie abschließend „Automatisch erkennen“ für das Schema aus. Wenn Sie fertig sind, wählen Sie Tabelle erstellen. Die neue Tabelle sollte kurz unter Ihrem Datensatz im Explorer-Bereich angezeigt werden.

Erkunden Sie von hier aus das Schema, zeigen Sie eine Vorschau der Daten an und machen Sie sich mit dieser Tabelle vertraut. Sobald Sie diesen Datensatz hochgeladen haben, können Sie mit Ihrem Projekt fortfahren!
Übersicht über das Arbeitsplatzszenario von Kurs 2: Google Fiber

Zuvor haben Sie ein Vorstellungsgespräch mit dem Kunden-Callcenter-Team von Google Fiber geführt, einem Anbieter von Glasfaser-Internet. Ihre Interviewer haben Sie gebeten, ein Musterprojekt durchzuführen, das auf der Arbeit ihres Business-Intelligence-Teams basiert. Am Ende des letzten Kurses haben Sie sich mit Stakeholdern beraten, um Projektplanungsdokumente zu entwickeln, die ihre Bedürfnisse und Erwartungen darlegen. Die Strategie- und Planungsdokumente sind der Schlüssel zum Verständnis wichtiger Details dieses Projekts. Sie sollten daher sicherstellen, dass Sie diesen Schritt abgeschlossen haben, bevor Sie fortfahren. Die Musterdokumente finden Sie hier:Aktivitätsbeispiel: Vervollständigen Sie die Business-Intelligence-Projektdokumente für Google Fiber. Nutzen Sie diese Beispiele, um sicherzustellen, dass Ihre eigenen Dokumente ausreichend detailliert sind, um mit dem nächsten Teil des Projekts fortfahren zu können.
Als nächstes werden Sie auf früheren Arbeiten aufbauen und Daten aus den Tabellen in einer Berichtstabelle kombinieren, die Sie zur Entwicklung eines Dashboards für Stakeholder verwenden werden. Die Aktivitäten führen Sie durch das Hochladen der Daten in Ihren eigenen Projektbereich, die Verwendung von SQL-Code in Dataflow oder BigQuery, die Beobachtung, wie Stakeholder mit Daten interagieren, und die Fertigstellung einer Berichtstabelle zur Verwendung für das Dashboard. Sie erhalten ein Musterprojekt zur Überprüfung, damit Sie Ihre Arbeit überprüfen und mit der Iteration Ihres eigenen Projekts fortfahren können.
Dieser nächste Schritt in Ihrem Projekt bietet mehr Möglichkeiten, zusätzliche Arbeitsplatzbeispiele zu erstellen, die Sie mit potenziellen Arbeitgebern teilen können, um Ihre BI-Fähigkeiten und -Kenntnisse zu demonstrieren. Dies ist auch eine großartige Gelegenheit, die Fähigkeiten, die Sie bisher erlernt haben, zu üben.
Die zentralen Thesen
Das Abschlussprojekt dient dazu, dass Sie die Kurskompetenzen in einem fiktiven Arbeitsplatzszenario üben und anwenden. Wenn Sie das Abschlussprojekt jedes Kurses abschließen, erhalten Sie Arbeitsbeispiele, die Ihr Portfolio erweitern und Ihre Fähigkeiten für zukünftige Arbeitgeber präsentieren.
Google Fiber-Datensätze
Jetzt bereiten Sie sich darauf vor, die nächsten Schritte mit Ihrem Abschlussprojekt für Kurs 2 zu unternehmen. Um mit den Google Fiber-Daten arbeiten zu können, müssen Sie Ihre Daten in den entsprechenden Arbeitsbereich hochladen. Wenn Sie BigQuery oder Dataflow verwenden möchten, laden Sie die Dateien in Ihren Projektbereich hoch, um ihnen beizutreten. Da diese Daten außerdem bereits sauber sind, können Sie diese Datensätze direkt in Tableau verbinden und dort zusammenführen.
Ihre Interviewer haben drei CSV-Dateien bereitgestellt:
Auf BigQuery hochladen
Navigieren Sie zunächst zu Ihrer BigQuery-Konsole. Gehen Sie zur BigQuery-Startseite oder gehen Sie direkt zudie Konsole.

Klicken Sie im Explorer-Menübereich auf die Schaltfläche + DATEN HINZUFÜGEN, um das Menü „Daten hinzufügen“ zu öffnen.

Wählen Sie hier „Lokale Datei“ aus, um die CSV-Datei hochzuladen, oder „Google Cloud Storage“, um das Blatt aus Ihrem persönlichen Drive auszuwählen. Wie auch immer Sie die Datei hinzufügen, Sie müssen die erforderlichen Felder im Menü „Tabelle erstellen“ ausfüllen. Falls Sie dies noch nicht getan haben, werden Sie im Menü „Tabelle erstellen“ auch aufgefordert, einen Datensatz für diese Tabelle zu erstellen.

Wählen Sie NEUEN DATENSATZ ERSTELLEN und benennen Sie den Datensatz entsprechend für dieses Projekt. Belassen Sie den Datenspeicherort auf der Standardeinstellung. Wenn Sie diese Informationen vollständig ausgefüllt haben, klicken Sie auf Datensatz erstellen.
Füllen Sie nun die Informationen für Ihren Tisch aus. Benennen Sie Ihre Tabelle entsprechend Ihrem Projekt und wählen Sie unter Dateityp CSV aus. Wählen Sie abschließend „Automatisch erkennen“ für das Schema aus. Wenn Sie fertig sind, wählen Sie Tabelle erstellen. Die neue Tabelle sollte kurz unter Ihrem Datensatz im Explorer-Bereich angezeigt werden.

Erkunden Sie von hier aus das Schema, zeigen Sie eine Vorschau der Daten an und machen Sie sich mit dieser Tabelle vertraut. Sobald Sie diesen Datensatz hochgeladen haben, können Sie mit Ihrem Projekt fortfahren!
Führen Sie Google Fiber-Datensätze in Tableau zusammen
Sie haben viele verschiedene Tools entdeckt, die es Business-Intelligence-Experten ermöglichen, Lösungen für Stakeholder zu entwerfen. Manchmal können Sie den Großteil der Arbeit sogar mit einem einzigen Werkzeug erledigen. Jetzt werden Sie dies erleben, wenn Sie weiter an Ihrem Abschlussprojekt arbeiten.
In einer Folge-E-Mail der Interviewer von Google Fibre teilte Ihnen Minna, die leitende BI-Analystin, mit, dass einige Befragte direkt in Tableau daran gearbeitet haben, die Tabellen zusammenzuführen, da die Spalten in allen Tabellen konsistent sind. In dieser Lektüre erfahren Sie, wie Sie Tabellen direkt in Tableau zusammenführen, um die Dashboard-Erstellung vorzubereiten. Als BI-Experte ist es eine nützliche Fähigkeit, verschiedene Tools nutzen zu können, um dasselbe Ziel zu erreichen. Dies ist nur eine Methode, mit der Sie diese Datensätze zusammenführen können. Wenn Sie für diesen Teil des Projekts lieber nur mit BigQuery arbeiten möchten, können Sie mit dieser optionalen Lektüre fortfahren.
Datenquellen mit Tableau verbinden
Um Tabellen beim Hochladen in Tableau zusammenzuführen, verbinden Sie zunächst die erste Datenquelle. Wählen Sie das Dropdown-Menü „Daten“ und dann „Neue Datenquelle“ aus.

Dadurch wird ein Popup-Menü geöffnet, in dem Sie aufgefordert werden, auszuwählen, welche Datenquelle Sie verbinden möchten. Da Sie mit CSV-Dateien arbeiten, wählen Sie die Option Textdatei.

Sobald Sie Ihre erste Datenquelle verbunden haben, fügen Sie die beiden anderen Dateien auf der Seite „Datenquelle“ hinzu. Laden Sie die beiden CSV-Dateien in Ihre Arbeitsmappe hoch. Nachdem Sie sie verbunden haben, werden sie im Menü „Dateien“ angezeigt, sodass Sie die Tabellen in den Bereich „Datenverbindungen“ ziehen können. Ziehen Sie zuerst market_1 in den Bereich.
Ziehen Sie dann „market_2“ unter das Symbol „market_1“, bis die Option „Union“ angezeigt wird.

Dadurch werden die Tabellen „market_1“ und „market_2“ zusammengeführt. Wiederholen Sie diesen Vorgang als Nächstes für die Tabelle „market_3“, um die Zusammenführung aller drei Tabellen abzuschließen. Benennen Sie die Datenquelle von „market_1“ in „Data“ um und beginnen Sie direkt mit der Arbeit mit den Spalten! In dieser Phase können Sie entscheiden, einige Spalten umzubenennen und mit der Erstellung vorläufiger Tabellen zu beginnen. Beispielsweise könnten Sie stattdessen die Spalten „Contacts_N_#“ in „Day #“ umbenennen:

Dieser Prozess macht Ihr endgültiges Dashboard für Stakeholder, die nicht unbedingt mit Quelldaten vertraut sind, leichter lesbar und verständlich.
Die zentralen Thesen
Bei der Erstellung von BI-Lösungen gibt es oft viele mögliche Tools, die Sie nutzen können. Manchmal können Sie den Großteil der Arbeit sogar mit einem einzigen Werkzeug erledigen. Dies ist nur eine Möglichkeit, Ihre Daten dorthin zu bringen, wo sie sein sollen – schon bald können Sie mit der Arbeit an Ihrem endgültigen Dashboard beginnen!